

มาลองเล่น Gemini Pro กัน
/ 9 min read
 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
Genimi คืออะไร
Ref:
Google Gemini คือ project ของ Google Deepmind ที่ใช้พลังของ multimodal large language models (LLMs) มาสร้างเป็น AI ที่สามารถคิดวิเคราะห์เนื้อหาและอธิบายเนื้อหาออกมาได้ โดย Gemini นั้นพัฒนาต่อมาจาก LaMDA และ PaLM 2 (ที่เป็น model LLMs ก่อนหน้า) ออกมา
โดยตัว Gemini นั้น นอกเนื้อจากข้อมูลประเภทข้อความและ สามารถทำความเข้าใจข้อมูลได้หลากหลายประเภทมากตั้งแต่
- Text (ข้อความ) สามารถทำความเข้าใจเนื้อหา และสร้างเนื้อหาในหลากหลาย format ออกมาได้ สามารถแปลภาษาไทยรวมถึงตอบคำถามได้เช่นเดียวกัน
- Audio (เสียง) สามารถประมวลผลภาษาพูดออกมาได้ รวมถึงสามารถ generate (สร้าง) เพลงหรือ sound effect ออกมาได้
- Image / Video (ภาพ, วิดีโอ) สามารถทำความเข้าใจองค์ประกอบของ ภาพ อธิบายภาพ รวมถึงสามารถสร้างภาพใหม่ออกมาจากคำอธิบายได้
- Code ไม่เว้นแม้กระทั่งภาษาเขียนโปรแกรมเอง Gemini ก็สามารถทำความเข้าใจและอธิบายตัว code ออกมาได้

โดยใน Gemini นั้น มี 3 Model ออกมาในปัจจุบันคือ
- Gemini Ultra สำหรับ model ที่ต้องการงานที่ซับซ้อนมากๆ
- Gemini Pro เป็น model ที่สามารถใช้งานทั่วไป balance ระหว่างความสามารถและประสิทธิภาพเอาไว้อย่างลงตัว (และเป็นตัวที่เราจะมาเล่นกันวันนี้)
- Gemini Nano เป็นตัว Model ที่จะนำไปใช้งานกับพวก mobile device หรือ platform ที่มีการจำกัดเรื่องการใช้ทรัพยากรเอาไว้ (พวก embedded device) (ใครสนใจสามารถไปอ่านเพิ่มเติมได้ที่ https://ai.google.dev/tutorials/android_aicore)
ซึ่งถ้าใครอยากเห็น use case ต่างๆเพิ่มเติมสามารถเข้าไปดูได้จากเว็บไซต์ต้นฉบับได้
รู้จักกับ LLM
