

 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สวัสดีครับ ผู้เจริญทุกท่าน
ในยุคที่ AI และ LLMs อย่าง ChatGPT กลายเป็นส่วนหนึ่งในชีวิตเรา หลายคนน่าจะเคยได้ยินคำว่า “Vector Database” ผ่านหูมาบ้าง แต่ก็อาจจะยังสงสัยว่า “เอ๊ะ… มันคืออะไรกันแน่?” แล้วมันต่างจากฐานข้อมูลที่เราคุ้นเคยอย่าง SQL หรือ NoSQL ยังไง?
บทความนี้จะพาทุกคนไปทำความรู้จักกับ Vector Database แบบง่ายที่สุด พร้อมตัวอย่าง Demo ที่เห็นภาพชัดเจน ตั้งแต่พื้นฐานไปจนถึงการนำไปใช้กับงานค้นหารูปภาพกันเลยครับ
Vector Database คืออะไร แตกต่างกับ DB อย่าง SQL, No SQL อย่างไร ?
ถ้าจะเล่าเรื่องนี้ให้ง่าย ให้ลองจินตนาการรถึง ห้องสมุด ครับ
- SQL Database: เหมือนห้องสมุดที่จัดหนังสือตาม รหัสหนังสือ หรือ ชื่อผู้แต่ง แบบเป๊ะๆ คุณต้องรู้ว่าอยากได้เล่มไหน (เช่น “หาหนังสือรหัส 005.133”) ถึงจะเจอ มันแม่นยำมาก แต่คุณจะหาหนังสือที่มี “เนื้อหาคล้ายๆ กัน” ไม่ได้เลย
- NoSQL Database: เหมือนห้องสมุดที่จัดหนังสือเป็น ชั้นๆ ตามหมวดหมู่ (เช่น ชั้นนิยาย, ชั้นประวัติศาสตร์) แต่ละเล่มอาจจะมีข้อมูลไม่เหมือนกัน (บางเล่มปกแข็ง, บางเล่มมีภาพประกอบ) มันยืดหยุ่นมาก เหมาะกับการเก็บข้อมูลหลากหลาย แต่ก็ยังค้นหาตาม “ความรู้สึก” หรือ “แนวคิด” ของหนังสือไม่ได้อยู่ดี
- Vector Database: นี่แหละครับ คือห้องสมุดแบบใหม่! มันไม่ได้จัดหนังสือตามชื่อหรือหมวดหมู่ แต่จัดตาม “ความหมาย” และ “แนวคิด” ของหนังสือแต่ละเล่ม หนังสือที่มีเนื้อหาคล้ายกันจะถูกวางไว้ใกล้ๆ กัน ต่อให้ชื่อเรื่องหรือผู้แต่งจะต่างกันโดยสิ้นเชิง คุณสามารถเดินไปหยิบหนังสือเล่มหนึ่งแล้วบอกบรรณารักษ์ว่า “ขอหนังสือที่มีเนื้อหาคล้ายๆ เล่มนี้หน่อย” บรรณารักษ์ก็จะพาคุณไปโซนที่มีหนังสือแนวเดียวกันได้ทันที
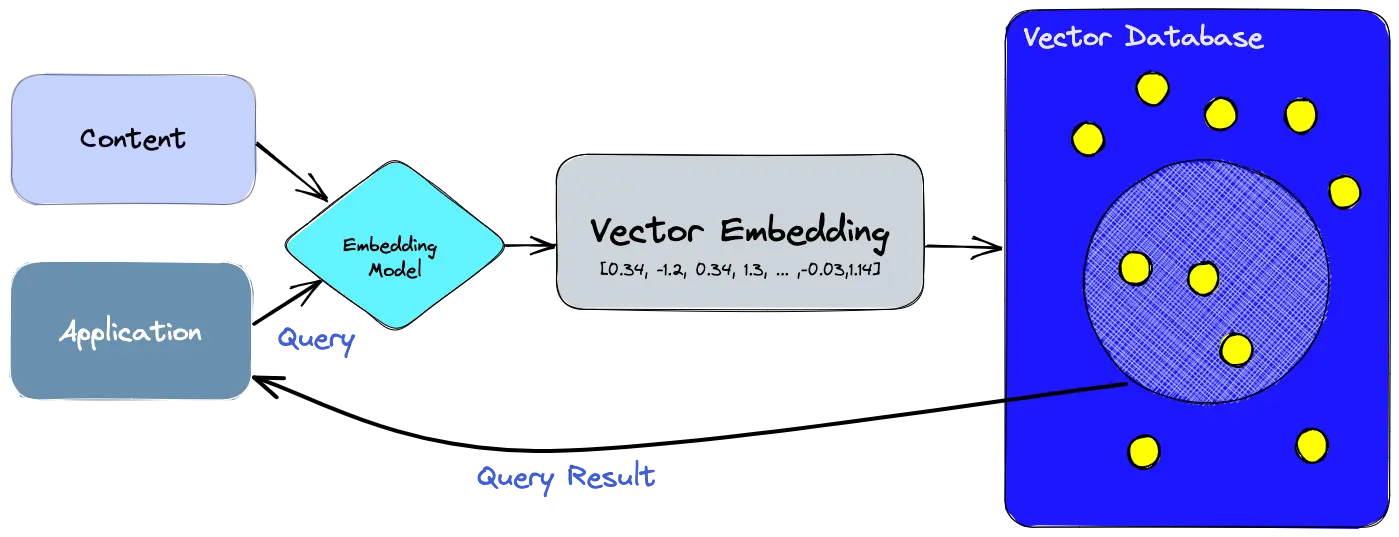
ref: https://www.pinecone.io/learn/vector-database/
Vector Database คือฐานข้อมูลชนิดพิเศษที่ถูกออกแบบมาเพื่อ เก็บและค้นหา “Vector Embeddings” โดยเฉพาะ
แล้ว Vector Embeddings คืออะไร?
- มันคือการ แปลงข้อมูลที่ซับซ้อน (เช่น ข้อความ, รูปภาพ, เสียง) ให้กลายเป็น ชุดตัวเลขทางคณิตศาสตร์ (ที่เราเรียกว่า เวกเตอร์) ซึ่งชุดตัวเลขนี้จะแทน “ความหมาย” หรือ “แก่นแท้” ของข้อมูลนั้นๆ
- ตัวอย่างเช่น:
- คำว่า “กษัตริย์” อาจถูกแปลงเป็นเวกเตอร์ [0.9, 0.8, 0.2, …]
- คำว่า “ราชินี” ก็จะมีเวกเตอร์ที่ “ใกล้เคียง” กับ “กษัตริย์” มาก เช่น [0.88, 0.82, 0.21, …]
- ในขณะที่คำว่า “กล้วย” จะมีเวกเตอร์ที่อยู่ “ห่างไกล” ออกไปเลย เช่น [0.1, 0.3, 0.9, …]
หัวใจสำคัญของ Vector Database คือการทำ Similarity Search (การค้นหาความคล้ายคลึง) มันไม่ได้หาข้อมูลที่ตรงกันเป๊ะๆ (Exact Match) แต่หาข้อมูลที่มี “ความหมาย” ใกล้เคียงกันที่สุดครับ
| คุณสมบัติ | SQL Database (เช่น MySQL, PostgreSQL) | NoSQL Database (เช่น MongoDB, Redis) | Vector Database (เช่น Pinecone, Milvus, Qdrant) |
|---|---|---|---|
| ข้อมูลที่จัดเก็บ | ข้อมูลมีโครงสร้าง (Structured Data) เก็บในรูปแบบตาราง (แถว, คอลัมน์) ที่ชัดเจนและตายตัว | ข้อมูลกึ่งโครงสร้าง/ไม่มีโครงสร้าง (Semi-structured/Unstructured) เช่น เอกสาร JSON, Key-Value, Graph มีความยืดหยุ่นสูง | Vector Embeddings ซึ่งเป็นชุดตัวเลขที่แปลงมาจากข้อมูลไม่มีโครงสร้าง (ข้อความ, รูปภาพ, เสียง) |
| วิธีการ Query/ค้นหา | ค้นหาแบบตรงตัว (Exact Match) ใช้ภาษา SQL เพื่อหาข้อมูลที่ตรงตามเงื่อนไขเป๊ะๆ เช่น WHERE name = ‘โต๊ะ’ | ค้นหาตาม Key หรือ Filter ในข้อมูลที่มีความยืดหยุ่น เช่น หาเอกสารทั้งหมดที่มี category: ‘furniture’ | ค้นหาความคล้ายคลึง (Similarity Search) หาเวกเตอร์ที่อยู่ “ใกล้” กับเวกเตอร์ที่เราใช้ค้นหามากที่สุด |
| ตัวอย่างคำสั่งค้นหา | SELECT * FROM products WHERE name = 'เก้าอี้ไม้'; | db.products.find({ "tags": "wooden" }); | ”หารูปภาพที่คล้ายกับรูปเก้าอี้ตัวนี้ที่สุด” หรือ “หาบทความที่มีความหมายใกล้เคียงกับประโยคนี้” |
| เหมาะกับงานประเภท | ระบบธนาคาร, ระบบสินค้าคงคลัง, งานที่ต้องการความถูกต้องของข้อมูลสูง (Transactional) | Big Data, แอปโซเชียลมีเดีย, Content Management, งานที่ต้องการความเร็วและความยืดหยุ่นในการขยายระบบ | AI/Machine Learning, ระบบแนะนำสินค้า/หนัง (Recommendation), ค้นหาด้วยภาพ, Semantic Search, Chatbot ที่ใช้เทคนิค RAG |
| จุดเด่น | ความน่าเชื่อถือและความถูกต้องของข้อมูล (ACID Compliance) | ความยืดหยุ่น, ขยายระบบง่าย (Scalability), ประสิทธิภาพสูง | เข้าใจความหมายและบริบทของข้อมูล, ค้นหาสิ่งที่เกี่ยวข้องกันได้แม้ใช้คำไม่ตรงกัน |
แล้ว Elasticsearch เป็น Vector Database ไหม ?
