

LLM Local and API
/ 7 min read
 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
LLM คืออะไร
LLM หรือ Large Language Model คือ โมเดลปัญญาประดิษฐ์ (AI) ประเภทหนึ่งที่ได้รับการฝึกฝนจากข้อมูลข้อความจำนวนมหาศาล ทำให้มีความสามารถในการประมวลผลและเข้าใจภาษาธรรมชาติได้อย่างลึกซึ้ง โดย LLM สามารถนำไปประยุกต์ใช้ได้หลากหลาย เช่น การแปลภาษา การสร้างเนื้อหา การตอบคำถาม และการสนทนาโต้ตอบกับมนุษย์ได้อย่างเป็นธรรมชาติ
บทบาทของ LLM ในฐานะ AI มีดังนี้
- การสร้างเนื้อหา: LLM สามารถสร้างเนื้อหาได้หลากหลายรูปแบบ เช่น บทความ, บทกวี, code หรือ script program
- การแปลภาษา: LLM สามารถแปลภาษาได้เป็นธรรมชาติมากกว่า translation ทั่วไป
- การตอบคำถาม: LLM สามารถตอบคำถามที่ซับซ้อนได้ โดยสามารถดึงข้อมูลจากแหล่งข้อมูลขนาดใหญ่ได้
- การสนทนาโต้ตอบ: LLM สามารถสนทนาโต้ตอบกับมนุษย์ได้
- การวิเคราะห์ข้อมูล: LLM สามารถวิเคราะห์ข้อมูลที่เป็นข้อความจำนวนมากได้อย่างมีประสิทธิภาพ ช่วยในการค้นหาข้อมูลเชิงลึกและแนวโน้มที่สำคัญออกมาได้
- การสร้างสรรค์: LLM สามารถนำมาใช้ในการสร้างสรรค์ผลงานศิลปะต่างๆ เช่น ภาพวาด ดนตรี และบทกวี เป็นต้น
หากใครต้องการฟัง LLM หรือรู้จัก LLM เชิงลึก ขอแนะนำให้ย้อนกลับไปฟังหัวข้อ “LLM (Generative AI) คืออะไร ?” ของช่อง Mikelopster ก่อนที่จะไปกันต่อนะครับ เพื่อเติมเต็มความเข้าใจความสัมพันธ์ระหว่าง Large Language Model กับ “ผลลัพธ์ที่ได้ออกมา” มากยิ่งขึ้น
LLM on local คืออะไร
LLM on local หมายถึง การรัน LLM บนเครื่องคอมพิวเตอร์หรืออุปกรณ์ของผู้ใช้เอง แทนที่จะใช้บริการ LLM ผ่านคลาวด์จากผู้ให้บริการรายอื่น เช่น OpenAI หรือ Google
ประโยชน์ของ LLM on device
- ความเป็นส่วนตัว: ข้อมูลของผู้ใช้จะไม่ถูกส่งออกไปภายนอก ทำให้มีความปลอดภัยและเป็นส่วนตัวมากขึ้น
- การตอบสนองที่รวดเร็ว: การประมวลผลบนอุปกรณ์ช่วยลดความล่าช้าในการตอบสนองระหว่าง server ไปมาได้
- การทำงานแบบออฟไลน์: ผู้ใช้สามารถใช้งาน LLM ได้แม้ไม่มีการเชื่อมต่ออินเทอร์เน็ต
- ไม่มีค่าใช้จ่าย: ผู้ใช้ไม่จำเป็นต้องเสียค่าบริการในการใช้งาน LLM เนื่องจากสามารถรันได้ฟรีบนเครื่องของตนเอง
ความท้าทายของ LLM on device
- ข้อจำกัดของทรัพยากร: Device ใดๆก็ตาม มีข้อจำกัดด้านทรัพยากรในการประมวลผล เช่น หน่วยความจำและ processor ซึ่งอาจทำให้ประสิทธิภาพของ LLM ลดลงได้