Ref: https://ai.google.dev/docs/concepts
ก่อนที่เราจะไปเล่น Gemini กัน เราต้องมาทำความเข้าใจกันก่อนว่า LLM คืออะไร
LLM ย่อมาจากคำว่า Large Language Model เป็น AI model ที่ถูกสร้างขึ้นมาเพื่อทำความเข้าใจและสร้างข้อมูลตอบโต้กับภาษามนุษย์ โดย model เหล่านี้จะโดน train โดยข้อมูลจำนวนเยอะมาก ไม่ว่าจะเป็นทั้ง text, image เพื่อเป็นการเพิ่มความสามารถให้ LLM สามารถทำความเข้าใจภาษามนุษย์ และตอบคำถามมนุษย์ได้ดียิ่งขึ้น โดยคำว่า “Large” นั้นนอกเหนือจากจำนวนของข้อมูลที่ใช้แล้ว ยังรวมถึง parameter ของ model ที่ใช้ train model เหล่านี้ด้วยเช่นกัน (ซึ่งมีตั้งแต่จำนวนเป็นล้านถึงพันล้านเลย แล้วแต่ AI model แต่ละตัว) จึงส่งผลทำให้ LLM พวกนี้มีความสามารถในการเข้าใจข้อมูลของมนุษย์ที่ซับซ้อนมากๆจากหลายๆส่วนได้
จริงๆแล้วถ้าว่าตามความเป็นจริง LLM เป็นไอเดียที่ต่อยอดมาจาก Transformer (Encoder - Decoder) ที่ทำการแปลงของจากสิ่งหนึ่งและไปสร้างอีกสิ่งหนึ่งได้ (เป็นไอเดียที่ใช้ในพวก RNN, CNN) แต่ความแตกต่างของ LLM ที่ทำให้แตกต่างกับ Transformer ก่อนหน้านี้คือ “วิธีการเรียนรู้ของ LLM” พวกนี้ (โมเดล Transformer ยังคงใช้การสร้างความสัมพันธ์ระหว่างคำศัพท์ในประโยคที่ให้ความสำคัญกับคำที่อยู่ใกล้เคียงกัน โดยใช้ Self-Attention mechanism โดยเป็นการเรียนรู้จากความสัมพันธ์ภายใน model เอง)
จะขอยกตัวอย่างกับ GPT (ChatGPT) ที่ใช้หลักการของ Reinforcement Learning from Human Feedback (RLHF) คือ เทคนิค machine learning ที่ใช้สิ่งที่เรียกว่า “Human (คน)” ในการเสริม feedback ของตัวข้อมูลเพื่อเป็นการ optimize ML model เข้าไปเพื่อให้ตัว model นั้นเกิดการเรียนรู้ตัวเองได้มีประสิทธิภาพยิ่งขึ้น คือตัว model มันมีความสามารถในการ fine-tuned parameter อยู่และ แต่ข้อมูลนี้จะส่งผลทำให้ตัว model สามารถมั่นใจได้มากขึ้นว่าข้อมูลที่มีอยู่นั้นถูกต้องตามหลักการจริงๆหรือไม่ (เป็นการ maximize rewards ให้กับ Reinforcement learning เพื่อให้การเรียนรู้มีประสิทธิภาพยิ่งขึ้น)

แน่นอน เมื่อใช้สิ่งที่เรียกว่าคน มาตอบรับ Feedback นั้น
ซึ่งในปัจจุบันไม่ว่าจะเป็น LLM ตัวไหนที่ใช้อยู่ในอุตสาหกรรมก็ตาม (ตัวที่เราคุ้นชินอยู่ตอนนี้อย่าง ChatGPT, Bard - Gemini) ต่างก็ใช้หลักการนี้อยู่บนพื้นฐานทั้งหมด เพียงแต่ แต่ละ model ก็อาจจะมีการใช้ parameter ของ Human แตกต่างกันไป บาง model ก็อาจจะให้ความสำคัญกับ parameter บางอย่างเป็นพิเศษ ทำให้ หลายๆ model แม้ว่าจะมีหลักการเบื้องหลังเป็น RLHF เหมือนกันก็ตาม
โดย task ส่วนใหญ่ที่ LLM ทำได้ก็จะมีตั้งแต่
- การแปลภาษา
- ตอบคำถามชีวิตประจำวัน
- สรุปข้อมูล
- ทำการสร้างสรรค์ข้อความ (จากข้อมูลที่มี) ออกมาใหม่
- generate code ตามโจทย์
เลยทำให้ LLM เริ่มกลายเป็นส่วนหนึ่งของ AI ที่เกี่ยวข้องกับเรื่องของการ “สร้างสิ่งที่จำเป็น” ในยุคสมัยนี้ออกมาได้เช่นกัน โดยไม่จำเป็นต้องมีความรู้เรื่อง machine learning เราก็สามารถใช้พลังของ AI ในการสร้าง product AI ออกมาได้
มารู้จักเพิ่มเติมกับ Gemini Pro กันบ้าง
เนื่องจากบทความนี้ เราจะขยี้ไปที่ Gemini Pro เป็นหลัก ดังนั้นเราจะขอกลับมาพูดถึง Gemini Pro กัน
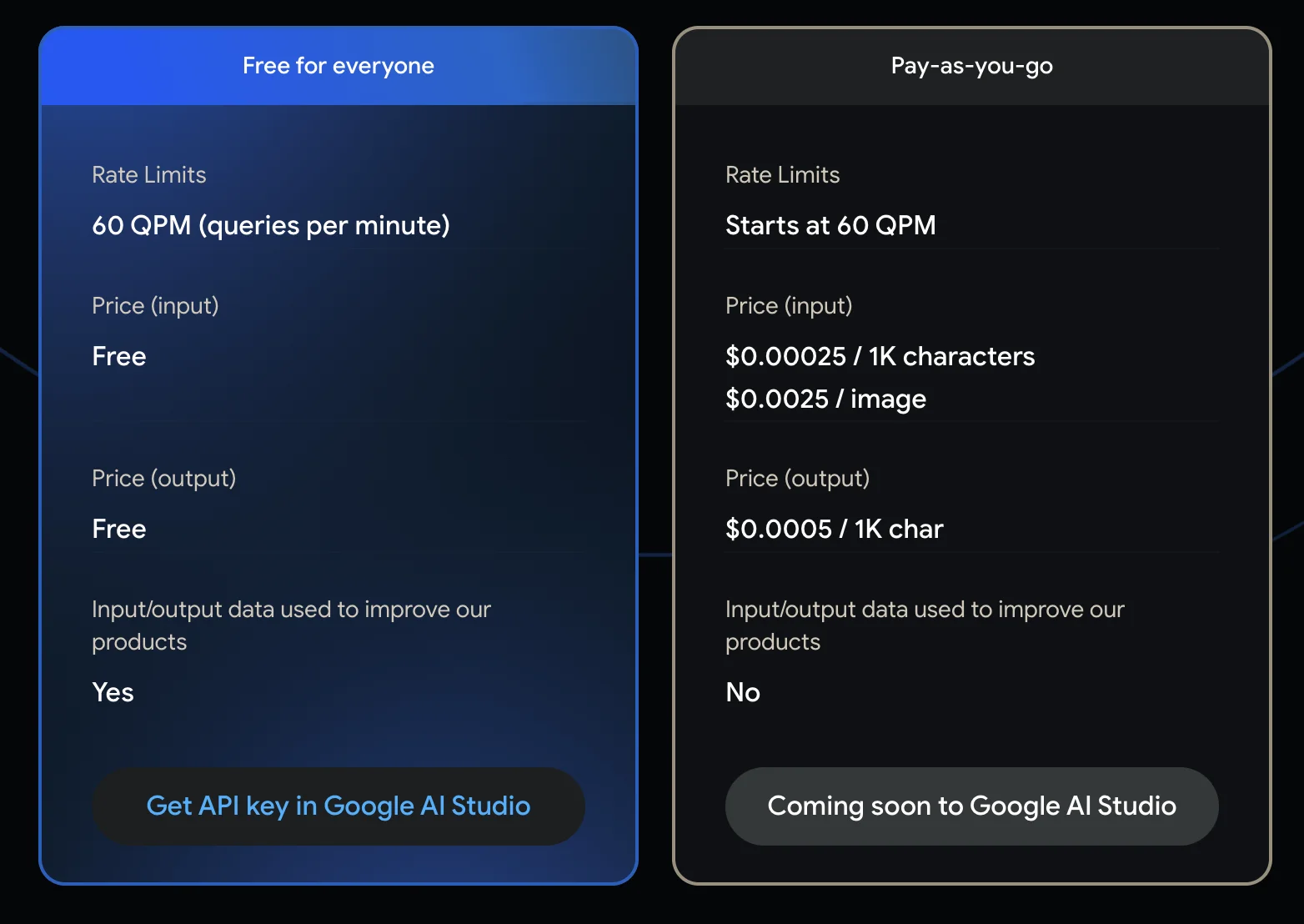
จริงๆแล้ว ไม่ว่าจะเป็น LLM เจ้าไหนก็ตาม (ไม่ว่าจะเป็นทั้ง GPT และ Gemini) ต่างเปิด “API” ให้้ใช้เป็นเบื้องหลังทั้งคู่ แต่สิ่งที่ทำให้ผมมาสนใจตัว Gemini Pro คือ ณ ตอนที่ผมกำลังเขียนอยู่นั้น Gemini Pro ยังคงมี “Free Tier” ที่ให้ใช้งานได้สำหรับทุกคนอยู่