ทีนี้หลายคนน่าจะรู้จัก Elasticsearch กันดี และพอเห็นเว็บจัดอันดับ Vector DB https://db-engines.com/en/ranking/vector+dbms ก็จะเห็นว่า Elasticsearch อยู่อันดับ 1 เลย ก็คงสงสัยกันว่า “ตกลงแล้ว Elasticsearch มันเป็น Vector Database ด้วยหรือเปล่า?”
คำตอบคือ “ไม่เชิงครับ”
- Elasticsearch ไม่ใช่ “Native” หรือ “Purpose-built” Vector Database แต่เป็น Search Engine ที่ทรงพลังซึ่ง “เพิ่มความสามารถ” ในการทำ Vector Search เข้ามาทีหลัง
- ความแตกต่างอยู่ที่ “สถาปัตยกรรมหลัก” (Core Architecture) ที่สร้างมาเพื่อวัตถุประสงค์ที่ต่างกันโดยสิ้นเชิง
- Elasticsearch จะใช้ function “Vector Search” ได้ ก็ต่อเมื่อข้อมูลที่คุณต้องการค้นหาด้วยวิธีนี้ ถูกจัดเก็บอยู่ในรูปแบบ
dense_vectorเท่านั้น - ถ้าข้อมูลเป็น Text ธรรมดา = Elasticsearch จะใช้กลไกดั้งเดิมของมันคือ Full-Text Search ผ่าน Inverted Index เพื่อค้นหา มันจะดูว่าคำที่คุณค้นหานั้นปรากฏในเอกสารไหนบ้าง
- ถ้าข้อมูลเป็น Vector Embedding = Elasticsearch จะใช้กลไกใหม่ของมันคือ Vector Search (kNN Search) ผ่าน ANN Index (เช่น HNSW) เพื่อค้นหาเวกเตอร์ที่มีความหมายใกล้เคียงที่สุด
ซึ่ง Elasticsearch มันสามารถเก็บข้อมูลได้หลากหลายประเภทในการทำ Hybrid Search ได้ เช่น แบบด้านล่างนี้
{ "product_name": "Nike Air Zoom Pegasus 41 Blue", // <-- Text, ใช้ Full-Text Search "brand": "Nike", // <-- Keyword, ใช้ Filter "price": 4500, // <-- Number, ใช้ Range Filter "release_date": "2024-06-01", // <-- Date, ใช้ Date Filter "description": "A responsive running shoe with ReactX foam...", // <-- Text "description_vector": [0.123, -0.456, 0.789, ...] // <-- dense_vector, ใช้ Vector Search}สรุปเป็นตารางได้ตามด้านล่างนี้
| คุณสมบัติ | Elasticsearch | Dedicated Vector Database (เช่น Milvus, Qdrant) |
|---|---|---|
| สถาปัตยกรรมหลัก | สร้างบน Inverted Index (ดัชนีกลับหัว) ซึ่งเป็นหัวใจของการค้นหาข้อความ (Full-text search) แบบดั้งเดิม ออกแบบมาเพื่อหาว่า “คำนี้” อยู่ใน “เอกสารไหนบ้าง” | สร้างบน ANN (Approximate Nearest Neighbor) Index เช่น HNSW, IVF ซึ่งเป็นอัลกอริทึมที่ออกแบบมาเพื่อค้นหา “เวกเตอร์ที่อยู่ใกล้กันที่สุด” ในข้อมูลหลายมิติโดยเฉพาะ |
| รูปแบบการค้นหาที่ถนัดที่สุด | Keyword Search / Full-text Search (ใช้ BM25, TF-IDF) คือเก่งที่สุดในการหาคำที่ตรงกันเป๊ะๆ หรือเกี่ยวข้องตามหลักสถิติของคำ | Semantic Search / Similarity Search (ใช้ Cosine Similarity, Euclidean Distance) คือเก่งที่สุดในการหา “ความหมาย” ที่คล้ายกัน |
| ประสิทธิภาพ (สำหรับ Vector Search โดยเฉพาะ) | ทำงานได้ดีในระดับเริ่มต้นถึงปานกลาง (หลักหมื่นถึงล้าน vectors) แต่เมื่อข้อมูลมีขนาดใหญ่มากๆ (หลายสิบล้าน vectors ขึ้นไป) ประสิทธิภาพจะลดลงอย่างเห็นได้ชัด ทั้งความเร็ว (Latency) และการใช้ทรัพยากร (CPU/Memory) | ประสิทธิภาพสูงกว่ามาก ถูกปรับแต่งมาเพื่อจัดการกับข้อมูลเวกเตอร์จำนวนมหาศาลโดยเฉพาะ ให้ Latency ที่ต่ำกว่าและรองรับ QPS (Queries Per Second) ได้สูงกว่าในสเกลเดียวกัน |
| กรณีใช้งานที่โดดเด่น | Log Analysis (ELK Stack), Full-text Search ในเว็บไซต์ E-commerce หรือเว็บข่าว, Monitoring, Security (SIEM) | RAG สำหรับ LLMs, Image/Audio Search, Recommendation Engines, Semantic Search ที่ต้องการความแม่นยำและความเร็วสูง |
| การค้นหาแบบผสม (Hybrid Search) | ทำได้ดีและเป็นธรรมชาติ เพราะมีทั้งความสามารถด้าน Keyword ที่แข็งแกร่งเป็นทุนเดิม และเสริมด้วย Vector Search | ในอดีตเคยเป็นจุดอ่อน แต่ปัจจุบัน Vector DB รุ่นใหม่ๆ ก็ได้เพิ่มความสามารถในการทำ Full-text Search (เช่น Sparse Vectors) เข้ามา เพื่อให้ทำ Hybrid Search ได้ดีขึ้นมาก |
| Ecosystem & Community | ใหญ่และเก่าแก่กว่ามาก มีเครื่องมือในตระกูล ELK (Logstash, Kibana) ที่ครบวงจร | ใหม่กว่า แต่เติบโตเร็วมาก และเชื่อมต่อกับ Ecosystem ของ AI/ML โดยตรง เช่น LangChain, LlamaIndex, PyTorch |
Vector embedding คืออะไร
ก่อนจะไปต่อ เราจำเป็นต้องมารู้จักกับศัพท์คำนี้ก่อน เพราะมันคือหัวใจสำคัญที่ใช้แปลงข้อมูลของเราให้กลายเป็นเวกเตอร์ครับ
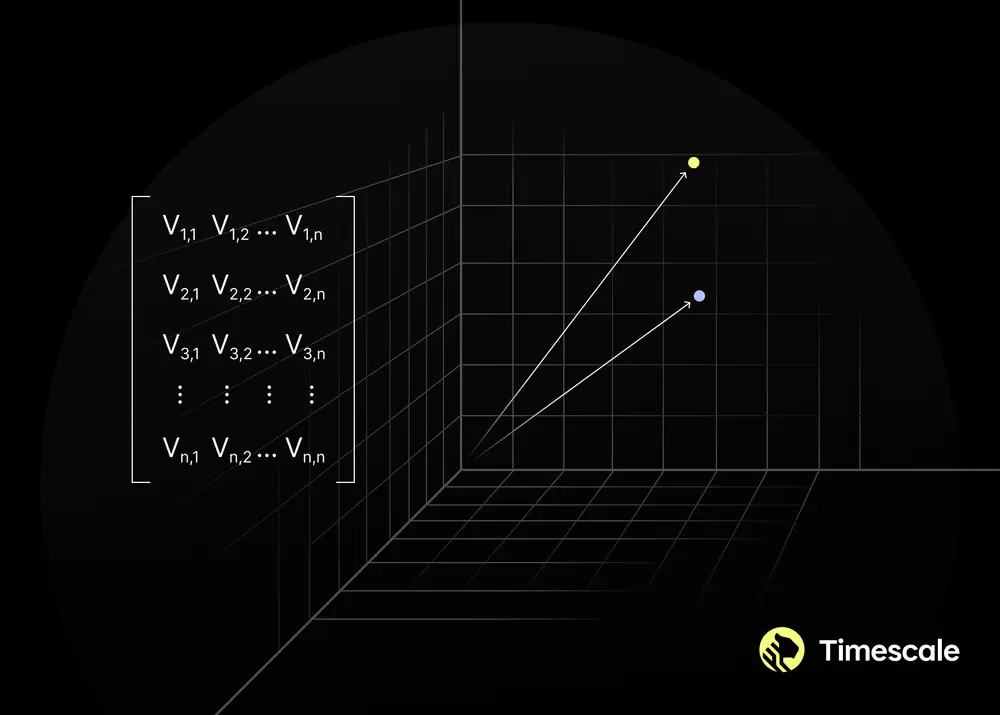
ref: https://www.tigerdata.com/blog/a-beginners-guide-to-vector-embeddings
Vector Embedding คือ การแปลงข้อมูลที่ซับซ้อน (เช่น ข้อความ รูปภาพ เสียง) ให้อยู่ในรูปแบบของชุดตัวเลข (ที่เรียกว่า “เวกเตอร์”) เพื่อให้คอมพิวเตอร์สามารถเข้าใจและประมวลผล “ความหมาย” ที่ซ่อนอยู่เบื้องหลังข้อมูลเหล่านั้นได้
ลองนึกภาพง่ายๆ ว่าเรากำลังสร้าง “แผนที่ของความหมาย” ขึ้นมาครับ:
- ข้อมูลแต่ละชิ้น (เช่น คำแต่ละคำ) คือ จุดหนึ่งจุด บนแผนที่
- ความสัมพันธ์หรือความหมายที่ใกล้เคียงกัน จะถูกวางไว้ ใกล้กัน บนแผนที่
- ความหมายที่แตกต่างกัน จะถูกวางไว้ ห่างกัน
ตัวเลขในเวกเตอร์ก็เปรียบเสมือน “พิกัด” (เช่น ละติจูด, ลองจิจูด) ของจุดนั้นๆ บนแผนที่ แต่แทนที่จะมีแค่ 2-3 มิติเหมือนแผนที่ทั่วไป Vector Embedding อาจมีได้เป็นร้อยเป็นพันมิติ ทำให้สามารถจับความสัมพันธ์ที่ซับซ้อนได้ดียิ่งขึ้น
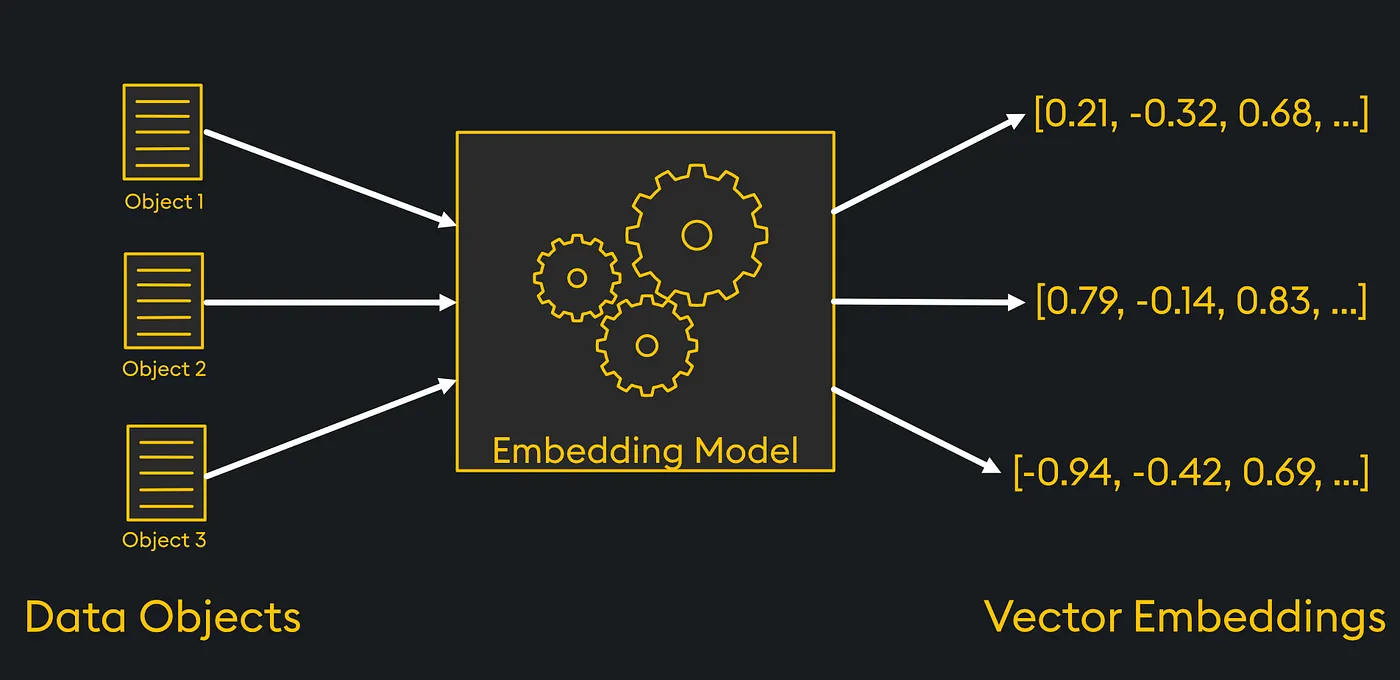
หัวใจสำคัญของ Vector Embedding คือ:
-
แปลงข้อมูลเป็นตัวเลข (Numerical Representation): คอมพิวเตอร์ไม่เข้าใจคำว่า “แมว” หรือรูปแมว แต่เข้าใจเวกเตอร์ที่เป็นชุดตัวเลข เช่น [0.1, -0.5, 0.8, …]
-
จับความหมายและความสัมพันธ์เชิงลึก (Capturing Semantics): นี่คือส่วนที่สำคัญที่สุด เวกเตอร์ที่สร้างขึ้นไม่ได้เป็นตัวเลขสุ่มๆ แต่มันเก็บ “ความหมาย” ไว้ด้วย เช่น
- เวกเตอร์ของคำว่า “รถยนต์” จะอยู่ใกล้กับเวกเตอร์ของ “ยานพาหนะ” มากกว่าคำว่า “กล้วย”
- เวกเตอร์ของรูปภาพ “แมว” จะอยู่ใกล้กับรูป “สุนัข” (เพราะเป็นสัตว์เลี้ยงเหมือนกัน) มากกว่ารูป “โต๊ะ”
-
ทำให้เกิดการคำนวณทางคณิตศาสตร์ได้: เมื่อความหมายกลายเป็นตัวเลข เราจึงสามารถนำไปคำนวณได้ ตัวอย่างที่คลาสสิกที่สุดคือ:
เวกเตอร์('ราชา') - เวกเตอร์('ชาย') + เวกเตอร์('หญิง') จะได้ผลลัพธ์ที่ใกล้เคียงกับ เวกเตอร์('ราชินี')
Vector Embedding ถูกสร้างขึ้นโดยใช้ Model Machine Learning (เช่น Word2Vec, BERT, หรือ Model ในตระกูล Transformer) ที่ผ่านการฝึกฝนกับข้อมูลจำนวนมหาศาล Model เหล่านี้จะเรียนรู้วิธีการ “วาดแผนที่” หรือสร้างเวกเตอร์ที่สามารถจับความหมายเหล่านั้นไว้ได้
ทีนี้ หลายคนอาจจะสงสัยว่า แล้วทำไมเวกเตอร์ต้องมีขนาดไม่เท่ากัน? บาง Model ให้เวกเตอร์ 384 มิติ แต่บาง Model ให้มาตั้ง 1536 มิติ
คำตอบคือ มันไม่ใช่ค่าที่สุ่มขึ้นมาครับ แต่เป็นสิ่งที่นักวิจัยผู้ออกแบบ Model “ตั้งใจเลือก” มาอย่างดี โดยเป็นการชั่งน้ำหนักข้อดีข้อเสีย (Trade-offs) ระหว่าง “ความละเอียด” กับ “ความเร็วและค่าใช้จ่าย” คล้ายๆ กับการเลือกความละเอียดของรูปภาพเลยครับ:
- เวกเตอร์ขนาดใหญ่ (มิติเยอะ เช่น 1536, 3072): เปรียบเหมือนรูปภาพความละเอียดสูง (4K) ครับ มันสามารถเก็บรายละเอียดเล็กๆ น้อยๆ และแยกแยะความแตกต่างที่ซับซ้อนได้ดีกว่ามาก เช่น เข้าใจมุกประชดประชันที่ใช้คำเหมือนประโยคทั่วไปได้ แต่ข้อเสียก็คือ “ไฟล์ใหญ่” (ใช้พื้นที่เยอะ), ประมวลผลช้า และมีค่าใช้จ่ายสูงตามไปด้วย
- เวกเตอร์ขนาดเล็ก (มิติน้อย เช่น 384, 768): เปรียบเหมือนรูปภาพความละเอียดปกติ (Full HD) คือมีขนาดเล็กกว่า ทำให้ค้นหาและเปรียบเทียบได้เร็วกว่ามาก เหมาะสำหรับงานที่ต้องการการตอบสนองแบบเรียลไทม์ แต่ก็อาจจะตกหล่นรายละเอียดเชิงลึกบางอย่างไปบ้าง