- ขนาดโมเดล: LLM มักมีขนาดใหญ่ ทำให้ต้องใช้พื้นที่เก็บข้อมูลมากบนอุปกรณ์
- ความซับซ้อน: การติดตั้งและใช้งาน LLM on local อาจมีความซับซ้อนกว่าการใช้บริการ LLM ผ่าน cloud ผู้ใช้อาจจำเป็นต้องมีความรู้ด้าน technical บ้างเพื่อทำการติดตั้งและกำหนดค่าต่างๆภายใน LLM
ทีนี้ หลายคนก็อาจจะสงสัยว่า แล้วมันสามารถ run ได้อย่างไร ? การรัน LLM on local สามารถทำได้หลายวิธี โดยวิธีที่ได้รับความนิยมและเข้าใจง่ายดังนี้ครับ
- ใช้ library หรือ framework
- LangChain: เป็น framework ที่ช่วยให้การพัฒนา application ที่ใช้ LLM ง่ายขึ้น โดยมีเครื่องมือสำหรับการจัดการ model การดึงข้อมูล และการสร้าง chain สำหรับงานต่างๆ (เราจะยังไม่เจาะลึกกันในบทความนี้ เราจะหยิบมาเล่ากันในอนาคตแน่นอน)
- Ollama เป็น framework สำหรับรัน Large Language Model (LLM) บนเครื่อง local อีกตัวหนึ่ง (ที่เดี๋ยวเราจะมาเล่นกันในบทความนี้กัน)
- ใช้ Docker
Docker ช่วยให้สามารถสร้างและรัน application ใน enrironment ที่แยกออกมา ทำให้การติดตั้งและใช้งาน LLM on local ง่ายขึ้น โดยมี Docker image สำเร็จรูปสำหรับ LLM หลายตัว เช่น GPT4All, Alpaca-LoRA, Vicuna, Ollama เป็นต้น
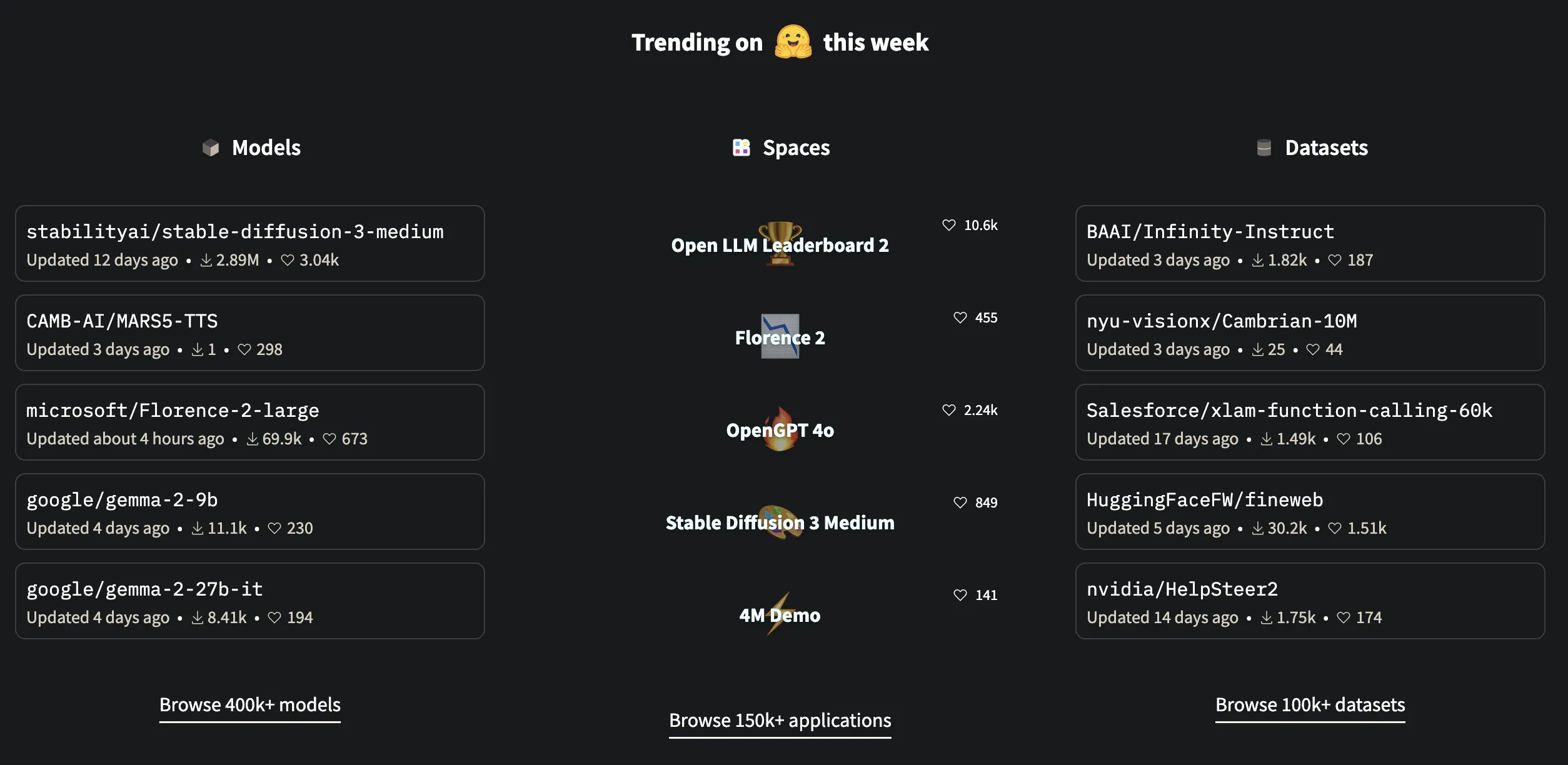
โดยการหา LLM ที่มาทดลองใช้นั้น เราขอแนะนำสถานที่ๆ เก็บเหล่า LLM ให้ทดลองไว้จำนวนมากได้ นั่นก็คือ Hugging Face กัน
Hugging Face คืออะไร
Hugging Face (https://huggingface.co/) คือ Platform และ community สำหรับการพัฒนาและใช้งาน model Machine Learning โดยเฉพาะอย่างยิ่งในด้าน Natural Language Processing (NLP) ซึ่งรวมถึง Large Language Model (LLM) ด้วย
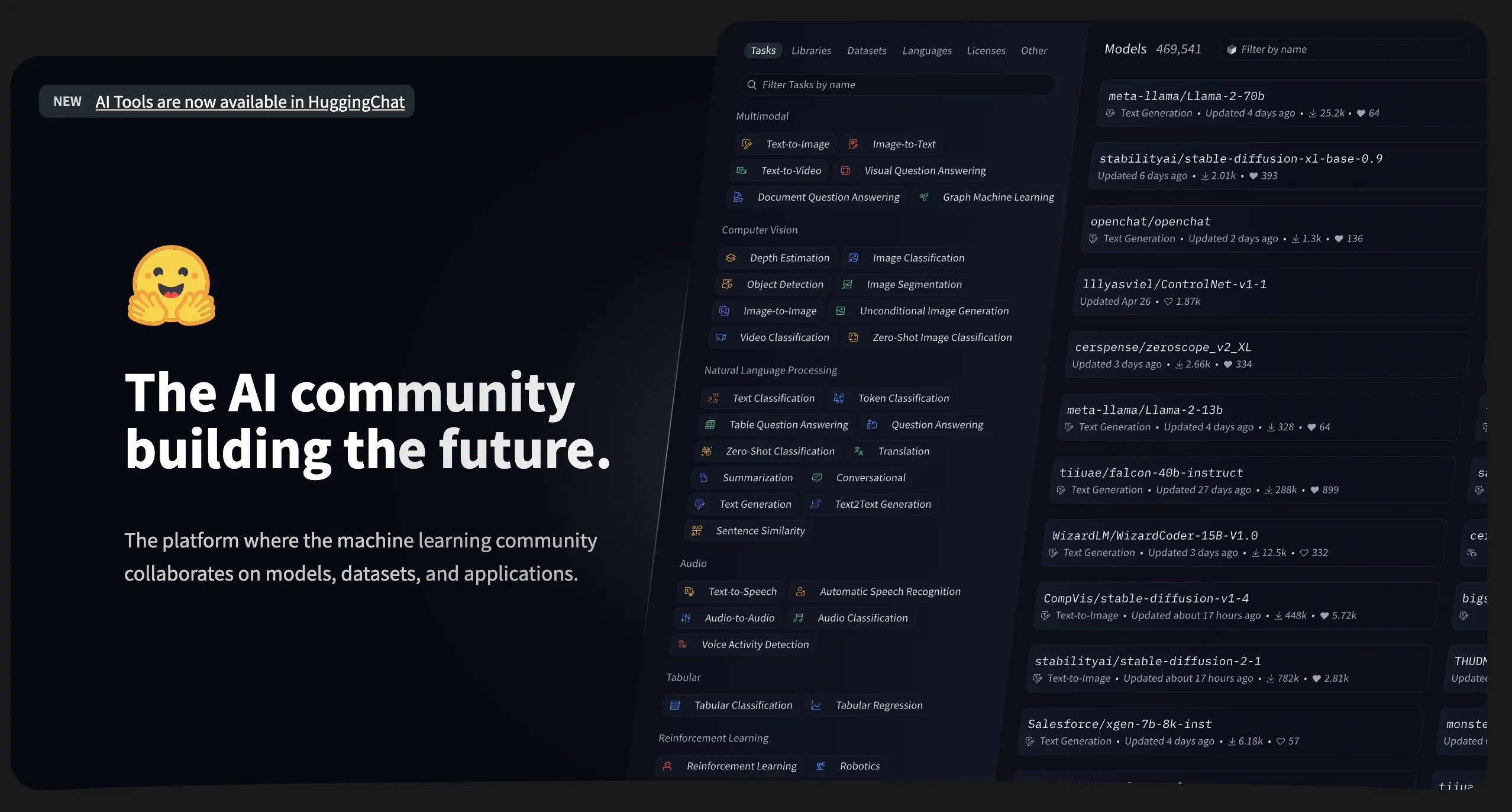
สิ่งที่ Hugging Face มีเกี่ยวกับ LLM
- แหล่งรวม Model: Hugging Face เป็นแหล่งรวม model LLM open source ที่ใหญ่ที่สุดแห่งหนึ่ง มีโมเดลให้เลือกใช้งานมากมาย เช่น LLaMA, Alpaca, GPT-J, Bloom และอื่นๆ อีกมากมาย
- เครื่องมือสำหรับใช้งาน LLM: Hugging Face มีเครื่องมือและ library ที่ช่วยให้การใช้งาน LLM ง่ายขึ้น เช่น Transformers ซึ่งเป็น library ที่ได้รับความนิยมอย่างมากในการพัฒนา application NLP
- Spaces: Hugging Face Spaces เป็น platform สำหรับการสาธิตและทดลองใช้งาน model LLM ได้อย่างง่ายดาย โดยไม่ต้องติดตั้งหรือเขียน code เอง (แหล่งรวมไอเดียชั้นดีอีกที่หนึ่ง)