ดังนั้นเพื่อให้ทุกคนได้มาเห็นพลังของ LLM เราจะมาลองเล่น Gemini Pro ไปพร้อมๆกัน (เพื่อให้ทุกคนเห็นภาพด้วยว่า หากนำไปประยุกต์ใช้แบบ API สามารถนำไปใช้ยังไงได้บ้าง)
มาลองเล่น Genimi ผ่าน Google AI Studio
เราจะมาลองเชื่อมต่อผ่าน Gemini sdk ด้วย nodejs กันโดยตัวที่เราจะมาลองกันในบทความนี้ เราจะทำการลง library โดยทำตามเอกสารของ Gemini Pro ตามเอกสารนี้กัน https://ai.google.dev/tutorials/node_quickstart
โดยในตัวของ Gemini Pro นั้น จะสามารถรับข้อมูลเข้ามาได้ 2 อย่างคือ
- text prompt สำหรับคำสั่งที่ต้องการให้ gemini pro ทำงาน
- file สำหรับการแนบข้อมูลเพิ่มเติมที่ใช้งานคู่กับ text prompt ซึ่งจากข้อมูลในเอกสารของ Gemini Pro นั้นได้ระบุว่าไฟล์ที่ส่งเข้ามายังคงสามารถส่งได้แค่ภาพเข้ามา (เราจะเรียกเคสนี้ว่า multimodel หรือการสื่อสารระหว่างข้อมูลอีกประเภทสู่ข้อมูลอีกประเภท)
เพื่อให้ทุกคนเห็นภาพ เราจะลองมาทำ 3 case ง่ายๆกันก่อน (ตาม document) คือ
- ส่ง text ตอบไปมาทั่วไป (ส่ง prompt ปกติ)
- ส่ง file ภาพเข้าไปและส่ง prompt เพิ่มเติม
- ส่ง text พร้อม history (สำหรับให้ข้อมูลพื้นฐานก่อนส่ง prompt ไป)
โดยในหัวข้อนี้เราจะจำลองการทำ API เพื่อใช้สำหรับการส่งข้อมูล prompt ไปใน Gemini โดย setup เริ่มต้นเราจะ setup จาก express กันก่อน (เพื่อทำเป็น Rest API) โดยโครงสร้าง project จะมีตามนี้
├── gemini.js --> สำหรับใช้งาน Gemini├── index.js --> สำหรับ run express ตัวหลัก├── .env --> สำหรับเก็บ Environment variable เข้าไป└── package.jsonโดย package.json ที่เราจะลงไว้นั้นจะมีดังนี้