ท้ายที่สุดแล้ว การเลือกใช้ Model ที่ให้ขนาดเวกเตอร์เท่าไหร่ ก็ขึ้นอยู่กับโจทย์ของเรา ว่าเราให้ความสำคัญกับความแม่นยำขั้นสุด หรือต้องการความเร็วในการทำงานมากกว่ากันนั่นเองครับ
ดังนั้น เราอาจสรุปได้ว่า Vector Embedding ก็คือการสกัดเอา “DNA ทางความหมาย” หรือ “ลายนิ้วมือดิจิทัล” ของข้อมูลออกมาครับ ไม่ว่าข้อมูลต้นทางจะเป็นอะไร ผลลัพธ์สุดท้ายคือชุดตัวเลขที่คอมพิวเตอร์สามารถนำไปเปรียบเทียบและจัดกลุ่มตามความหมายได้ และเจ้าชุดตัวเลขที่เต็มไปด้วยความหมายนี้เอง คือข้อมูลหลักที่ Vector Database ถูกสร้างขึ้นมาเพื่อจัดการโดยเฉพาะ
รู้จักกับ Vector Search
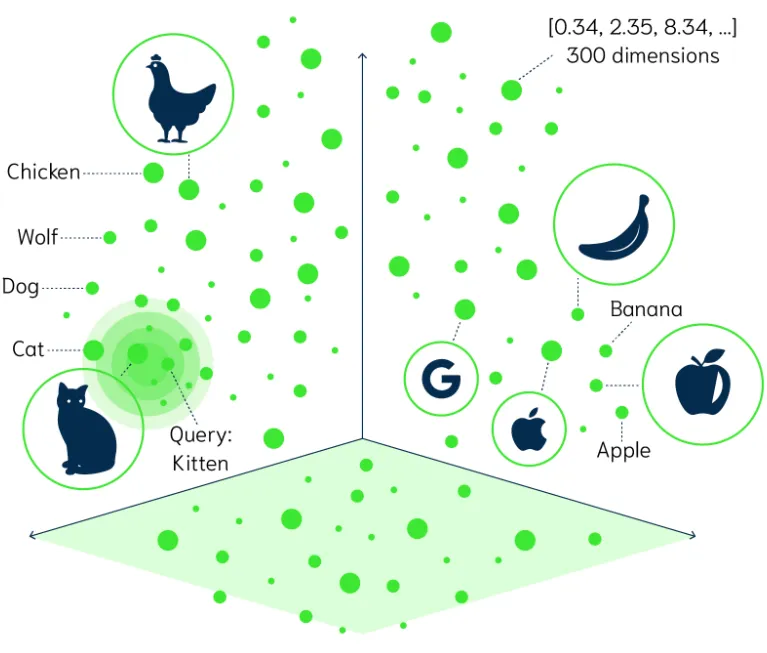
ref: https://www.fusionsol.com/blog/vector-search/
พอเรามี “แผนที่ความหมาย” ที่สร้างจาก Vector Embeddings แล้ว Vector Search ก็คือ กระบวนการค้นหาข้อมูลบนแผนที่นั้น มันคือวิธีการค้นหาที่เน้น “ความคล้ายคลึงเชิงความหมาย (Semantic Similarity)” แทนที่จะเป็นการจับคู่คำแบบตรงๆ (Keyword Matching)
เปรียบเทียบง่ายๆ:
- Keyword Search: ค้นหาคำว่า “รองเท้าวิ่งสำหรับผู้ชาย” ก็จะเจอเฉพาะสินค้าที่มีคำเหล่านี้เป๊ะๆ
- Vector Search: ค้นหาคำว่า “รองเท้าวิ่งสำหรับผู้ชาย” อาจจะเจอทั้ง “รองเท้ากีฬาสำหรับท่านชาย”, “สนีกเกอร์สำหรับออกกำลังกาย” หรือ “รองเท้าซ้อมวิ่งมาราธอน” เพราะ AI เข้าใจว่าทั้งหมดนี้คือแนวคิดเดียวกัน
คำถามคือ แล้ว Vector Embeddings กับ Vector Search ทำงานร่วมกันอย่างไร? เราจะแบ่งวิธีการออกเป็น 3 ขั้นตอนง่ายๆ แบบนี้ครับ
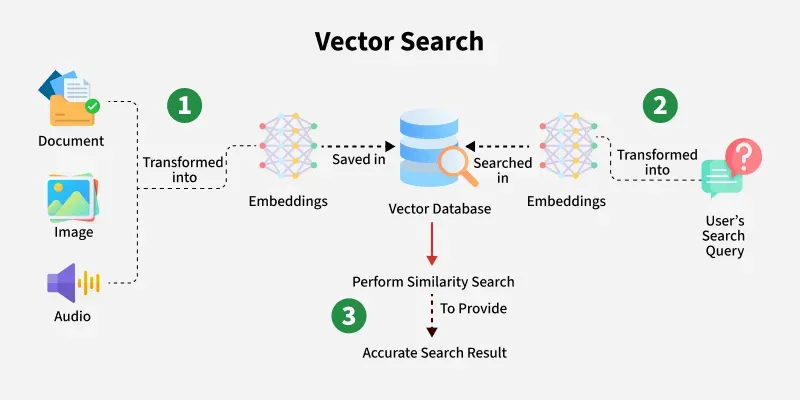
ref: https://www.geeksforgeeks.org/nlp/what-is-vector-search/
ขั้นตอนที่ 1: การเตรียมข้อมูล (Indexing)
- รวบรวมข้อมูล: นำข้อมูลทั้งหมดที่คุณต้องการให้ค้นหาได้ (เช่น รายละเอียดสินค้า, บทความ, รูปภาพ)
- สร้าง Vector Embeddings: นำข้อมูลแต่ละชิ้นเข้า AI Model เพื่อแปลงให้เป็นเวกเตอร์
- จัดเก็บใน Vector Database: นำเวกเตอร์ทั้งหมดไปเก็บในฐานข้อมูล (เช่น Pinecone, Milvus, Qdrant) ซึ่งจะทำ Indexing เพื่อให้ค้นหาได้รวดเร็ว
ขั้นตอนที่ 2: การค้นหา (Querying)
- รับคำค้นหาจากผู้ใช้: เช่น ผู้ใช้พิมพ์ว่า “แล็ปท็อปน้ำหนักเบาสำหรับทำงาน”
- แปลงคำค้นหาเป็นเวกเตอร์: นำคำค้นหานั้นไปผ่าน AI Model ตัวเดียวกันกับตอนเตรียมข้อมูล เพื่อแปลงให้เป็น “เวกเตอร์คำค้น (Query Vector)”
- ค้นหาเวกเตอร์ที่ใกล้ที่สุด: ระบบจะนำ “เวกเตอร์คำค้น” ไปเปรียบเทียบกับเวกเตอร์ทั้งหมดในฐานข้อมูล เพื่อหาว่าเวกเตอร์ของข้อมูลชิ้นไหนที่ “อยู่ใกล้ที่สุด”
ขั้นตอนที่ 3: การวัดผลและแสดงผล (Ranking & Retrieval)
- วัดระยะห่าง: การเปรียบเทียบความ “ใกล้” กันของเวกเตอร์ จะใช้วิธีทางคณิตศาสตร์ เช่น
.webp)
- Cosine Similarity: วัด “มุม” ระหว่างเวกเตอร์ ถ้ามุมแคบแสดงว่ามีความหมายไปในทิศทางเดียวกัน (คล้ายกันมาก) เราสนใจว่า “เนื้อหา” หรือ “ความหมาย” มันไปในแนวเดียวกันหรือไม่ มากกว่าจะสนใจว่าประโยคนั้นสั้นหรือยาวแค่ไหน
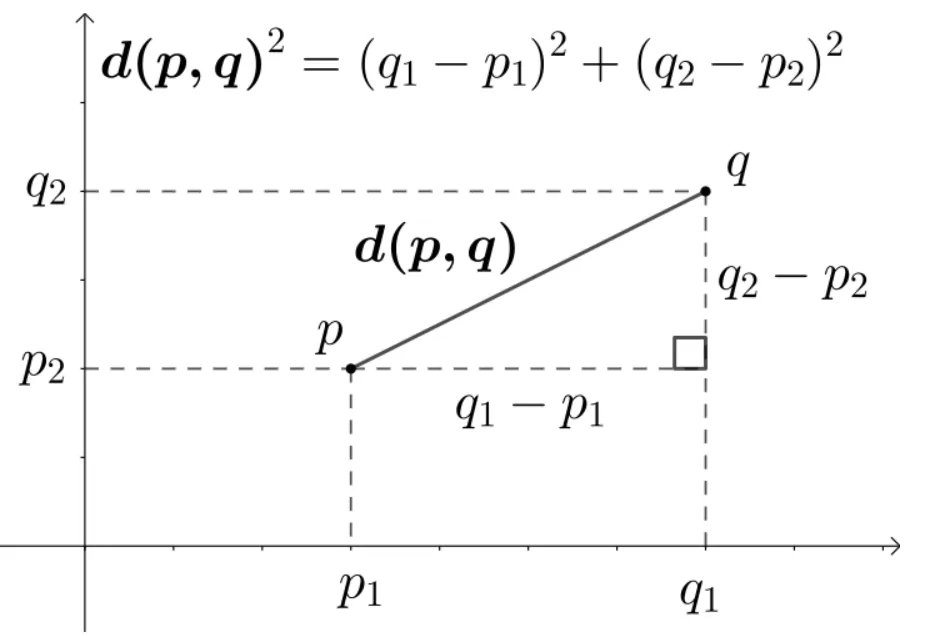
ref: https://en.wikipedia.org/wiki/Euclidean_distance
- Euclidean Distance: วัด “ระยะทาง” ตรงๆ ระหว่างจุดสองจุด
- จัดอันดับและส่งคืนผลลัพธ์: ระบบจะจัดอันดับข้อมูลตามคะแนนความคล้ายคลึง (Similarity Score) แล้วแสดงผลลัพธ์ที่เกี่ยวข้องมากที่สุดให้ผู้ใช้เห็น
สรุปความสัมพันธ์ของทั้งสองอย่างนี้ง่ายๆ คือ:
- Vector Embedding คือ ผู้สร้าง: มันสร้าง “แผนที่” ที่จัดวางข้อมูลตามความหมาย
- Vector Search คือ ผู้นำทาง: มันรับคำสั่ง (Query) ของคุณ แปลงเป็นพิกัดบนแผนที่นั้น แล้วพาคุณไปยังจุดหมาย (ข้อมูล) ที่อยู่ใกล้และมีความหมายสอดคล้องกับสิ่งที่คุณต้องการมากที่สุด
ถ้างั้น หมายความว่า เราต้องใช้ Vector Embedding Model เดียวกันใช่ไหม?