- Datasets: Hugging Face ยังเป็นแหล่งรวม datasets ที่ใช้ในการฝึกฝน model LLM ซึ่งเป็นประโยชน์อย่างมากสำหรับนักวิจัยและนักพัฒนา
ทีนี้ เพื่อให้ทุกคนได้สัมผัสประสบการณ์ การใช้งาน LLM on local อย่างง่ายที่แม้จะไม่มีประสบการณ์เขียน program เลยก็สามารถที่จะลองเล่นได้ เราขอแนะนำเครื่องมือหนึ่ง ที่สามารถทำให้ใช้งาน LLM บนเครื่องของเราเองได้ง่ายเหมือนกับใช้งาน chat application ทั่วไป นั่นคือ “LM Studio”
LM Studio (https://lmstudio.ai/) คือ application ที่ช่วยให้คุณสามารถรัน LLM ต่างๆ จาก Hugging Face บนเครื่องคอมพิวเตอร์ของคุณได้อย่างง่ายดาย
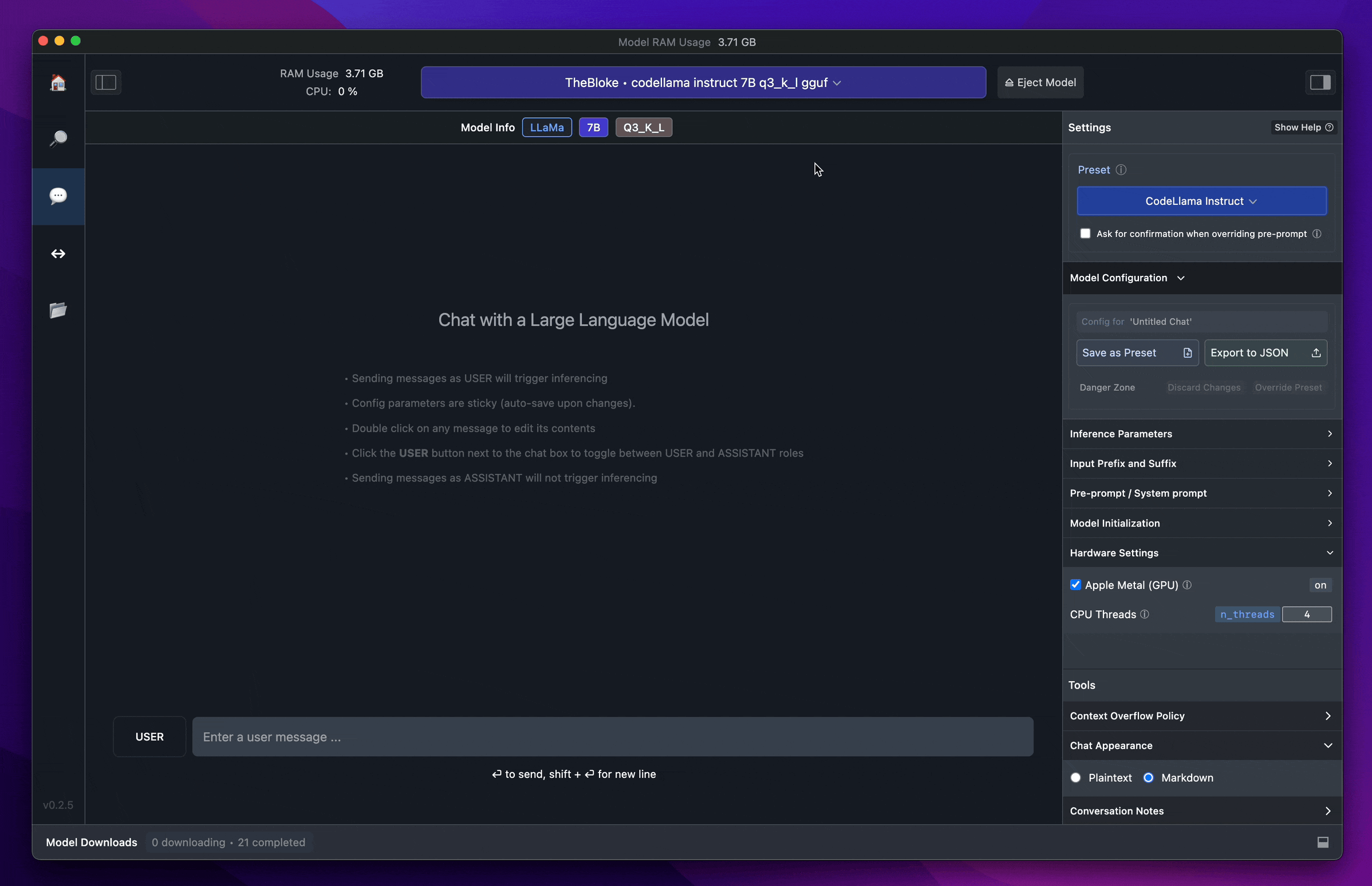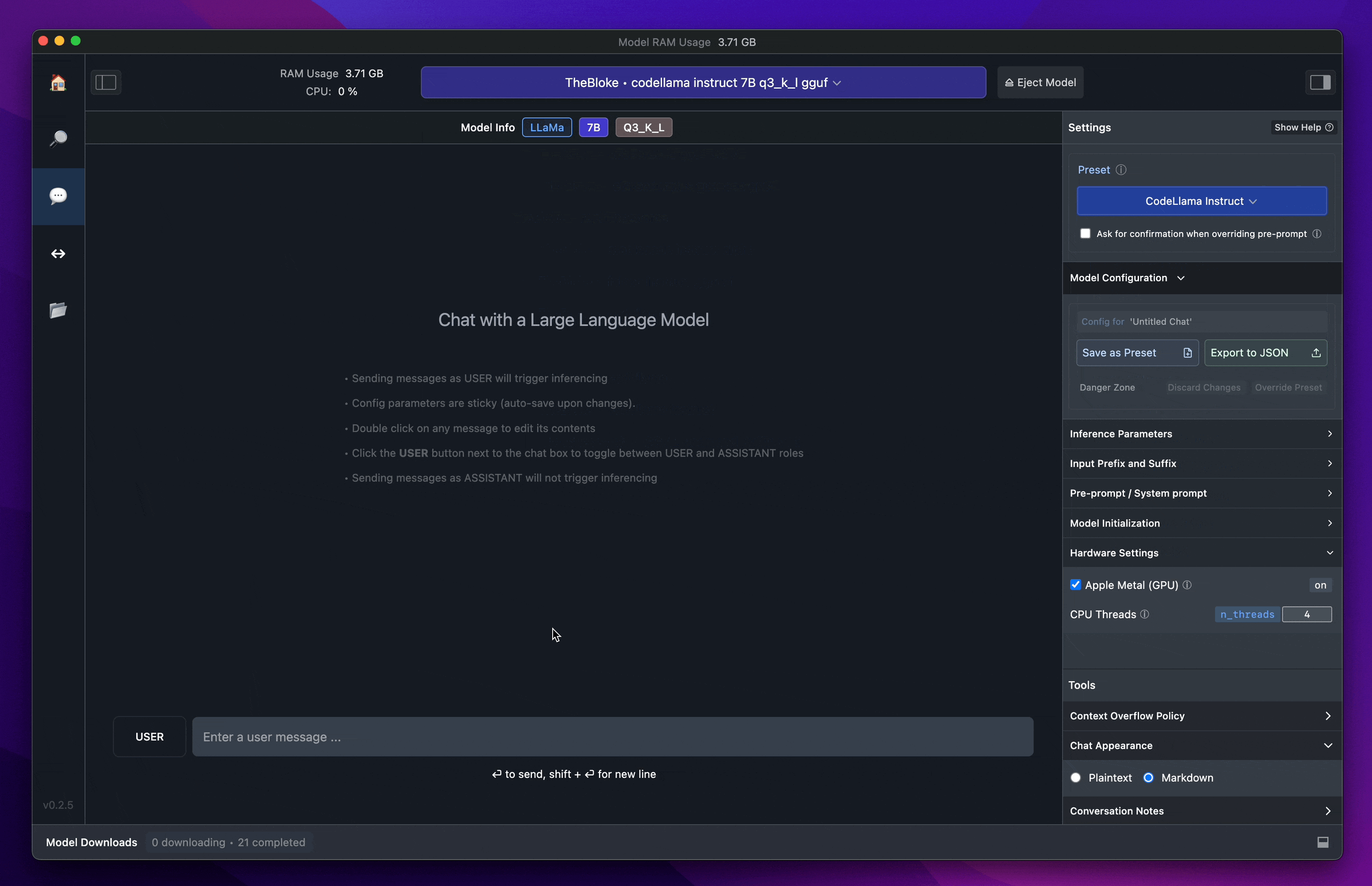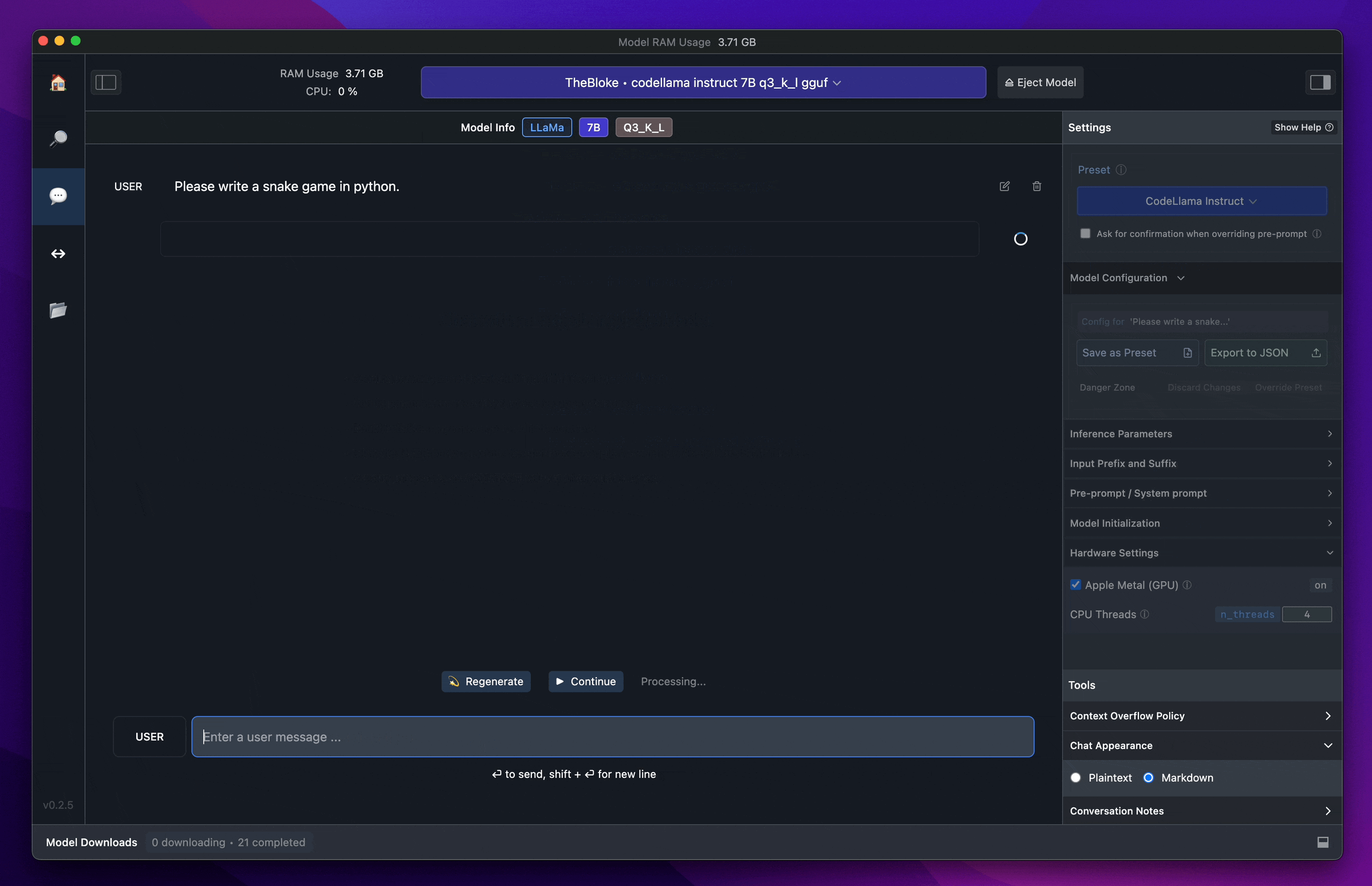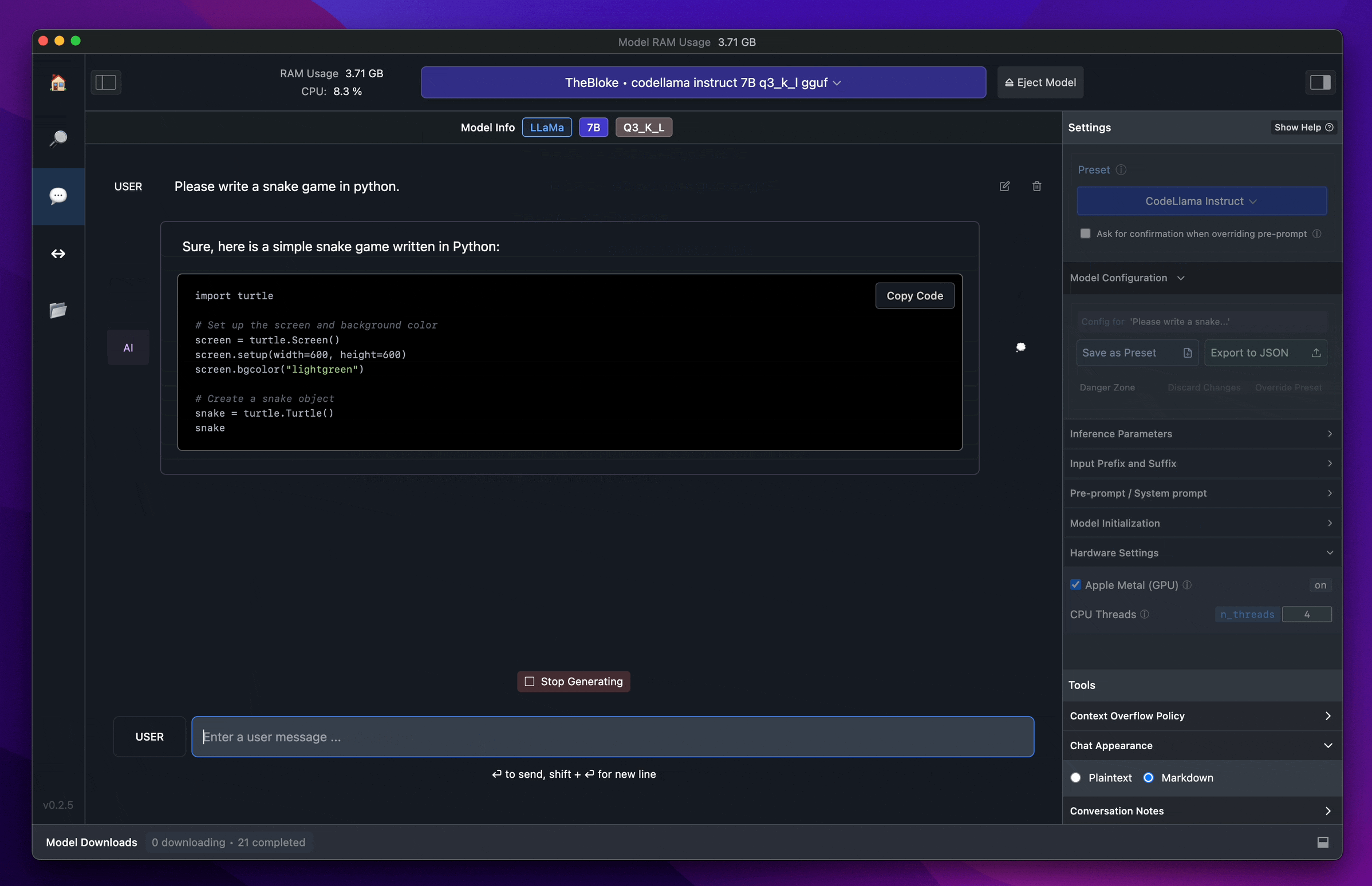
คุณสมบัติหลักของ LM Studio:
- ใช้งานง่าย: มี interface ที่ใช้งานง่าย ไม่จำเป็นต้องเขียนโค้ด
- รองรับ model หลากหลาย: สามารถใช้งานกับโมเดล LLM ต่างๆ จาก Hugging Face ได้ เช่น LLaMA, Alpaca, Vicuna, GPT4All และอื่นๆ
- ปรับแต่งได้: สามารถปรับแต่งโมเดลให้เหมาะกับความต้องการของคุณได้
- ฟรี: สามารถใช้งานได้ฟรีสำหรับการใช้งานส่วนบุคคล
ทุกคนสามารถลองไป download เล่นดูผ่านหน้าเว็บ LM Studio ได้ โดยในหัวข้อนี้ เราจะลองหยิบ Gemma หนึ่งใน LLM open source ของ Google มาลองเล่นกัน โดย LM Studio ก็จะมีหน้าให้เลือก Searh Model ได้เลย (ซึ่งก็อ้างอิงตาม LLM ที่มีใน hugging face นั่นแหละ) โดยมันจะมีการระบุเอาไว้เลยว่า spec ขั้นต่ำต้องการ RAM เท่าไหร่ (ถ้า RAM ไม่พอบอกเลยว่ารันไม่ขึ้นนะครับ)
เมื่อโหลดเสร็จแล้ว ให้ลองมาที่หน้า chat > เลือก Model (ในที่นี่เราโหลดเป็น Gemma มา) และทำการลอง chat กับ Gemma ดู
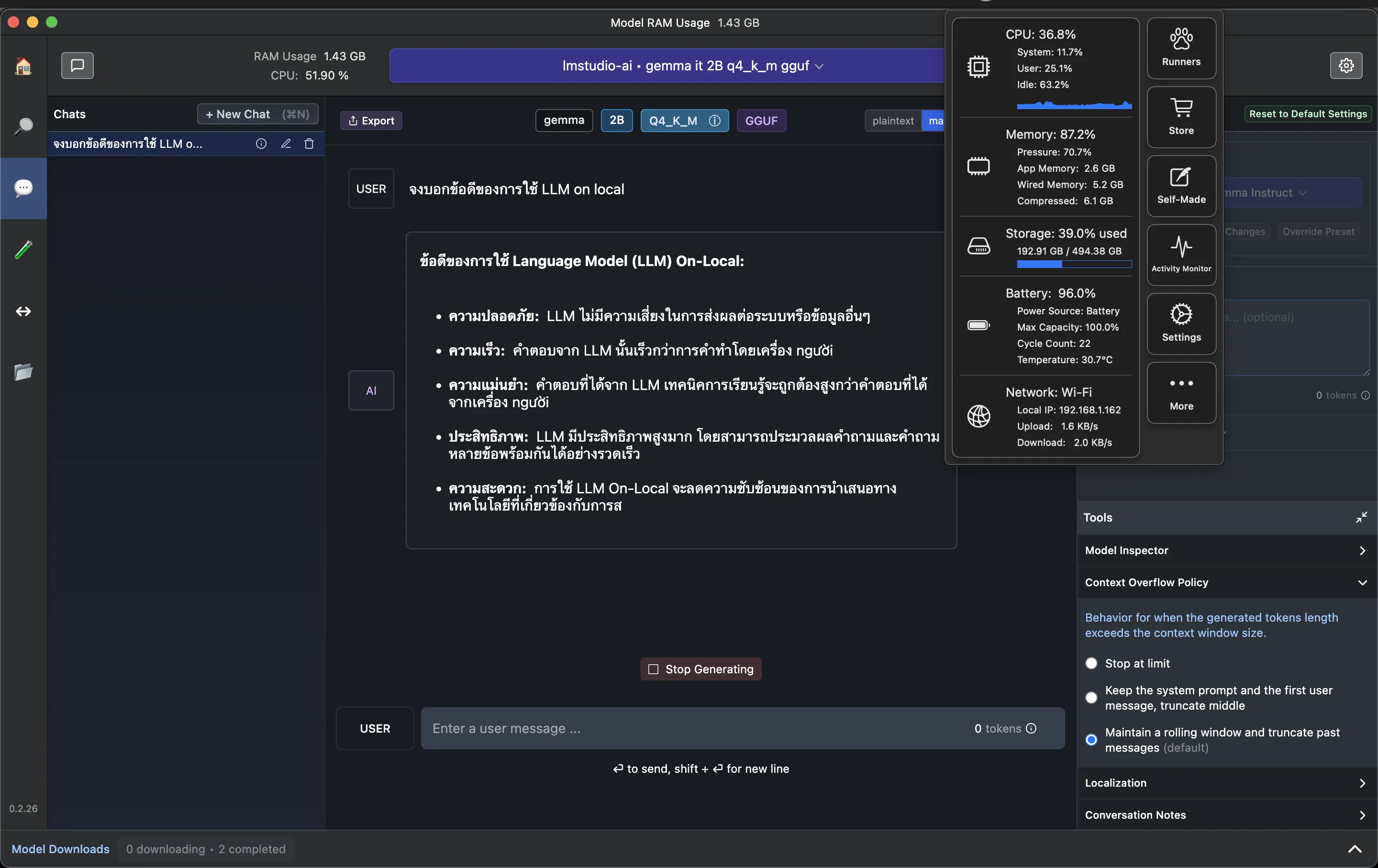
สังเกตว่า เราก็จะสามารถใช้งานได้เหมือนเรากำลังคุย chat กับ LLM ทั่วไปได้เลย แต่อย่างที่เราเล่าไปตอนแรก “นี่คือการ run LLM on local” ซึ่งหมายถึงเครื่อง computer ของเราเอง ซึ่งพวก LLM มันคือการประมวลผลจำนวนมหาศาลมาก (มากน้อยขนาดไหนขึ้นอยู่กับขนาด Model) สังเกตว่ามันก็จะกินทั้ง process และ RAM ของเครื่องเราไปด้วย (อย่างภาพตัวอย่างนี้ กิน ram ไปราวๆ 80 กว่า % ของเครื่องเลย)