{ "name": "gemini-pro-example", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "start": "nodemon index.js", "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "dependencies": { "@google/generative-ai": "^0.1.3", "dotenv": "^16.3.2", "express": "^4.18.2", "multer": "^1.4.5-lts.1", "nodemon": "^3.0.3" }}library แต่ละตัวที่ใช้
@google/generative-aiสำหรับการใช้งาน service Gemini ของ Googleexpressสำหรับการทำ Rest APIdotenvสำหรับการอ่านค่า.envเข้ามา (ใช้สำหรับการอ่าน API key ของ Gemini และกำหนด config อื่นๆ)multerตัวช่วยสำหรับการทำ upload file เข้ามา
ทีนี้อันดับแรก เราต้องไปหา API Key ของตัว Gemini Pro ออกมาก่อนเพื่อเริ่มต้นใช้งาน API โดยทุกคนสามารถเข้าไปหยิบมาได้จาก https://makersuite.google.com/app/apikey ให้ทำการกดสร้าง API Key จากหน้านี้
หลังจากนั้นเราจะได้ key ที่มีหน้าตาประมาณนี้ออกมา นี่คือ API Key ที่จะเป็นตัวอนุญาตให้เราเข้าใช้ service ของ Gemini ออกมาได้
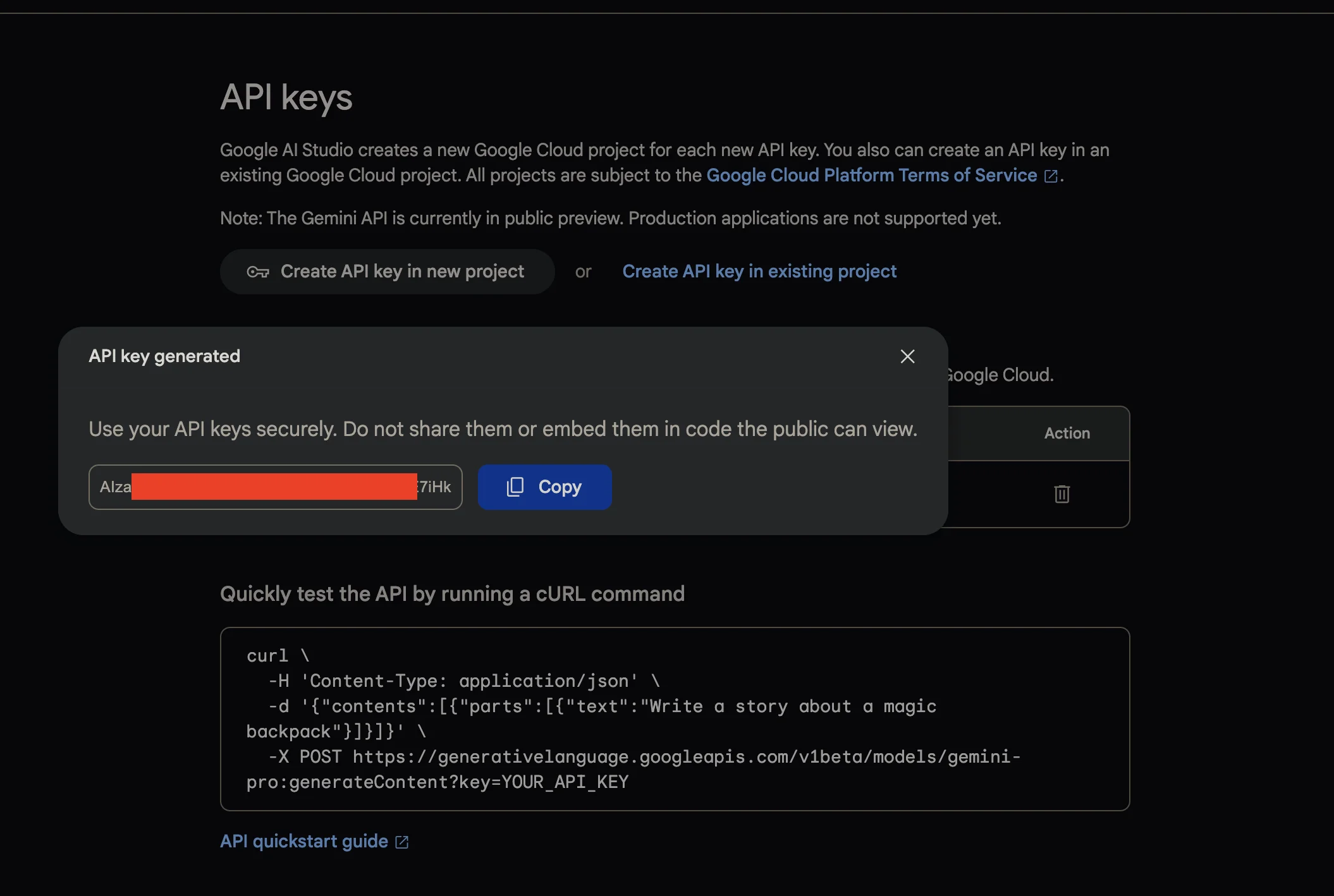
ให้นำ key นั้นมาทำการใส่ผ่าน .env เข้าไป ซึ่ง .env ก็จะมีหน้าตาประมาณนี้ออกมาได้
GEMINI_APIKEY=<GEMINI KEY ตามที่สร้างมา>หลังจากนั้นที่ gemini.js (ไฟล์สำหรับการเรียกใช้งาน service Gemini) เราจะทำการเรียกใช้ service ของ Gemini โดยอ่านค่า key ผ่าน .env ออกมาแทน โดยเรียกใช้คำสั่ง model.generateContent(prompt) โดยทำการส่ง prompt text เข้าไป
require("dotenv").config()
const { GoogleGenerativeAI } = require("@google/generative-ai")
const genAI = new GoogleGenerativeAI(process.env.API_KEY)
async function run() { // For text-only input, use the gemini-pro model const model = genAI.getGenerativeModel({ model: "gemini-pro" })
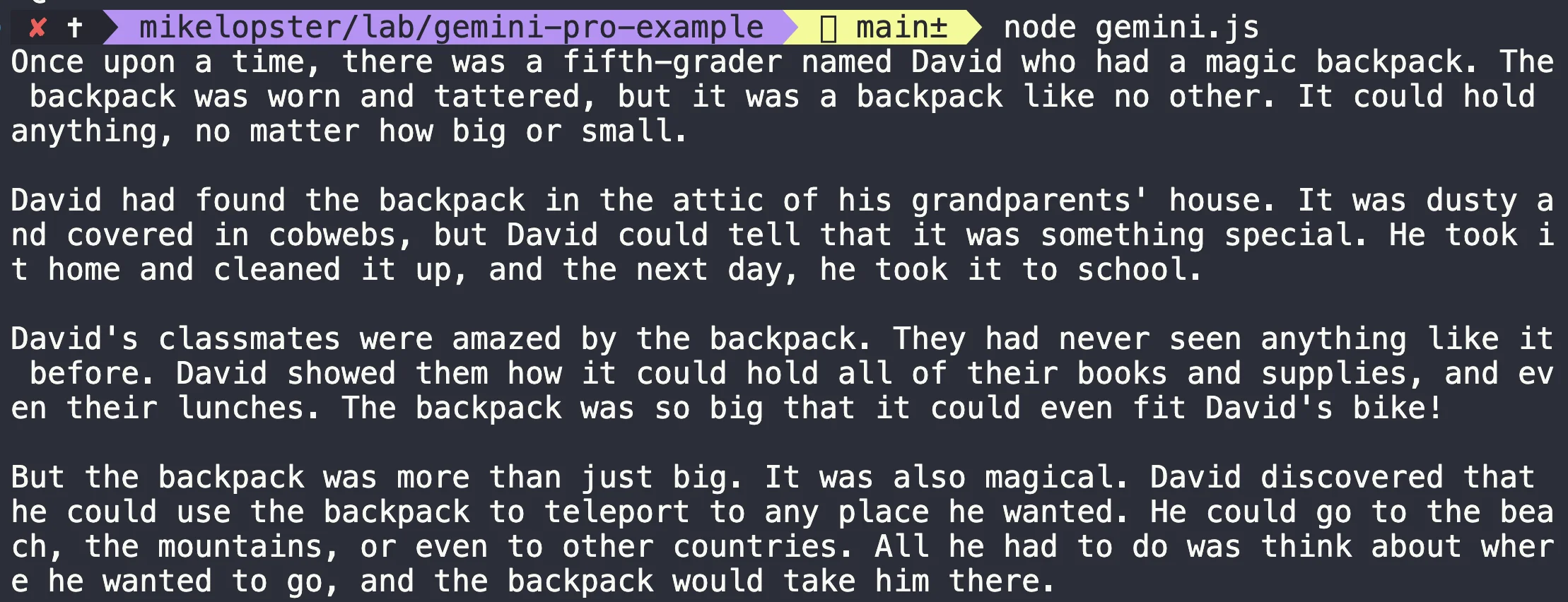
const prompt = "Write a story about a magic backpack."