คำตอบคือ “ใช่เลยครับ!” เราต้องใช้ Vector Embedding Model ตัวเดียวกันเสมอ สำหรับทั้งการสร้าง Index (ข้อมูลที่เก็บไว้) และการสร้าง Vector ของคำค้นหา (Query)
ทำไมล่ะ? ลองนึกภาพว่า Vector Embedding Model คือ “นักแปลภาษา” หรือ “ผู้สร้างแผนที่” ครับ
- สถานการณ์ที่ 1: ใช้ Model เดียวกัน (ทำงานถูกต้อง)
- ตอน Indexing: คุณจ้าง “นักแปล A” มาแปลเอกสารทั้งหมดของคุณให้เป็น “ภาษา A” แล้วเก็บเข้าคลัง
- ตอน Querying: เมื่อมีคนมาถาม คุณก็จ้าง “นักแปล A” คนเดิมมาแปลคำถามนั้นให้เป็น “ภาษา A”
- ตอน Search: คุณนำคำถามที่เป็น “ภาษา A” ไปค้นหาในคลังเอกสารที่เป็น “ภาษา A” … แน่นอนว่ามันหากันเจอ! เพราะทุกอย่างอยู่ในระบบภาษาและแผนที่เดียวกัน
- สถานการณ์ที่ 2: ใช้คนละ Model (ทำงานผิดพลาด)
- ตอน Indexing: คุณจ้าง “นักแปล A” มาแปลเอกสาร
- ตอน Querying: คุณดันไปจ้าง “นักแปล B” มาแปลคำถาม
- ตอน Search: คุณนำคำถามที่แปลโดยนักแปล B ไปค้นหาในคลังเอกสารที่แปลโดยนักแปล A … มันจะวุ่นวายและหากันไม่เจอ! เพราะพิกัดหรือคำแปลของนักแปล B ไม่มีความหมายอะไรเลยบนแผนที่ของนักแปล A
ที่เป็นแบบนี้ก็เพราะเหตุผลทางเทคนิคง่ายๆ 3 ข้อนี้เลยครับ
- Vector Space ที่แตกต่างกัน: แต่ละ Model เปรียบเสมือนคนวาดแผนที่คนละคนกันครับ พวกเขามีวิธีจัดวาง “เมือง” (ความหมาย) ใน “โลก” (ปริภูมิ) ของตัวเองที่ไม่เหมือนกันเลย ดังนั้น เวกเตอร์ [0.1, 0.5, -0.2] บนแผนที่ของ Model A อาจจะชี้ไปที่เมือง “แมว” แต่พิกัดเดียวกันนี้บนแผนที่ของ Model B อาจจะชี้ไปที่เมือง “เศรษฐกิจ” หรืออาจจะเป็นแค่พื้นที่ว่างเปล่าที่ไม่มีความหมายเลยก็ได้
- จำนวนมิติ (Dimensions) ไม่เท่ากัน: Model แต่ละตัวสร้างเวกเตอร์ที่มี “จำนวนพิกัด” ไม่เท่ากัน เช่น Model all-MiniLM-L6-v2 อาจจะใช้ 384 พิกัดในการระบุตำแหน่ง ในขณะที่ text-embedding-3-small ของ OpenAI ใช้ถึง 1536 พิกัด มันจึงเหมือนกับการพยายามเปรียบเทียบที่อยู่ที่มี 2 มิติ กับที่อยู่ที่มี 3 มิติ ซึ่งเราไม่สามารถนำมาเทียบกันตรงๆ ได้เลย
- การคำนวณทางคณิตศาสตร์ใช้ไม่ได้: และเมื่อทั้ง “แผนที่” และ “จำนวนพิกัด” ไม่เหมือนกัน การคำนวณทางคณิตศาสตร์เพื่อหาความ “ใกล้” กัน (เช่น Cosine Similarity) จึงไม่สามารถทำงานได้เลยครับ เพราะเวกเตอร์ทั้งหมดไม่ได้อยู่ในระบบพิกัดหรือโลกใบเดียวกันนั่นเอง
และนี่ก็คือหัวใจทั้งหมดของ Vector Database นั่นเอง
Demo 1 : SQLite + Easy Vector
code ทั้งหมด 3 demo สามารถดู code ฉบับเต็มได้ผ่านที่นี่ได้เลย https://github.com/mikelopster/vector-db-python-example
หลังจากที่เราเรียนรู้ทฤษฎีกันมาพอสมควรแล้ว ลองมาดูตัวอย่างแรกที่จับต้องได้และเรียบง่ายที่สุดกันครับ ในเดโมนี้ เราจะเปลี่ยนฐานข้อมูลที่เราคุ้นเคยกันดีอย่าง SQLite ให้กลายเป็น Vector Database แบบง่ายๆ ด้วย Extension ที่ชื่อว่า sqlite-vec (https://github.com/asg017/sqlite-vec)
วิธีนี้เหมาะอย่างยิ่งสำหรับการเริ่มต้นทำความเข้าใจกระบวนการทั้งหมด เพราะมันไม่ต้องติดตั้งเซิร์ฟเวอร์แยก, ไม่ซับซ้อน และเห็นภาพรวมตั้งแต่การสร้าง Vector ไปจนถึงการค้นหาภายในไฟล์โค้ดไฟล์เดียว
(ตัวอย่างนี้เราได้แรงบันดาลใจมาจาก video นี้ https://www.youtube.com/watch?v=jGPxr0Qk-Vs ทุกคนสามารถดูอีกตัวอย่างจาก video ต้นทางเพื่อเติมเต็มความเข้าใจได้เช่นกัน)
สิ่งที่เราต้องใช้มีแค่:
- Python
- sqlite-vec (ติดตั้งง่ายๆ ด้วย
pip install sqlite-vec)
เราจะเขียนสคริปต์ Python ที่ทำหน้าที่ดังนี้:
- ตั้งค่า SQLite และโหลด Extension
sqlite-vecเข้ามา - สร้างตาราง สำหรับเก็บข้อมูลดิบ (ข้อความ)
- สร้างตารางเสมือน Virtual Table สำหรับเก็บ Vector Embeddings โดยเฉพาะ
- แปลงข้อความ ของเราให้กลายเป็น Vector (ในเดโมนี้จะใช้วิธีจำลองแบบง่ายๆ ก่อน) แล้วเก็บลงในตารางทั้งสอง
- ทำการค้นหา (Vector Search) โดยใช้คำค้นหา (Query) เพื่อหาประโยคที่ “ใกล้เคียง” ที่สุดในฐานข้อมูล
มาดูโค้ดและคำอธิบายไปทีละส่วนกันเลยครับ
Step 1: เตรียมฐานข้อมูลและโหลด Extension
สิ่งแรกที่ต้องทำคือการเชื่อมต่อกับ SQLite และที่สำคัญที่สุดคือการ “ปลุกพลัง” Vector Search ด้วยการโหลด Extension sqlite-vec เข้ามา
import sqlite3import sqlite_vecimport hashlibimport jsonfrom typing import List
# Step 1 - Connection SQLiteconn = sqlite3.connect("demo.db")conn.enable_load_extension(True)sqlite_vec.load(conn)cur = conn.cursor()sqlite_vec.load(conn) คือหัวใจของขั้นตอนนี้ มันจะไปโหลดไฟล์ Extension ที่จำเป็นเข้ามาใน Connection ของ SQLite ทำให้เราสามารถใช้คำสั่ง SQL พิเศษสำหรับ Vector Search ได้
Step 2: สร้างตารางและเตรียมข้อมูล
เราจะสร้างตาราง 2 ตารางครับ
docs: ตารางธรรมดาสำหรับเก็บข้อมูลต้นฉบับที่เป็นข้อความvec_docs: ตารางเสมือน (Virtual Table) ที่สร้างโดย sqlite-vec เพื่อจัดเก็บและทำดัชนี Vector โดยเฉพาะ
# Create Tablecur.execute("""CREATE TABLE IF NOT EXISTS docs ( id INTEGER PRIMARY KEY, content TEXT NOT NULL);""")
# Create Vector Tablecur.execute("""CREATE VIRTUAL TABLE IF NOT EXISTS vec_docs USING vec0( embedding FLOAT[8] -- กำหนดว่าเวกเตอร์จะมี 8 มิติ);""")สังเกตคำสั่ง CREATE VIRTUAL TABLE ... USING vec0 นะครับ นี่ไม่ใช่การสร้างตารางแบบปกติ แต่เป็นการบอกให้ sqlite-vec สร้างโครงสร้างพิเศษที่ปรับแต่งมาเพื่อค้นหา Vector โดยเฉพาะ เรากำหนดให้คอลัมน์ embedding เป็นชนิดข้อมูล FLOAT[8] หมายความว่าเวกเตอร์แต่ละอันของเราจะประกอบด้วยตัวเลขทศนิยม 8 ตัว
Step 3: การสร้าง Vector Embedding (ฉบับจำลอง)