ดังนั้น การหยิบ Model LLM มาใช้ นอกเหนือจากการนำมา run บน local แล้ว อีกวิธีที่เราสามารถทำได้คือ “การนำมันเป็น run บน Server ของเราเอง” เช่น นำไปวางบน Cloud ของเราเอง ซึ่งก็จะช่วยทำให้เราสามารถขยายทรัพยากรมากกว่าเครื่องของเราออกไปได้ เราเลยจะพาทุกคน Next step ไปกันต่อ ด้วยการทำให้เราสามารถ run LLM จาก “ที่ไหนก็ได้” ด้วยแนวทางของ programming กัน เราจะขอพาทุกคนมารู้จักกับ Ollama กัน
รู้จักกับ Ollama
Ollama (https://ollama.com/) คือ framework แบบ open-source ที่ช่วยให้คุณสามารถรัน LLM ต่างๆ บนเครื่องได้
จุดเด่นของ Ollama:
- รองรับโมเดลหลากหลาย: Ollama รองรับโมเดล LLM ยอดนิยมมากมาย เช่น LLaMA 3, Phi 3, Mistra, Gemma 2 และอื่นๆ
- มี CLI
- รวมถึงลงได้หลากหลาย platform ตั้งแต่ Mac, Linux, Windows, Docker รวมถึง library ที่ support กับ python หรือ javascript ด้วยนะ
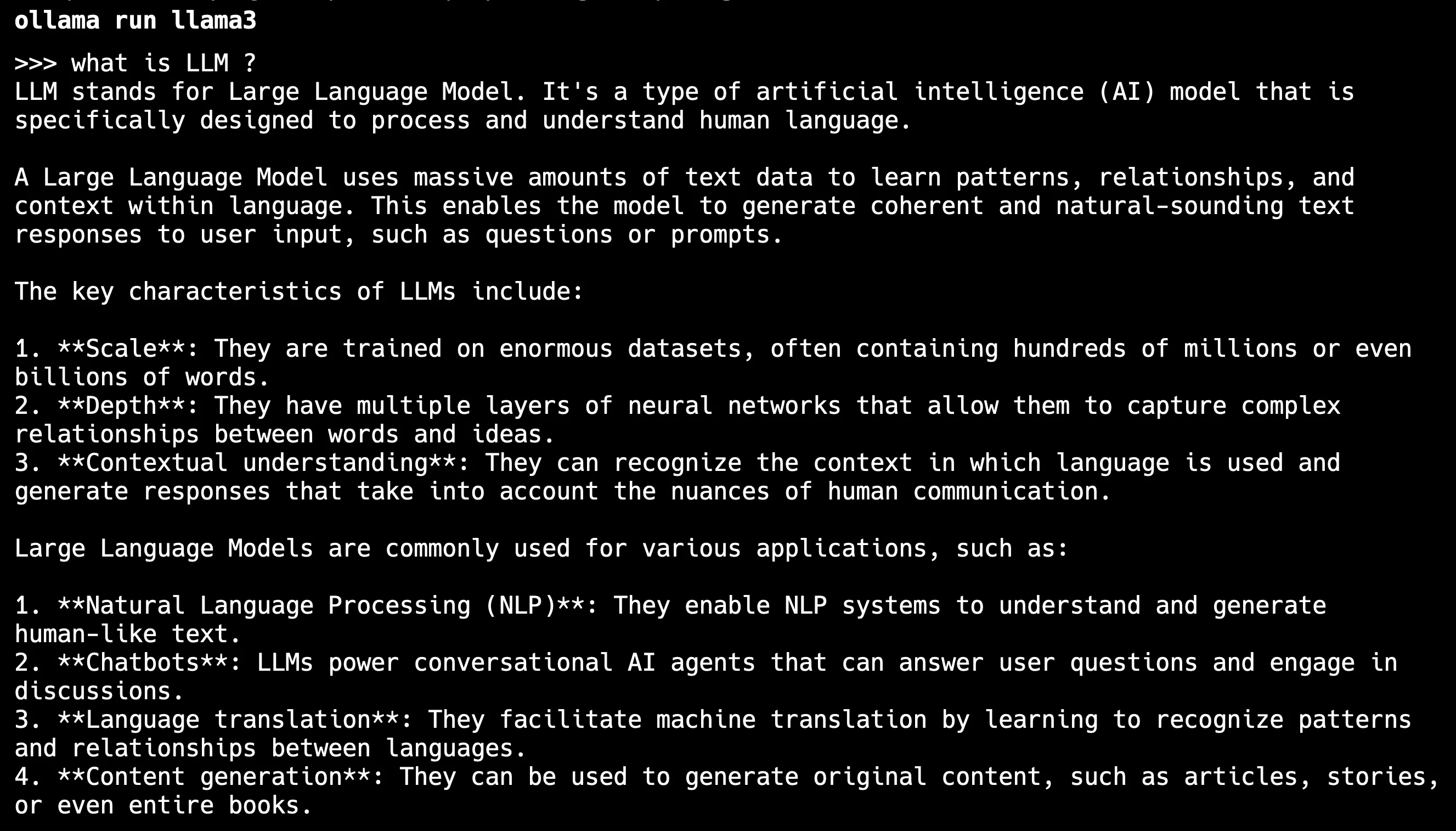
ทีนี้เราจะมาทดลอง way ง่ายที่สุดก่อนนั่นคือ เราจะลองลง ollama ที่เครื่องก่อนแล้วลองใช้งานผ่าน CLI กัน สามารถ Download มาลงได้เหมือน program ทั่วไป เมื่อลงเสร็จแล้ว ก็สามารถใช้งานได้ผ่านคำสั่ง CLI ของ ollama ได้เลย โดยในตัวอย่างนี้เราจะเรียกใช้งานผ่าน Model Llama3 ขึ้นมา ก็สามารถใช้งานผ่านคำสั่ง ollama tun llama3 ได้เลย
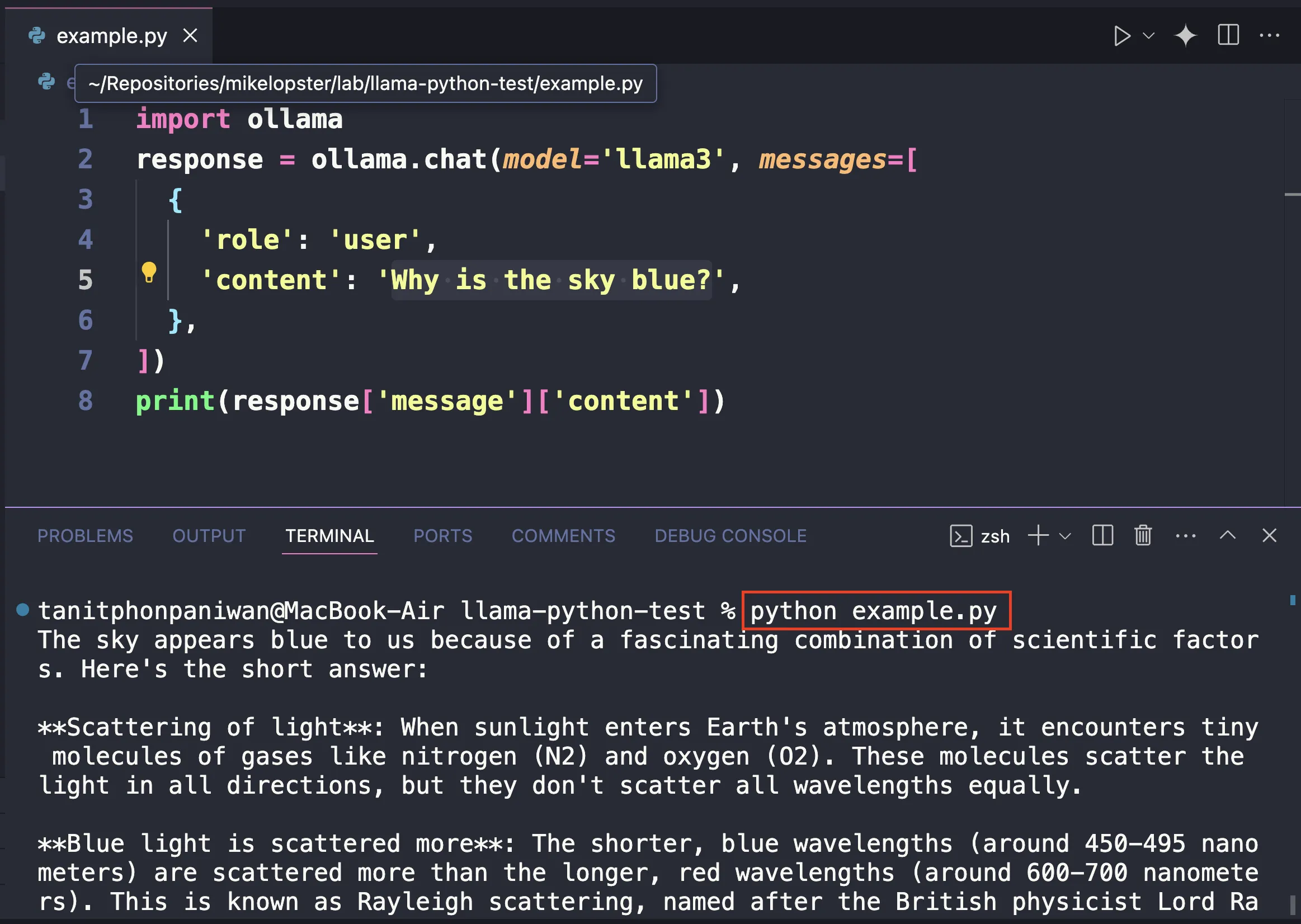
ทีนี้ อย่างที่เราเล่าตอนแรก เราอยากให้การ run LLM นี้เกิดขึ้นที่ไหนก็ได้ ดังนั้น เราจะเปลี่ยนวิธีการ run LLM จากแต่เดิมที่ทำผ่าน CLI เราจะเปลี่ยนมาเรียกผ่านคำสั่งของ Python (ซึ่งหากเราใช้วิธีนี้ได้ = เราสามารถนำไป run ที่ไหนก็ได้ที่สามารถ run python ได้ = หากเรา run ด้วย docker และ run ด้วยภาษา python เราก็จะสามารถ run เจ้า LLM ตัวนี้จากที่ไหนก็ได้นั่นเอง)
โดยเราสามารถลองได้ผ่าน code ของ github นี้เลย https://github.com/ollama/ollama-python เมื่อเราลองทำการลง package ลอง python และทำการลอง run ตัวอย่างตาม เราก็จะค้นพบว่า เราสามารถนำ llama3 มา run บน python ได้แล้ว !
ลองมาประยุกต์ทำเป็น API แทน
ทีนี้ เพื่อเราสามารถนำไปประยุกต์ใช้ใน application อื่นๆได้ เรามาลองเปลี่ยนการเรียก Ollama จากแต่เดิมที่เราใช้ผ่านการ run python เป็นการ run เป็น web service แบบ API ออกมาแทน
โดยเราจะใช้ framework ตัวหนึ่งที่ช่วยทำให้ python สามารถ run web server ขึ้นมาได้นั่นก็คือ FastAPI นั่นเอง