const result = await model.generateContent(prompt) const response = await result.response const text = response.text() console.log(text)}
run()ถ้าได้ผลลัพธ์แบบนี้ออกมาได้ = สามารถต่อ Gemini ออกมาได้ (เรียกใช้ key ได้อย่างถูกต้อง และ key setup ไว้อย่างถูกต้อง) สามารถไปต่อได้
หลังจากนั้น เราจะปรับทุกอย่างให้เป็น API ออกมา โดยเราจะทำการสร้าง API จาก express ออกมา และเรียกใช้งาน library gemini ออกมาแทน
ที่ไฟล์ gemini.js สร้างเป็น function สำหรับการเรียกใช้แทนโดย
chatPrompt()= เป็นคำสั่งสำหรับรับ text prompt เข้ามาimageChat()= เป็นคำสั่งสำหรับการรับภาพเข้ามาร่วมกับ promptchatHistoryPrompt()= เป็นคำสั่งสำหรับการนำ history มาประกอบกับ prompt ออกมา
** history prompt เป็นการจำลองการสนทนาก่อนหน้า เพื่อให้การส่งข้อความไปนั้นสามารถกรอบข้อมูลมาได้ตรงประเด็นมากขึ้น เช่น อาจจะจำลองบทสนทนาที่เกี่ยวข้องกับสถานการณ์ออกมาก่อน ก่อนที่จะระบุเป็นคำถามออกมา
ตัว code ก็จะมีหน้าตาประมาณนี้ออกมา
require("dotenv").config()
const { GoogleGenerativeAI } = require("@google/generative-ai")
const genAI = new GoogleGenerativeAI(process.env.GEMINI_APIKEY)
const fileToGenerativePart = (imageData, mimeType) => { return { inlineData: { data: imageData, mimeType, }, }}
const imageChat = async (prompt, imageData, mimeType) => { // For text-and-image input (multimodal), use the gemini-pro-vision model const model = genAI.getGenerativeModel({ model: "gemini-pro-vision" }) const imageParts = [fileToGenerativePart(imageData, mimeType)] const result = await model.generateContent([prompt, ...imageParts]) const response = await result.response const text = response.text() return text}
const chatPrompt = async (prompt) => { // For text-only input, use the gemini-pro model const model = genAI.getGenerativeModel({ model: "gemini-pro" }) const result = await model.generateContent(prompt) const response = await result.response const text = response.text() return text}
const chatHistoryPrompt = async (prompt, history) => { // For text-only input, use the gemini-pro model const model = genAI.getGenerativeModel({ model: "gemini-pro" })
const chat = model.startChat({ history })