ในโลกความเป็นจริง เราจะใช้ AI Model ขนาดใหญ่เพื่อแปลงข้อความให้เป็น Vector ที่มีความหมายเชิงลึก แต่เพื่อความง่ายในเดโมนี้ เราจะสร้าง function จำลองที่ชื่อ embed_text ขึ้นมา ซึ่งจะแปลงข้อความใดๆ ให้กลายเป็นเวกเตอร์ขนาด 8 มิติที่ตายตัวเสมอ โดยใช้ค่า Hash
Note: function นี้สร้างขึ้นมาเพื่อการสาธิต “กระบวนการ” เท่านั้น มันไม่ได้เข้าใจ “ความหมาย” ของข้อความเหมือน AI Model จริงๆ แต่ทำให้เราเห็นภาพว่าข้อความถูกเปลี่ยนเป็นชุดตัวเลขได้อย่างไร
def embed_text(text: str, dim: int = 8) -> List[float]: """ function จำลองการสร้าง Embedding แบบง่ายๆ เพื่อการสาธิต ใช้ SHA256 ของข้อความเพื่อสร้างเวกเตอร์ที่ได้ผลลัพธ์เหมือนเดิมทุกครั้ง """ h = hashlib.sha256(text.encode("utf-8")).digest() vec = [] for i in range(dim): b1 = h[(i * 2) % len(h)] b2 = h[(i * 2 + 1) % len(h)] val = (b1 << 8) | b2 f = (val / 65535.0) * 2.0 - 1.0 # ทำให้ค่าอยู่ในช่วง [-1, 1] vec.append(f) return vecStep 4: เพิ่มข้อมูลและ Vector ลงในตาราง
ตอนนี้เราจะนำข้อมูลประโยคตัวอย่างมาใส่ในตาราง docs จากนั้นใช้ function embed_text แปลงแต่ละประโยคให้เป็น Vector แล้วใส่ลงในตาราง vec_docs โดยใช้ rowid เดียวกันเพื่อให้ข้อมูลสองตารางนี้เชื่อมถึงกันได้
# Insert docs only if table is empty (idempotent)cur.execute("SELECT COUNT(*) FROM docs;")docs = [ (1, "The quick brown fox jumps over the lazy dog"), (2, "A fast auburn fox leaps above a sleepy canine"), (3, "An article about database systems and vector search"), (4, "Deep learning and embeddings for natural language processing"),]docs_count = cur.fetchone()[0]if docs_count == 0: cur.executemany("INSERT INTO docs(id, content) VALUES (?, ?);", docs)
# Insert vector docscur.execute("SELECT COUNT(*) FROM vec_docs;")vec_count = cur.fetchone()[0]if vec_count == 0: rows = [] for _id, text in docs: emb = embed_text(text, dim=8) rows.append((_id, json.dumps(emb)))
cur.executemany("INSERT INTO vec_docs(rowid, embedding) VALUES (?, ?);", rows) conn.commit()Step 5: ค้นหาด้วย Vector Search
มาถึงส่วนสุดท้าย เราจะทำการค้นหาแบบ K-Nearest Neighbors (KNN) เพื่อหาข้อมูลที่ “ใกล้” กับคำค้นหาของเรามากที่สุด
สมมติว่าเราต้องการค้นหาด้วยคำว่า “fox dog”
- แปลงคำค้นหา: เราต้องนำคำว่า “fox dog” ไปผ่าน function embed_text ตัวเดียวกัน กับที่ใช้สร้างข้อมูล เพื่อให้ได้ “เวกเตอร์คำค้น (Query Vector)”
- ค้นหาในตาราง Vector: เราจะใช้ MATCH operator ซึ่งเป็นคำสั่งพิเศษจาก sqlite-vec เพื่อค้นหาเวกเตอร์ที่อยู่ใกล้ Query Vector ของเราที่สุด
- ดึงข้อมูลต้นฉบับ: เมื่อได้ rowid ของผลลัพธ์แล้ว เราก็นำไป JOIN กับตาราง docs เพื่อดึงข้อความต้นฉบับกลับมาแสดงผล
# Step 4 - Test queryquery = "fox dog"text_query = queryquery_vec = embed_text(text_query, dim=8)query_vec_json = json.dumps(query_vec)res = cur.execute( """ SELECT rowid, distance FROM vec_docs WHERE embedding MATCH ? ORDER BY distance LIMIT 2; """, (query_vec_json,)).fetchall()
for rowid, distance in res: print(f"- rowid={rowid} distance={float(distance):.12f}")ผลลัพธ์ที่ได้ เมื่อรันสคริปต์ทั้งหมด เราจะได้ผลลัพธ์หน้าตาประมาณนี้:
python3 01_sqlite.pyQuery: 'fox dog'- id=3 distance=1.915138 content=An article about database systems and vector search- id=1 distance=2.211798 content=The quick brown fox jumps over the lazy dog
KNN embed_text:- rowid=3 distance=1.915137887001- rowid=1 distance=2.211798191071จะเห็นว่าระบบสามารถหา 2 ประโยคแรกที่มีคำว่า fox และ dog (หรือคำใกล้เคียงอย่าง canine) กลับมาได้ โดยจัดอันดับตามค่า distance ยิ่งค่านี้น้อยเท่าไหร่ ก็แปลว่าเวกเตอร์ของประโยคนั้น “อยู่ใกล้” หรือ “คล้าย” กับเวกเตอร์ของคำค้นหาเรามากเท่านั้น
สรุปจาก Demo ที่ 1
- กระบวนการแปลงข้อมูล (Embedding): ข้อมูลทุกชิ้น (ทั้งข้อมูลในคลังและคำค้นหา) ต้องถูกแปลงเป็นเวกเตอร์ด้วย Model เดียวกัน
- การทำดัชนี (Indexing): ฐานข้อมูลใช้โครงสร้างพิเศษ (Virtual Table) เพื่อจัดเก็บและค้นหาเวกเตอร์ได้อย่างรวดเร็ว
- การค้นหา (Searching): ใช้คำสั่งพิเศษ (MATCH) เพื่อคำนวณหาระยะห่างและค้นหาเวกเตอร์ที่ใกล้ที่สุด
Demo 2 : ChromaDB + Vector Text
ในเดโมแรก เราได้ทดลองเปลี่ยน SQLite ให้กลายเป็น Vector Database แบบง่ายๆ ซึ่งทำให้เห็นภาพรวมของกระบวนการทั้งหมด แต่ในโลกของการใช้งานจริง เรามักจะเลือกใช้ฐานข้อมูลที่ถูกสร้างขึ้นมาเพื่อ “งานเวกเตอร์” โดยเฉพาะ (Purpose-built)
ในเดโมนี้ เราจะขยับมาใช้ ChromaDB ซึ่งเป็นหนึ่งใน Vector Database แบบ Open-source ที่ได้รับความนิยมสูงมาก เพราะใช้งานง่ายและทรงพลังอย่างเหลือเชื่อ
ทำความรู้จักกับ ChromaDB
ChromaDB คือฐานข้อมูลเวกเตอร์แบบ AI-native ที่ออกแบบมาเพื่อให้การสร้างแอปพลิเคชัน AI ที่ต้องใช้ Embeddings เป็นเรื่องง่าย มันถูกสร้างขึ้นจากศูนย์เพื่อจัดการกับ Vector Embeddings โดยเฉพาะ
ทำไม ChromaDB ถึงเป็นก้าวที่สำคัญกว่าเดโมแรก?