FastAPI (https://fastapi.tiangolo.com/) web framework สำหรับการสร้าง API ด้วยภาษา Python โดยใช้ประโยชน์จากมาตรฐาน Python type hints และ async/await ทำให้การพัฒนา API รวดเร็ว ง่าย และมีประสิทธิภาพสูงออกมาได้
โดยจุดเด่นของ FastAPI คือ
- ประสิทธิภาพสูง: FastAPI ขึ้นชื่อเรื่องความเร็วในการทำงานเทียบเท่ากับ NodeJS และ Go
- พัฒนาได้อย่างรวดเร็ว: ช่วยลดเวลาในการพัฒนา API ลงอย่างมาก (code ใกล้เคียงกับพวก express ที่ชาว node.js คุ้นเคย)
- ลดข้อผิดพลาด: การใช้ type hints ช่วยตรวจสอบข้อผิดพลาดได้ตั้งแต่เนิ่นๆ ทำให้ลดข้อผิดพลาดจากฝั่งผู้พัฒนา
- Automatic Documentation: สร้างเอกสาร API แบบ interactive (Swagger UI และ Redoc) ได้โดยอัตโนมัติ
ยกตัวอย่าง code FastAPI สำหรับ get แสดงข้อมูล เช่นแบบนี้ เป็น 2 API สำหรับ return ข้อความและรับ parameters ก็จะได้ API Code หน้าตาประมาณนี้มา
from fastapi import FastAPI
app = FastAPI() # Create the FastAPI application instance
@app.get("/") # Define a GET endpoint at the root path ("/")def read_root(): return {"message": "Hello from FastAPI!"} # Return a JSON response
@app.get("/items/{item_id}") # Define a GET endpoint with a path parameterdef read_item(item_id: int): # Type hint for the path parameter return {"item_id": item_id}ตอนลงเพื่อให้ใช้งาน FastAPI ได้ ก็จะทำการลง package เหล่านี้
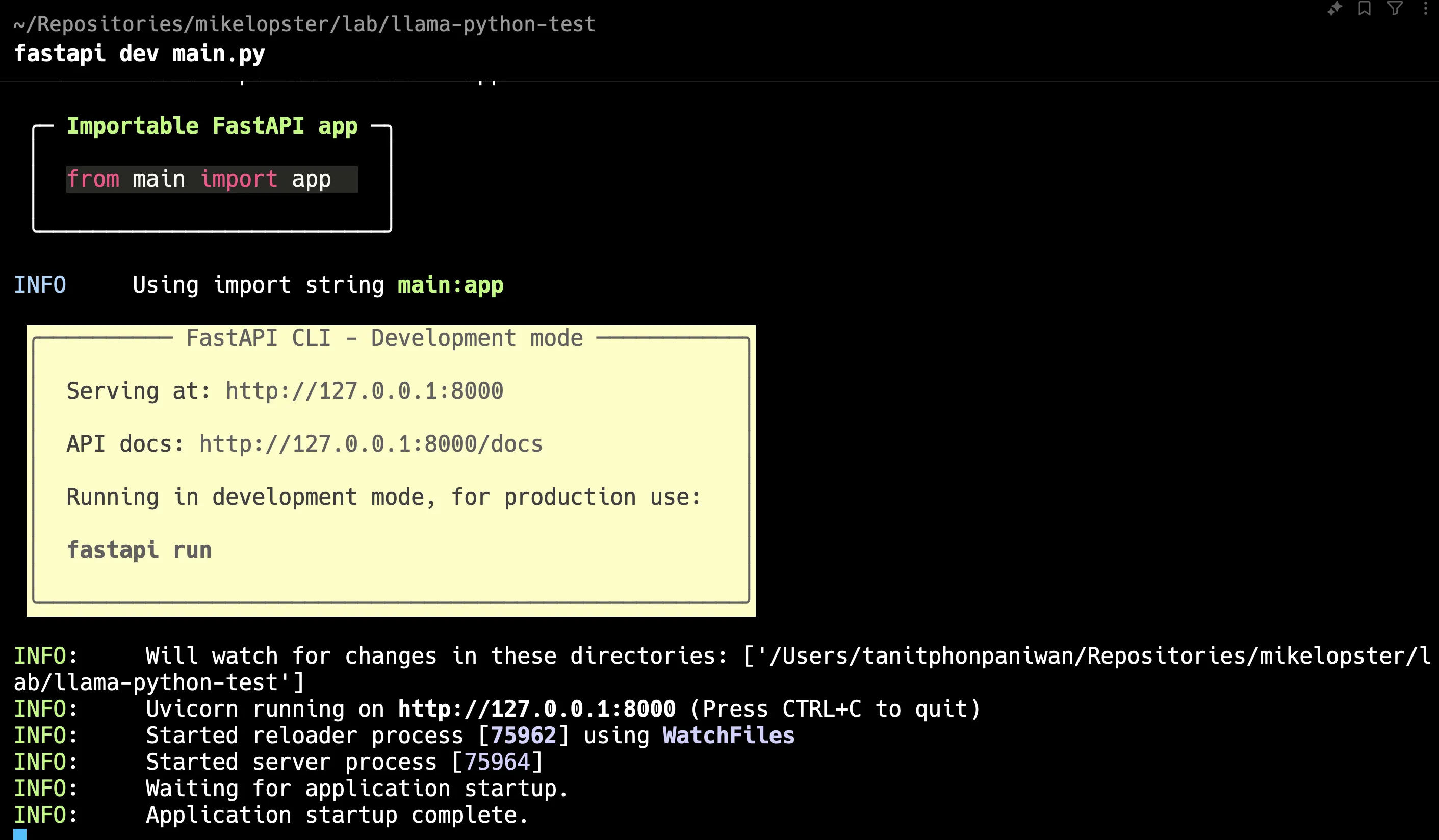
pip install fastapiเมื่อเราลอง run ด้วยคำสั่ง
fastapi dev main.pyสังเกตว่า เราก็จะได้ Web server ที่ port 8000 ออกมาได้
เมื่อเราลองเรียกผ่าน Postman ก็จะสามารถได้ response ตามที่เขียนใน code ไว้ได้
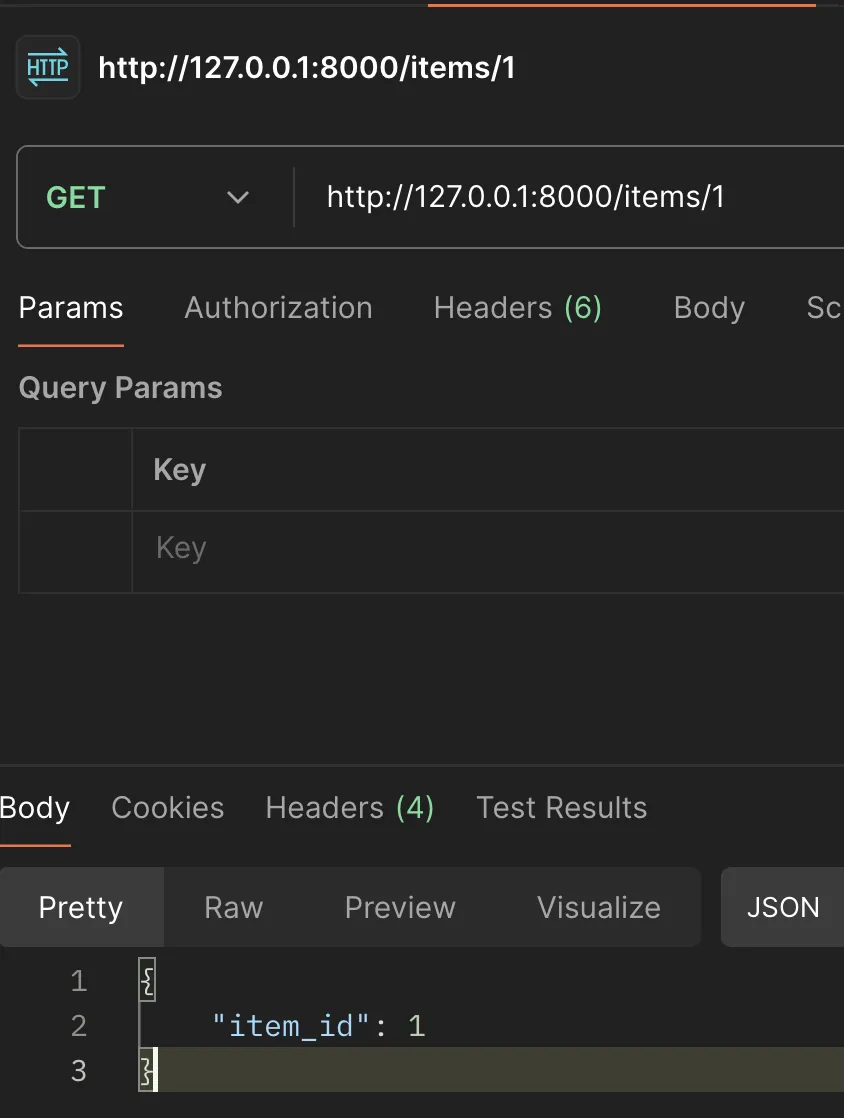
(สำหรับใครสนใจหัวข้อ FastAPI ฉบับเต็ม comment กันไว้ได้นะครับ 😆)
ทีนี้ เราลองนำ FastAPI มาประยุกต์ใช้กับ Ollama ก็จะได้ code ประมาณนี้ออกมา
from fastapi import FastAPI, Request, HTTPExceptionimport ollama
app = FastAPI()
@app.post("/ask")async def ask_question(request: Request): try: # 1. Get input from the request body (FastAPI handles JSON parsing) input_data = await request.json() if not input_data or "question" not in input_data: raise HTTPException( status_code=400, detail="Invalid input format. Please provide 'question' in the request body.")