const result = await chat.sendMessage(prompt) const response = await result.response const text = response.text() return text}
module.exports = { imageChat, chatPrompt, chatHistoryPrompt,}ที่ index.js สำหรับการใช้งานผ่าน API เราจะลองทดสอบโดยการ
- POST
/api/chat= สำหรับ API เพื่อรับ prompt ผ่าน chat - POST
/api/upload= สำหรับ API เพื่อรับ prompt และภาพ - POST
/api/history= สำหรับ API เพื่อรับ prompt แบบมี history เข้ามา
const express = require("express")const multer = require("multer")const { imageChat, chatPrompt, chatHistoryPrompt } = require("./gemini")const app = express()
require("dotenv").config()
app.use(express.json())
const upload = multer({ storage: multer.memoryStorage() })
// Normal Promptapp.post("/api/chat", async (req, res) => { const { chat } = req.body const result = await chatPrompt(chat) res.json({ message: result })})
// Case upload file and promptapp.post("/api/upload", upload.single("myfile"), async (req, res) => { const file = req.file const { chat } = req.body if (!file) { return res.status(400).send("No file uploaded.") }
if (!chat) { return res.status(400).send("No chat.") }
const fileData = file.buffer.toString("base64") const fileMimetype = file.mimetype
const result = await imageChat(chat, fileData, fileMimetype)
res.json({ message: "File uploaded successfully", result, })})
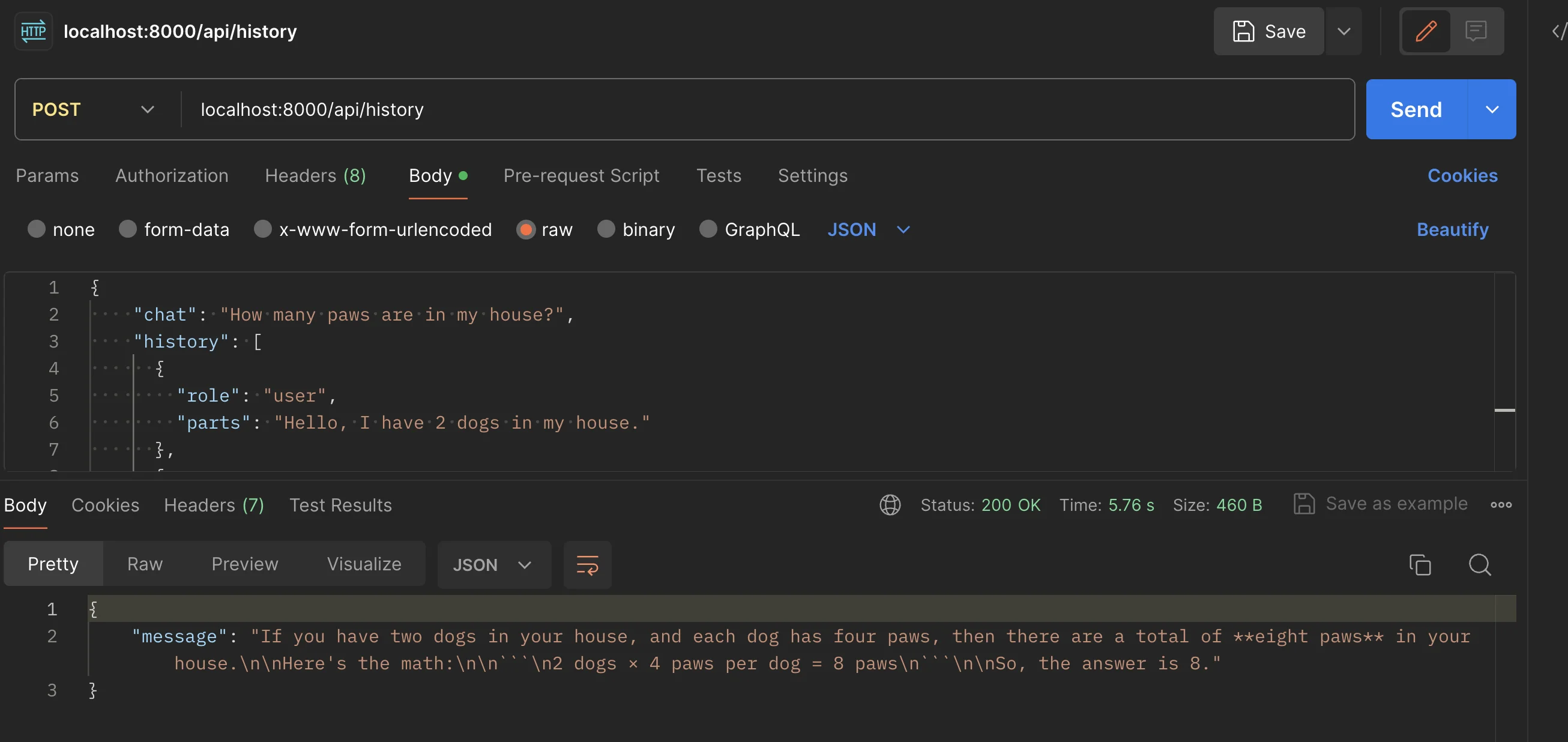
// History Promptapp.post("/api/history", async (req, res) => { const { chat, history } = req.body const result = await chatHistoryPrompt(chat, history) res.json({ message: result })})
const PORT = process.env.PORT || 8000app.listen(PORT, () => { console.log(`Server running on port ${PORT}`)})เมื่อทดสอบยิงผ่าน API และได้ผลลัพธ์ของ Gemini ออกมาได้ = แปลว่า API เราทำงานได้อย่างถูกต้องแล้ว (อันนี้เป็นตัวอย่างทดสอบจากการยิง prompt history เข้าไป)
Practice การใช้งาน Gemini
เพื่อให้สามารถใช้ Gemini ได้ทรงพลังยิ่งขึ้น สิ่งที่สำคัญของการทำ AI chatbot พวก LLM อย่าง Gemini นั้น จำเป็นจะต้องใส่คำสั่งเพื่อกำหนดสิ่งที่เรียกว่า “เป้าหมายที่อยากได้” ออกมา ซึ่งสิ่งเหล่านี้คือสิ่งที่เรียกว่า “Prompt”
โดยใน Google นั้นก็ได้มีบทความเรื่อง Prompt design ที่สามารถ design prompt ให้ตอบโจทย์เพิ่มเติมได้ที่นี่ https://ai.google.dev/docs/prompt_best_practices