- “Zero-Setup” Embedding: นี่คือจุดเด่นที่สุด! ChromaDB มาพร้อมกับ AI Model สำหรับสร้าง Embedding ในตัว เราไม่ต้องตั้งค่าหรือเลือก Model ใดๆ เลย แค่ส่งข้อความเข้าไป มันจะจัดการแปลงเป็น Vector ให้โดยอัตโนมัติ ทำให้การเริ่มต้นนั้นง่ายสุดๆ
- API ที่ออกแบบมาเพื่องาน Vector: คำสั่งต่างๆ เช่น
add,queryถูกออกแบบมาอย่างดี ทำให้การเพิ่มและค้นหาข้อมูลเวกเตอร์ทำได้ง่ายเหมือนการใช้คำสั่งของพวก NoSQL - ทำงานได้ทันที (Works out of the box): สามารถรันในหน่วยความจำ (in-memory) หรือบันทึกลงดิสก์ได้ง่ายๆ โดยไม่ต้องตั้งค่าเซิร์ฟเวอร์ที่ซับซ้อน เหมาะสำหรับการพัฒนาและทดลองอย่างรวดเร็ว
เริ่มต้นติดตั้ง (Installation)
การติดตั้ง ChromaDB ก็ทำได้ง่ายๆ ผ่าน pip เช่นกันครับ
pip install chromadbเมื่อติดตั้งเสร็จแล้ว เราก็พร้อมที่จะมาดูโค้ดกันเลยครับ จะเห็นว่ามันเรียบง่ายและสั้นอย่างไม่น่าเชื่อ
Step 1: เชื่อมต่อและสร้าง Collection
ขั้นตอนแรกคือการเชื่อมต่อกับ ChromaDB และสร้าง “Collection” (เปรียบเสมือน “Table” ใน SQL) ขึ้นมาเพื่อเก็บข้อมูลของเรา
# Step 1 - Setup Chromaimport chromadbclient = chromadb.Client()collection = client.get_or_create_collection( name="demo_collection")จุดเด่นสำคัญคือเราไม่จำเป็นต้องระบุ embedding_function เลย เพราะ ChromaDB ได้เตรียม Model เริ่มต้น (Default Model) ที่มีประสิทธิภาพดีอย่าง all-MiniLM-L6-v2 ไว้ให้ใช้งานโดยอัตโนมัติ ทำให้เราสามารถเริ่มต้นเขียนโค้ดได้ทันทีโดยไม่ต้องตั้งค่าใดๆ เพิ่มเติม (ref: https://docs.trychroma.com/docs/embeddings/embedding-functions)
Step 2: เพิ่มข้อมูล (Add Documents)
การเพิ่มข้อมูลใน ChromaDB นั้นง่ายมาก เราแค่เตรียมรายการ ids (รหัสที่ไม่ซ้ำกัน) และ documents (เนื้อหาข้อความ) แล้วส่งให้ collection.add() ได้เลย ที่เหลือ ChromaDB จัดการให้หมด!
# Step 2 - เพิ่มเอกสารเข้า collectiondocs = [ ("1", "The quick brown fox jumps over the lazy dog"), ("2", "A fast auburn fox leaps above a sleepy canine"), ("3", "An article about database systems and vector search"), ("4", "Deep learning and embeddings for natural language processing"),]ids = [d[0] for d in docs]documents = [d[1] for d in docs]# Add documents. If documents with same ids already exist Chroma will raise,try: collection.delete(ids=ids)except Exception: pass
collection.add(ids=ids, documents=documents)เบื้องหลังการทำงานของ collection.add() คือ ChromaDB จะนำแต่ละประโยคใน documents ไปเข้า Model Embedding เริ่มต้นของมัน เพื่อแปลงเป็น Vector แล้วจึงจัดเก็บทั้ง Vector และข้อมูลต้นฉบับไว้คู่กันโดยอัตโนมัติ
Step 3: ค้นหาด้วย Vector Search!
การค้นหาก็ง่ายไม่แพ้กัน เราใช้เมธอด collection.query() แล้วส่งข้อความที่เราต้องการค้นหาเข้าไปได้เลย
# Step 3 - ทดสอบ Queryquery = "fox dog"result = collection.query( query_texts=[query], n_results=2, include=["distances", "documents", "metadatas"],)
print(f"Query: {query!r}")# result is a dict-of-lists; extract the first query resultdocs_out = result.get("documents", [[]])[0]dists_out = result.get("distances", [[]])[0]for doc, dist in zip(docs_out, dists_out): print(f"- distance={dist:.6f} content={doc}")เพียงเท่านี้ ChromaDB ก็จะนำคำค้น fox dog ไปแปลงเป็นเวกเตอร์ด้วย Model เริ่มต้นตัวเดียวกัน แล้วทำการค้นหาเวกเตอร์ที่ใกล้ที่สุด (k=2) ใน Collection กลับมาให้เราอย่างรวดเร็ว
ผลลัพธ์ที่ได้
Query: 'fox dog'- distance=0.681374 content=The quick brown fox jumps over the lazy dog- distance=0.841353 content=A fast auburn fox leaps above a sleepy canineผลลัพธ์ยังคงเป็น 2 ประโยคเดิมที่เกี่ยวข้องกับ fox และ dog มากที่สุด โดยค่า distance ที่เห็นนี้มาจากการวัดระยะห่างระหว่างเวกเตอร์ที่สร้างจาก AI Model ที่เข้าใจความหมายจริงๆ ไม่ใช่จากการ Hash แบบจำลองในเดโมแรกอีกต่อไป
สรุปจาก Demo ที่ 2
การใช้ ChromaDB ในรูปแบบที่เรียบง่ายที่สุดนี้ แสดงให้เห็นถึงความสะดวกสบายและพลังของ Vector Database สมัยใหม่ได้อย่างชัดเจน:
- เริ่มต้นได้ทันที: เราไม่จำเป็นต้องเลือกหรือตั้งค่า AI Model เองเลย ChromaDB จัดการส่วนที่ซับซ้อนที่สุดให้ ทำให้เราโฟกัสกับการพัฒนาแอปพลิเคชันได้เต็มที่
- API ที่เป็นมิตร: คำสั่งต่างๆ ถูกออกแบบมาเพื่องานด้าน AI โดยตรง ทำให้โค้ดอ่านง่าย สั้น และสื่อความหมายได้ดี
- ใช้ AI จริง: การค้นหาครั้งนี้เป็นการค้นหาเชิงความหมาย (Semantic Search) ที่แท้จริง ตั้งแต่บรรทัดแรกของโค้ด
ในเดโมถัดไป เราจะมาดูกันว่า Vector Database ไม่ได้จำกัดอยู่แค่กับข้อความ แต่ยังสามารถนำไปประยุกต์ใช้กับข้อมูลประเภทอื่นอย่าง “รูปภาพ” ได้อย่างไร
Demo 3 : ChromaDB + Vector Image
หลังจากที่เราได้เห็นพลังของ ChromaDB ในการจัดการกับ “ข้อความ” กันไปแล้ว คำถามต่อไปคือ… แล้วถ้าข้อมูลของเราไม่ใช่ตัวอักษรล่ะ? จะทำยังไงถ้าเราอยากค้นหา “รูปภาพ”?
ในเดโมสุดท้ายนี้ เราจะยกระดับการใช้งาน Vector Database ไปอีกขั้น ด้วยการนำ ChromaDB มาจัดการกับ ข้อมูลรูปภาพ โดยตรง เราจะได้เห็นว่าหลักการของ Vector Search นั้นทรงพลังและยืดหยุ่นมากพอที่จะ “เข้าใจ” และ “เปรียบเทียบ” ความหมายที่ซ่อนอยู่ในรูปภาพได้ไม่ต่างจากข้อความเลย
นี่คือจุดที่ Vector Database แสดงศักยภาพที่แท้จริงออกมา เพราะมันไม่ได้จำกัดอยู่แค่ข้อมูลประเภทเดียว แต่สามารถเป็น “ห้องสมุดแห่งความหมาย” ให้กับข้อมูลทุกรูปแบบได้
พลังของ Multimodal AI
ref: https://docs.trychroma.com/docs/embeddings/multimodal#adding-multimodal-data-and-data-loaders
หัวใจสำคัญที่ทำให้เราสามารถค้นหารูปภาพด้วยข้อความ (Text-to-Image Search) หรือค้นหารูปภาพด้วยรูปภาพ (Image-to-Image Search) ได้ คือสิ่งที่เรียกว่า Multimodal AI Model ครับ
ลองจินตนาการว่า Model AI คือ “นักแปล” ที่เชี่ยวชาญหลายภาษา:
- Model ในเดโมที่ 2 เชี่ยวชาญ “ภาษาข้อความ” อย่างเดียว
- แต่ Model ที่เราจะใช้ในเดโมนี้ (เช่น OpenCLIP) เชี่ยวชาญทั้ง “ภาษาข้อความ” และ “ภาษาภาพ” และที่สำคัญที่สุดคือ มันสามารถแปลข้ามภาษากันได้!