# 2. Use the provided question or the default question = input_data.get("question", "Who are you")
response = ollama.chat(model='llama3', messages=[ { 'role': 'user', 'content': question, }, ])
# Extract text from CompletionResponse response_text = response['message']['content'] # 4. Return the response as JSON return {"response": response_text} except Exception as e: # 5. Basic error handling (FastAPI's HTTPException for better structure) raise HTTPException(status_code=500, detail=str(e))เมื่อเราลอง run web server และลองส่ง prompt คำถามเข้าไป เราก็จะได้ผลลัพธ์เป็น LLM + API ที่สามารถใช้งานผ่าน web server ออกมาได้
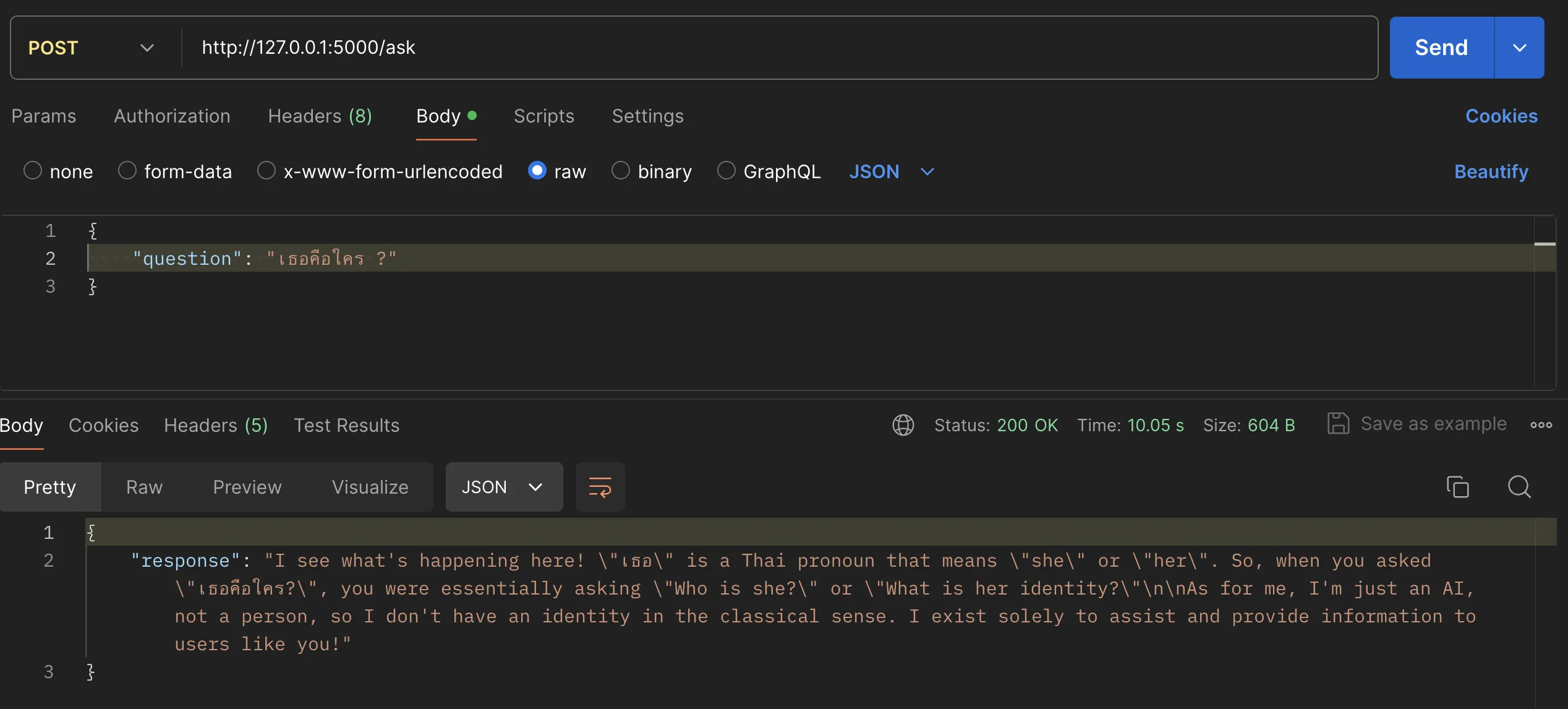
ลองเพิ่มตัวอย่างตาม Prompt Engineer Guide
ทีนี้ เพื่อลองเพิ่มลูกเล่นของการใช้งาน API + LLM ดู เราจะลองเพิ่มความสามารถของ API โดยการปรับแต่ง prompt ไป โดยใช้ technique ที่ชื่อ Few-Shot Prompting
Few-Shot Prompting เป็นเทคนิคหนึ่งใน Prompt Engineering ที่ใช้ในการปรับแต่งและควบคุมการทำงานของ LLM โดยหลักการคือ
- เราจะใส่ตัวอย่าง input-output ที่ต้องการลงไปใน prompt ที่ส่งให้ model
- ตัวอย่างเหล่านี้จะทำหน้าที่เป็น “demonstrations” หรือ “ตัวอย่าง” ที่สอน model ให้เข้าใจรูปแบบและวิธีการตอบสนองที่เราต้องการ
- model จะเรียนรู้จากตัวอย่างเหล่านี้และพยายามเลียนแบบรูปแบบเมื่อได้รับ input ใหม่ที่คล้ายคลึงกันออกมาได้
เช่นตัวอย่างนี้
from fastapi import FastAPI, Request, HTTPExceptionimport ollama
app = FastAPI()
@app.post("/ask")async def ask_question(request: Request): try: input_data = await request.json() if not input_data or "question" not in input_data: raise HTTPException( status_code=400, detail="Invalid input format. Please provide 'question' in the request body.")