Model นี้จะสร้าง “แผนที่ความหมาย” ที่มีทั้งจุดที่เป็นตัวอักษรและจุดที่เป็นรูปภาพอยู่บนพื้นที่เดียวกัน ทำให้เวกเตอร์ของคำว่า “สุนัข” จะถูกวางไว้ใกล้กับเวกเตอร์ของ “รูปภาพสุนัข” นั่นเอง
ส่วนประกอบใหม่ที่ต้องรู้จัก: Embedding Function และ Data Loader
ในเดโมที่ 2 ChromaDB จัดการทุกอย่างให้เราโดยอัตโนมัติ แต่เมื่อเราทำงานกับข้อมูลที่ซับซ้อนขึ้นอย่างรูปภาพ เราจำเป็นต้อง “บอก” ChromaDB เพิ่มอีก 2 เรื่องครับ:
Embedding Function(ใครจะแปลง?): เราต้องระบุให้ชัดเจนว่าจะใช้ AI Model ตัวไหนในการแปลงข้อมูล ในที่นี้เราจะเลือกใช้OpenCLIPEmbeddingFunctionซึ่งเป็น Model Multimodal ที่ ChromaDB เตรียมไว้ให้ (ref: https://github.com/mlfoundations/open_clip)Data Loader(จะโหลดข้อมูลยังไง?): ChromaDB ไม่ได้เก็บไฟล์รูปภาพต้นฉบับไว้ตรงๆ แต่มันจะเก็บแค่ Vector เท่านั้น ดังนั้น เราต้องบอกมันว่าจะไป “โหลด” รูปภาพจากที่ไหนและอย่างไร ในที่นี้เราจะใช้ImageLoaderเพื่อบอกให้มันไปอ่านไฟล์รูปภาพจาก Path ที่เราส่งให้นั่นเอง
เริ่มต้นติดตั้ง (Installation)
เนื่องจากเราจะใช้ Model ที่เฉพาะเจาะจงมากขึ้น เราต้องติดตั้ง Dependencies เพิ่มเติมเล็กน้อยครับ
pip install chromadb open-clip-torchเมื่อติดตั้งเสร็จแล้ว มาดูโค้ดกันเลยครับ จะเห็นว่ามันยังคงเรียบง่าย แต่ทรงพลังขึ้นอย่างเห็นได้ชัด
Step 1: เตรียมข้อมูลและ Metadata
เหมือนเดิมครับ เราเริ่มต้นจากการเตรียมข้อมูล แต่ครั้งนี้แทนที่จะเป็นประโยค เราจะใช้ Path ของไฟล์รูปภาพแทน
# Step 1 - เตรียม path ของรูปและ metadataall_image_paths = ["images/dog1.png", "images/dog2.png", "images/cat1.png", ...]labels = ["dog", "dog", "cat", ...]doc_ids = [str(uuid.uuid4()) for _ in all_image_paths]
# สร้าง metadata เพื่อเก็บข้อมูลเสริมเกี่ยวกับรูปภาพmetadatas = [ { "label": lbl, "filename": os.path.basename(path), "description": f"A photo of a {lbl}" } for lbl, path in zip(labels, all_image_paths)]Step 2: สร้าง Collection แบบ Multimodal
นี่คือขั้นตอนที่แตกต่างและสำคัญที่สุดครับ ตอนที่เราสร้าง Collection เราจะระบุ embedding_function และ data_loader ที่เราต้องการใช้งานเข้าไปด้วย
import chromadbfrom chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunctionfrom chromadb.utils.data_loaders import ImageLoader
# Step 2 - Setup ChromaDB Clientclient = chromadb.PersistentClient(path="./chroma_multimodal_db")
# Step 3 - สร้าง Collection พร้อมระบุ "ผู้ช่วย" ทั้งสองcollection = client.get_or_create_collection( name="pets_multimodal_collection", embedding_function=OpenCLIPEmbeddingFunction(), # บอกให้ใช้ OpenCLIP data_loader=ImageLoader(), # บอกให้ใช้ ImageLoader metadata={"hnsw:space": "cosine"})เมื่อสร้าง Collection แบบนี้ ChromaDB จะรู้ทันทีว่า Collection นี้ถูกออกแบบมาเพื่อทำงานกับรูปภาพ และรู้ว่าจะต้องใช้เครื่องมืออะไรในการจัดการ
Step 3: เพิ่มรูปภาพเข้าสู่ฐานข้อมูล
การเพิ่มรูปภาพนั้นง่ายอย่างไม่น่าเชื่อ เราไม่ต้องเปิดไฟล์หรือแปลงรูปภาพใดๆ ด้วยตัวเองเลย แค่ส่ง Path ของไฟล์ (URIs) เข้าไปใน collection.add() เท่านั้น!
# Step 4 - เพิ่มรูปเข้า DB โดยใช้ URIscollection.add( ids=doc_ids, uris=all_image_paths, # <--- ส่งแค่ Path ของไฟล์รูปภาพ! metadatas=metadatas)เบื้องหลังการทำงาน:
- ChromaDB เห็น
urisที่เราส่งเข้ามา - มันจะเรียก
ImageLoaderให้ไปเปิดไฟล์รูปภาพจากแต่ละ Path - จากนั้นส่งรูปภาพที่โหลดมาได้ไปให้
OpenCLIPEmbeddingFunctionเพื่อแปลงเป็น Vector - สุดท้าย มันจะจัดเก็บ Vector ที่ได้ลงในฐานข้อมูล พร้อมกับ
metadatasที่เราแนบไปด้วย
Step 4: ค้นหารูปภาพ… ด้วย “ข้อความ”!
และนี่คือความมหัศจรรย์ของ Multimodal Vector Search ครับ เราสามารถใช้ collection.query() แล้วส่ง query_texts ซึ่งเป็นข้อความธรรมดาๆ เข้าไปเพื่อค้นหารูปภาพที่เกี่ยวข้องที่สุดได้เลย
# Step 5 - ทดสอบ Query ด้วยข้อความquery_text = "dog"res = collection.query( query_texts=[query_text], # <--- ค้นหาด้วยคำว่า "dog" n_results=4, include=["metadatas", "distances"])
# แสดงผลลัพธ์print(f"\\n=== Query: '{query_text}' ===")for rank, (meta, dist) in enumerate(zip(res["metadatas"][0], res["distances"][0]), start=1): print(f"#{rank} -> {meta['filename']} ({meta['label']}) distance={dist:.4f}")ผลลัพธ์ที่ได้
=== Query: 'dog' ===#1 -> dog1.png (dog) distance=0.2345#2 -> dog3.png (dog) distance=0.2411#3 -> dog2.png (dog) distance=0.2503#4 -> cat2.png (cat) distance=0.3128จะเห็นว่าระบบสามารถค้นหารูปภาพ “สุนัข” กลับมาได้อย่างแม่นยำ โดยจัดอันดับตามค่า distance ที่น้อยที่สุด (คล้ายที่สุด) ก่อน และรูป “แมว” ก็จะถูกจัดอันดับไว้ท้ายๆ เพราะความหมายมัน “ไกล” กว่านั่นเอง
สรุปจาก Demo ที่ 3
เดโมนี้แสดงให้เห็นว่า Vector Database อย่าง ChromaDB ไม่ได้ถูกจำกัดอยู่แค่โลกของข้อความอีกต่อไป แต่เป็นเครื่องมือพื้นฐานที่ทรงพลังสำหรับแอปพลิเคชัน AI ทุกรูปแบบ:
- จัดการข้อมูลได้หลากหลาย (Versatility): หลักการเดียวกันสามารถประยุกต์ใช้ได้กับทั้งข้อความ, รูปภาพ, เสียง หรือข้อมูลใดๆ ที่สามารถแปลงเป็น Vector ได้
- ค้นหาข้ามรูปแบบ (Cross-Modal Search): เราสามารถใช้ข้อมูลรูปแบบหนึ่ง (ข้อความ) เพื่อค้นหาข้อมูลอีกรูปแบบหนึ่ง (รูปภาพ) ได้อย่างง่ายดาย เปิดประตูสู่ความเป็นไปได้ใหม่ๆ มากมาย
- Abstraction ที่ทรงพลัง: ChromaDB จัดการความซับซ้อนของการโหลดและแปลงข้อมูลให้เราเบื้องหลัง ทำให้เราสามารถโฟกัสกับการสร้างสรรค์แอปพลิเคชันที่ฉลาดและตอบโจทย์ผู้ใช้ได้ดียิ่งขึ้น
-

- Code Quality & Security with SonarQubeมี Video
แนะนำพื้นฐานการทำ Sonarqube Code พร้อม Code Quality & Security

- รู้จักกับ Web Vitals guideline การสร้าง UX ที่ดีออกมากันมี Video
รู้จักกับคำศัพท์พื้นฐานของ Web Vitals และ use case ต่างๆของ Web Vitals กัน

- มาแก้ปัญหา Firestore กับปัญหาราคา Read pricing สุดจี๊ดมี Video มี Github
ในฐานะที่เป็นผู้ใช้ Firebase เหมือนกัน เรามาลองชวนคุยกันดีกว่า ว่าเราจะสามารถหาวิธีลด Pricing หรือจำนวนการ read ของ Firestore ได้ยังไงกันบ้าง