question = input_data.get("question", "Who are you")
# Few-Shot Prompting Example prompt = f"""User: What is the capital of France?Assistant: Paris
User: What is the highest mountain in the world?Assistant: Mount Everest
User: {question}Assistant: """ # The model will fill in the answer here
response = ollama.chat(model='llama3', messages=[ { 'role': 'system', # Provide the prompt as system instruction 'content': prompt, } ])
response_text = response['message']['content'] return {"response": response_text}
except Exception as e: raise HTTPException(status_code=500, detail=str(e))จากตัวอย่างนี้
-
เราได้เพิ่มตัวอย่างคำถามและคำตอบที่เกี่ยวข้อง (เกี่ยวกับเมืองหลวงและภูเขา) ลงใน prompt ที่ส่งไปยัง Ollama Model สิ่งนี้ทำหน้าที่เป็น “few shots” (ตัวอย่างเล็กๆ) ที่สอน Model ถึงรูปแบบที่เราต้องการให้ตอบ
-
เราใช้ role เพิ่มเพื่อส่ง prompt นี้ไป ทำให้ model เข้าใจว่านี่คือคำแนะนำในการตอบคำถาม ไม่ใช่คำถามจากผู้ใช้ (user)
system
และ นี่คือ ผลลัพธ์ของการที่เราพยายามกรอบเอาไว้ สังเกตว่า มันก็จะไม่พ่นคำตอบฟุ้งๆออกมาแบบเดิม แต่สามารถตอบคำตอบเฉพาะที่เราต้องการออกมาได้
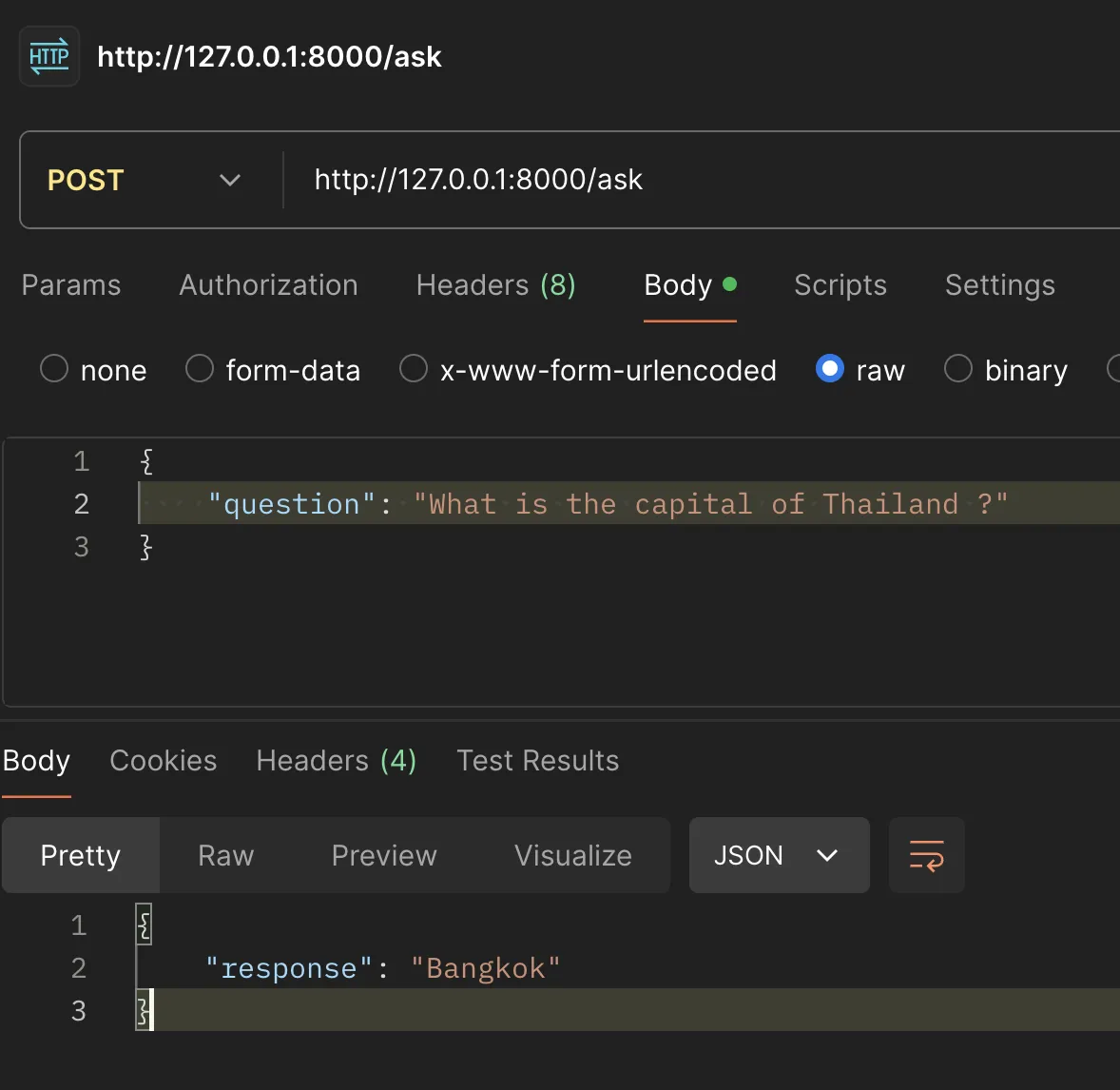
ใครสนใจเทคนิคอื่นๆเพิ่มเติม สามารถอ่านผ่าน https://www.promptingguide.ai/ ได้
เพิ่มเติมการใช้งานร่วมกับ Continue
นอกเหนือจากการใช้ API ร่วมกับการ devlopment ในแง่ product หลายๆตัวเอง ก็ได้นำความสามารถนี้ของ Ollama มาใช้ด้วยเช่นกัน
หนึ่งในนั่นคือ Product ที่ชื่อ Continue AI
Continue ซึ่งเป็นเครื่องมือที่ช่วยในการพัฒนาโปรแกรมโดยใช้ AI เป็นผู้ช่วยในการเขียนโค้ด โดยมีฟีเจอร์หลักๆ
- AI Code Assistant: Continue เป็นผู้ช่วยในการเขียนโค้ดที่สามารถเชื่อมต่อกับโมเดล AI ต่างๆ เพื่อสร้างประสบการณ์การเขียนโค้ดที่มีประสิทธิภาพมากขึ้นใน IDE (Integrated Development Environment) เช่น VS Code และ JetBrains.
- Autocomplete: ฟีเจอร์การเติมโค้ดอัตโนมัติที่สามารถเติมบรรทัดเดียวหรือหลายบรรทัดของโค้ดในภาษาโปรแกรมใดๆ ขณะที่คุณพิมพ์.
- Reference and Chat: ผู้ใช้สามารถแนบโค้ดหรือบริบทอื่นๆ เพื่อถามคำถามเกี่ยวกับฟังก์ชัน ไฟล์ หรือโค้ดเบสทั้งหมด.
- Highlight and Instruct: ผู้ใช้สามารถเน้นส่วนของโค้ดและใช้คีย์บอร์ดชอร์ตคัตเพื่อเขียนโค้ดใหม่จากภาษาธรรมชาติ.
- Customization: Continue สามารถปรับแต่งและเพิ่มประสิทธิภาพได้ตามความต้องการของผู้ใช้.
ใช่ครับ มันคือ Github Copilot ฉบับที่ใช้งานผ่าน LLM API ได้ ไม่ว่าจะเป็นทั้ง Local หรือ Online LLM ขอแค่มี API path และ API Key ก็สามารถที่จะใช้งาน Continue ได้
วิธีการใช้งาน เราจะมาสาธิตผ่าน vscode กัน เราสามารถลงผ่าน Extension ของ VS Code ได้
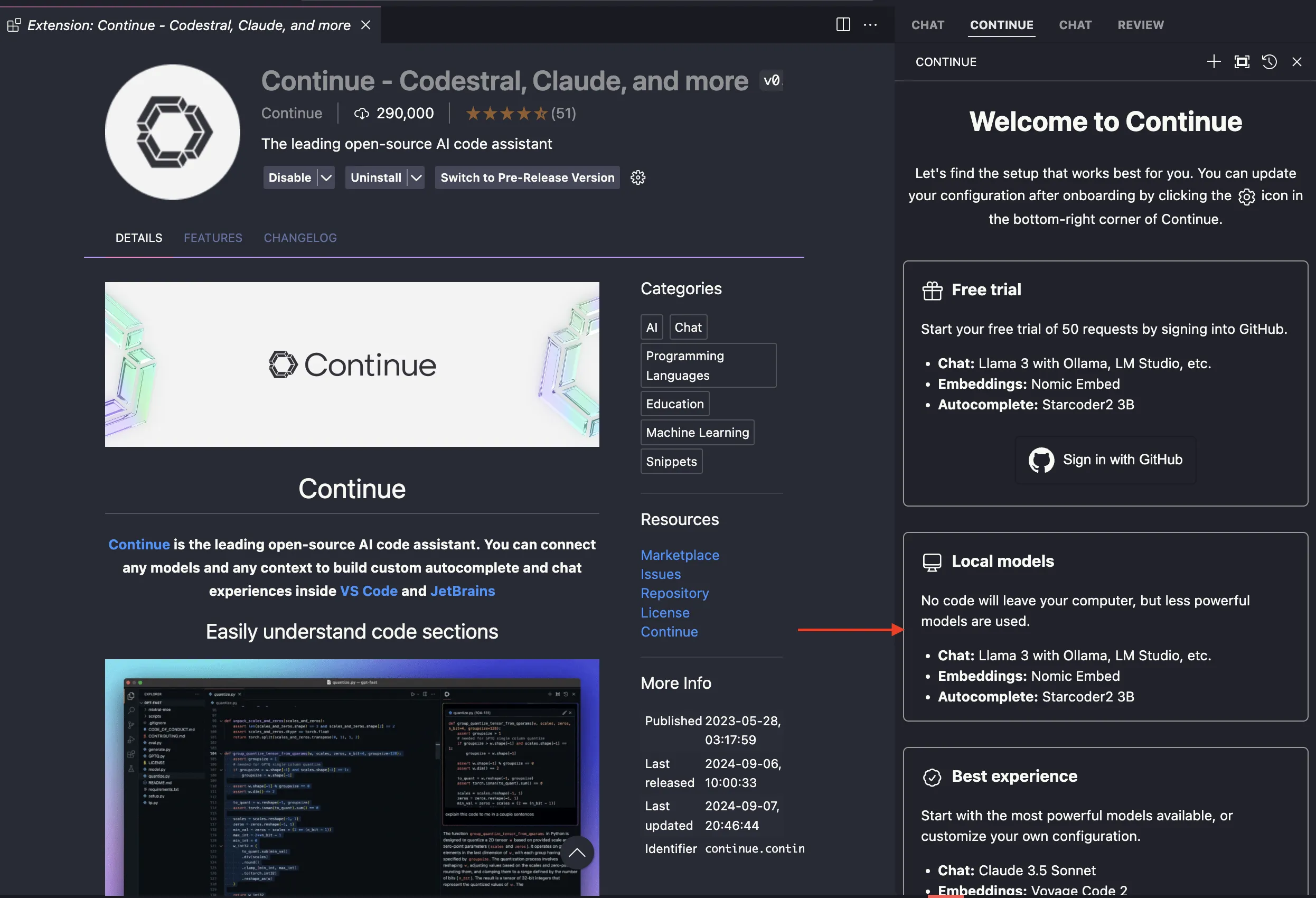
จะสังเกตว่า มันจะมีหลาย model ให้เลือกใช้ และเราจะเจอคำว่า “Local models” ซึ่งมันคือการใช้งาน Continue ร่วมกับ LLM ที่ run local อยู่ผ่าน API บนเครื่องของเราเอง ให้เรากดเลือก ”Local models” และ Continue ต่อได้เลย
โดยแล้วหลังจากที่เลือกเรียบร้อย มันก็จะมีขั้นตอนให้ใช้คำสั่งลงไป เมื่อลงเสร็จก็จะขึ้นเป็นส่วนของช่อง chat ของ continue ที่ vscode ขึ้นมาให้ใช้งานได้
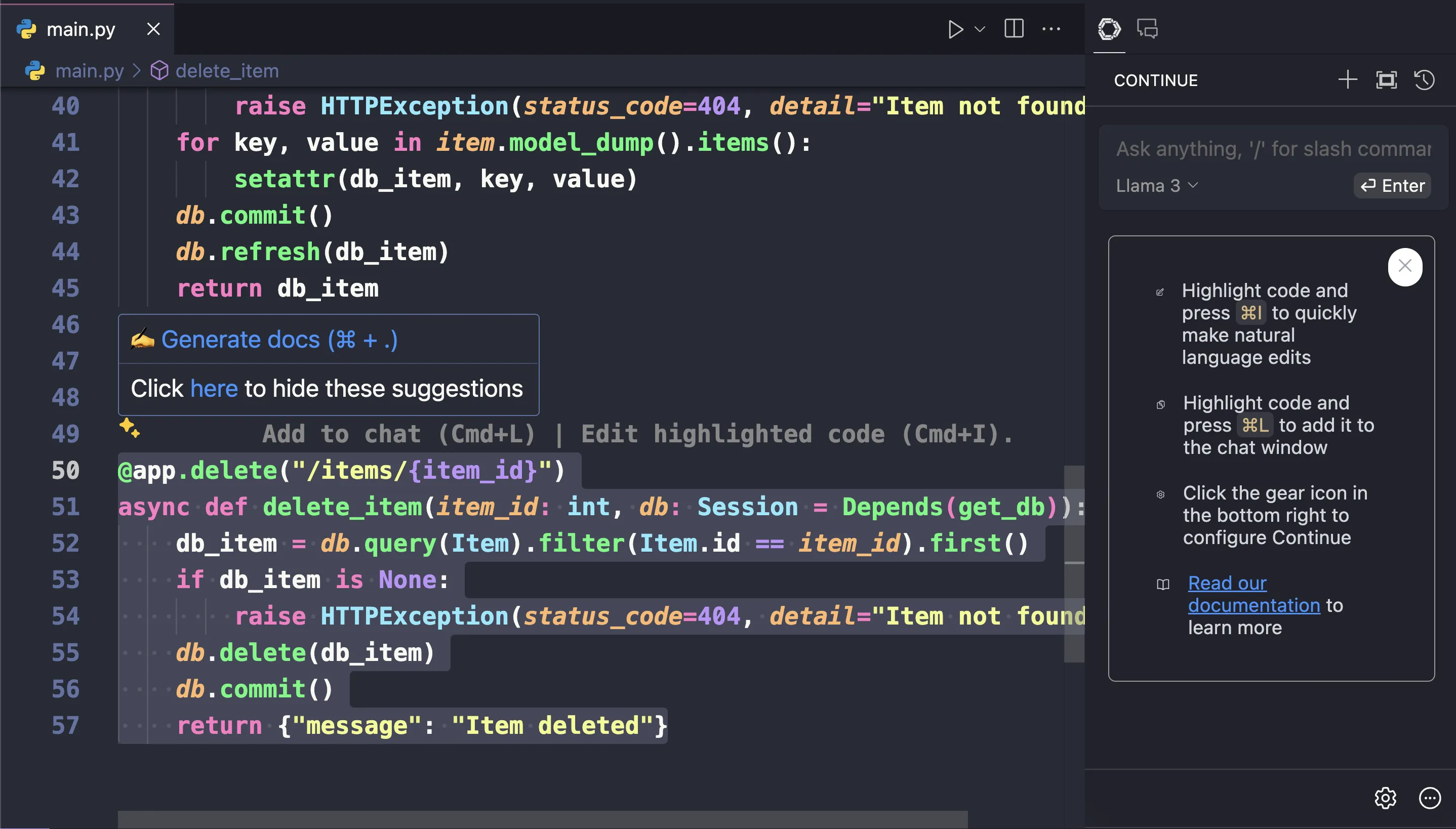
โดยเราสามารถ highlight code แล้วนำส่วนของ code มาคุยผ่าน LLM ได้ (feature ทรงๆเดียวกันกับ github copilot เลย)
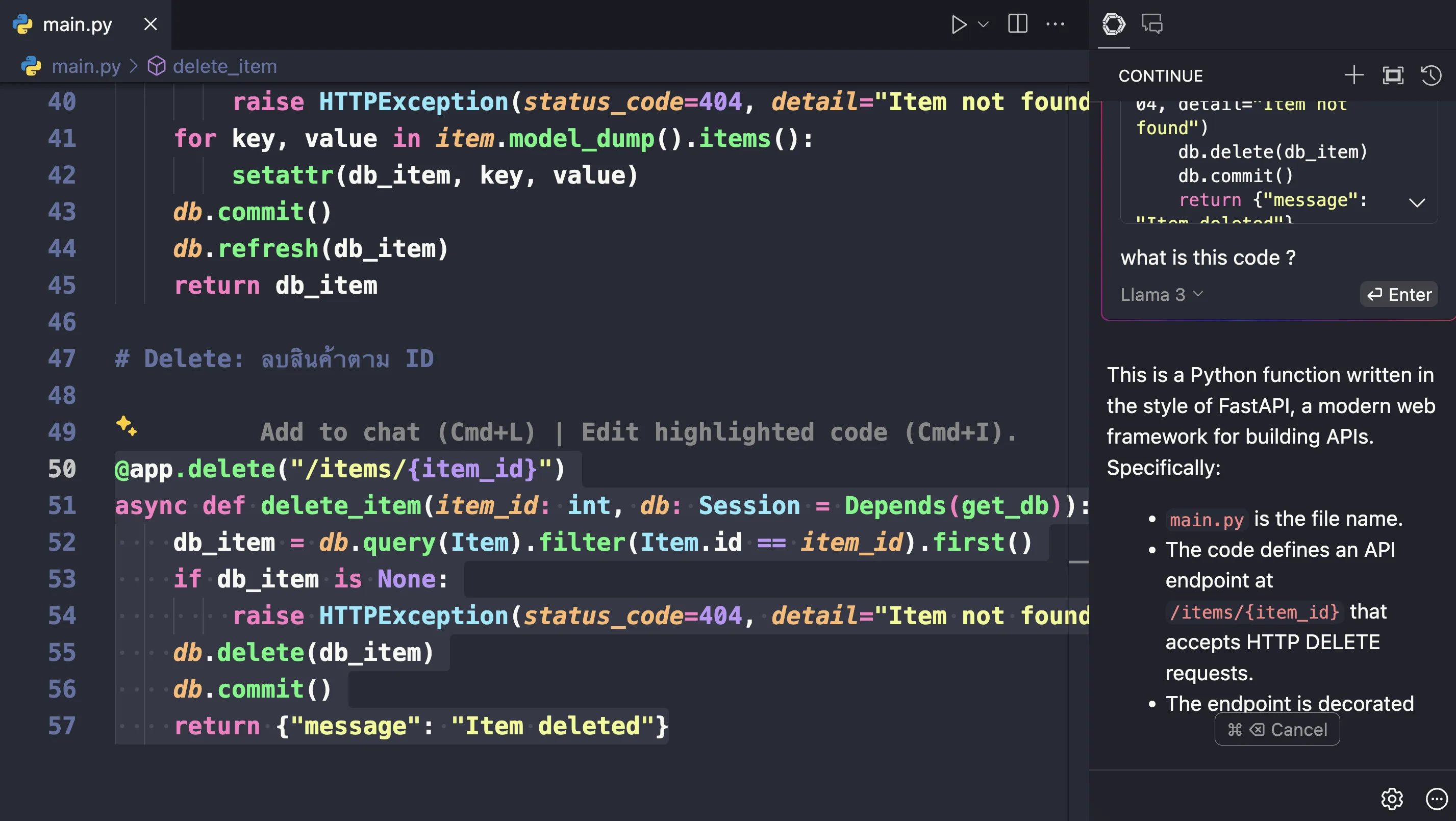
นี่ก็เป็นอีกหนึ่งตัวอย่างของ product ที่พยายามใช้ประโยชน์จาก Ollama ที่สามารถ run API เพื่อให้สามารถเชื่อมต่อคุยกับ LLM ได้
โดยปัจจุบันมี product open source หลายตัวที่พยายามทำ product คล้ายๆกัน (ไม่ว่าจะเป็น chat, image editor, agent) ที่เพื่อให้นักพัฒนาสามารถนำไปใช้และผสานเข้ากับการพัฒนางานของตัวเองได้ รวมถึง open source หลายตัวยังได้เพิ่มการรองรับการทำงานร่วมกับ Ollama อีกด้วย ทุกคนสามารถศึกษาข้อมูลเพิ่มเติมได้ตาม keyword Ollama + Opensource ได้เลยครับ
สรุป
อย่างที่ทุกคนเห็น บทความนี้ได้นำเสนอการเดินทางที่น่าตื่นเต้นในโลกของ Large Language Models (LLMs) เริ่มต้นจากการทำความเข้าใจพื้นฐานของ LLM จากนั้นได้พาเราไปสำรวจวิธีการใช้งาน LLM บนเครื่องของเราเอง (local) เพื่อความเป็นส่วนตัวและการควบคุมที่มากขึ้นกว่าการใช้ LLM API บน cloud ทั่วๆไป
รวมถึง เราได้แนะนำ Hugging Face platform ที่เป็นศูนย์กลางของชุมชน AI ที่รวบรวม model LLM รวมถึงเรียนรู้วิธีใช้งาน LM Studio ซึ่งเป็นเครื่องมือที่ช่วยให้เราทดลองและปรับแต่งโมเดล LLM บนคอมพิวเตอร์ของเราได้
ในส่วนสุดท้าย บทความได้พาเราไปสู่การนำ LLM ไปใช้งานจริงผ่าน API โดยใช้ Ollama และ FastAPI ซึ่งเป็นเครื่องมือที่ช่วยให้เราสร้าง API สำหรับ LLM ได้อย่างรวดเร็ว เราได้เห็นตัวอย่างการสร้าง API ที่รับคำถามจากผู้ใช้และส่งคำตอบกลับมาจาก LLM ได้
บทความนี้เป็นจุดเริ่มต้นที่ดีสำหรับผู้ที่สนใจในการใช้งาน LLM ไม่ว่าจะเป็นการทดลองบนเครื่องของตัวเอง หรือการนำไปสร้าง application ที่ใช้งานได้จริง ด้วยเครื่องมือและเทคนิคที่หลากหลายที่บทความได้นำเสนอ เราสามารถนำ LLM ไปประยุกต์ใช้กับงานต่างๆ ได้อย่างสร้างสรรค์และนำไปต่อยอดในอนาคตกันได้นะครับ 😁
Reference
- https://docs.llamaindex.ai/en/stable/examples/llm/huggingface/
- https://ollama.com/blog/llama3
- https://ai.google.dev/gemma
- มาลองเล่น Gemini Pro กันมี Video มี Github
มาทำความรู้จักกับ Gemini Pro และ Prompt design กันว่าเราสามารถเอา Gemini ไปทำอะไรได้บ้าง

- มาลองเล่น LIFF และ Messaging API กันมี Video มี Github
พามาทำความรู้จักกับ LIFF (LINE Frontend Framework) กันว่ามันคืออะไร เราสามารถพัฒนา Web app ลงบน LINE ได้อย่างไร

- แนะนำ Dynamic programming แบบนิ่มนวลที่สุดมี Video
บทความนี้จะแนะนำเบื้องต้นเกี่ยวกับ Dynamic programming เทคนิคหนึ่งที่ใช้สำหรับแก้ปัญหาที่ ปัญหาย่อยที่ทับซ้อนกัน (overlapping subproblem)

- NoSQL, MongoDB และ ODMมี Video
พามารู้จักกับ NoSQL พื้นฐาน database อีกตัวหนึ่ง ว่ามันคืออะไร มันเกิดขึ้นมาจากโจทย์อะไร มีลักษณะที่แตกต่างกับ SQL และมีวิธีการใช้งานที่ต่างกับ SQL ยังไงบ้าง