โดยไอเดียส่วนใหญ่ของการทำ Prompt กับพวก LLM นั้น เราจะต้องสร้างสิ่งที่เรียกว่า “Prompt Example Pattern” ออกมาให้ถูกต้อง โดยไอเดียใหญ่ๆคือ เราจะต้องกำหนดสิ่งที่เป็น “ตัวอย่างของเป้าหมาย” ออกมาว่า เราอยากได้คำตอบหน้าตาประมาณไหนออกมา ซึ่งสิ่งนี้จะส่งผลทำให้เราสามารถได้คำตอบที่ตรงโจทย์มากขึ้น รวมถึงสามารถนำมาประยุกต์ใช้กับ Application ของเราได้หลากหลายมากขึ้นเช่นเดียวกัน (นอกเหนือจากการส่ง chat text เข้าไปเหมือน ChatGPT หรือ Bard)
เราจะมาลองเล่น 4 use case กัน ที่แต่เดิมเราอาจจะต้องใช้ library ช่วย แต่เราสามารถเปลี่ยนมาใช้พลังของ Prompt ใน Gemini ในการทำแทนออกมาได้
1. สรุปข้อความสู่ bullet
มาถึง prompt แรก เราจะทำการกำหนดโจทย์ที่เราอยากได้ พร้อมกับ pattern ตัวอย่าง โดยในเคสนี้เราจะทำการสร้าง prompt สำหรับการสรุปความออกมา โดย
- เราทำการระบุโจทย์ว่า เราอยากสรุปบทความที่ส่งเข้ามา
- เราเขียน pattern ตัวอย่างที่เราอยากได้เป็น bullet ออกมา
- ทั้งหมดกำหนดไว้ภายใน prompt ใส่ไว้เป็น history prompt เข้ามา เพื่อเป็นการระบุเป้าหมายก่อนรับโจทย์เข้ามา ทำให้ตัว Gemini นั้นสามารถรู้ได้ว่า สิ่งที่จะรับต่อไปนี้คือบทความที่จะต้องทำตามโจทย์ออกมาได้
- เมื่อได้คำตอบออกมา เราก็จะได้คำตอบตาม pattern ตัวอย่างที่ระบุไว้ใน prompt ออกมาได้ (ใช้การ split เพื่อให้ได้คำตอบเป็น array ที่ต้องการออกมา)
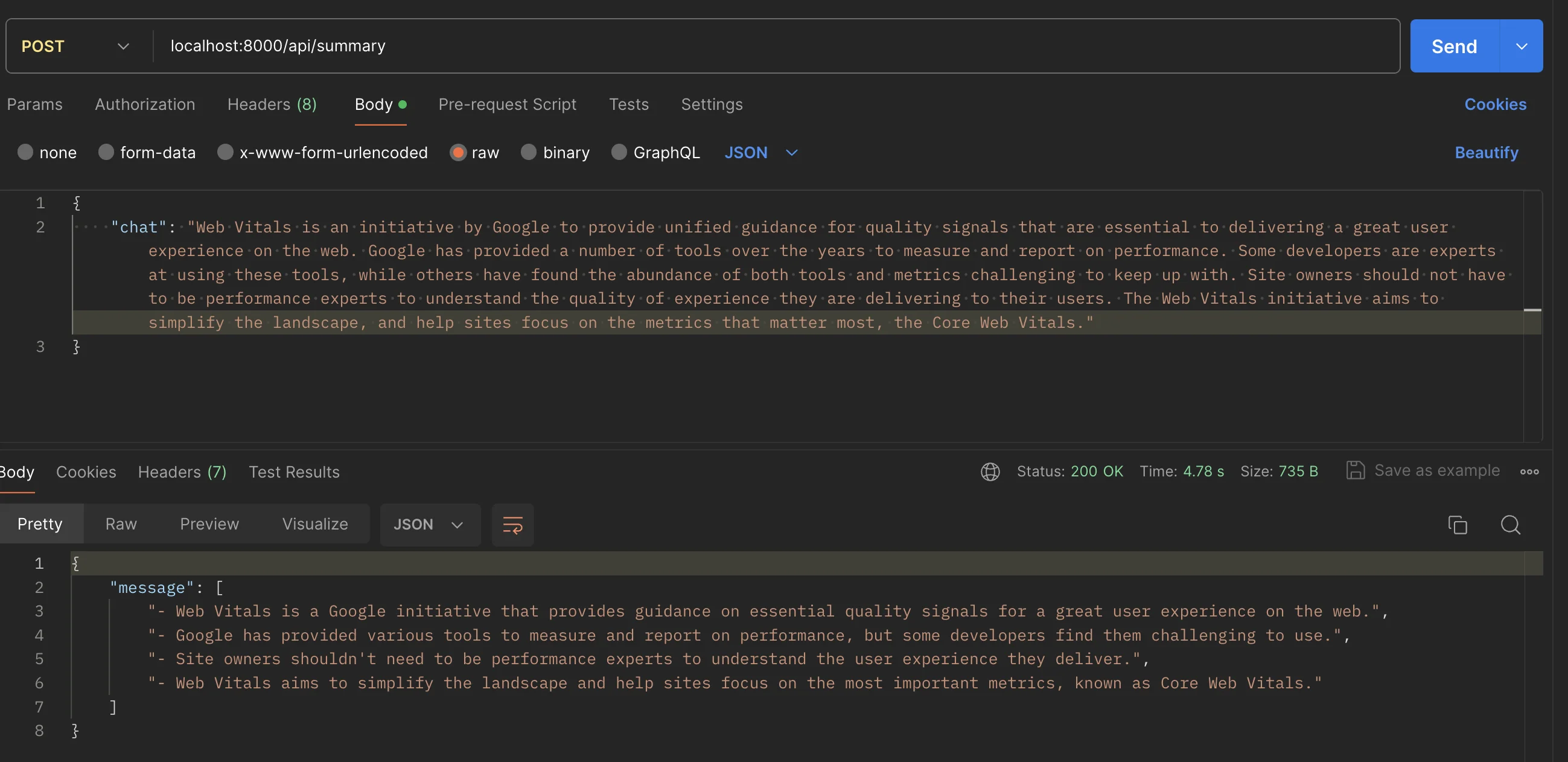
// Case 1: summary to bulletapp.post("/api/summary", async (req, res) => { try { const { chat } = req.body const result = await chatHistoryPrompt(chat, [ { role: "user", parts: ` Summary this text that write in format of bullet points Example: - summary point 1 - summary point 2 `, }, { role: "model", parts: "Please provide information", }, ])
const summaryBulletList = result.split("\n")
res.json({ message: summaryBulletList }) } catch (error) { console.log("error", error) res.status(400).json({ message: "sorry, cannot extract data." }) }})ผลลัพธ์
2. สร้าง choice จากคำถามและคำตอบ
Prompt นี้มาสู่ไอเดียของการช่วยคิดกันบ้าง เราจะทำการสร้าง prompt สำหรับการคิด choice ออกมา โดยใช้ไอเดียคล้ายๆกันคือ
- กำหนด pattern ว่า เราจะตั้งคำถามแบบนี้ และคำตอบจะเป็นแบบนี้
- ให้ Gemini ช่วยคิดคำตอบ choice ของ 3 ข้อที่เหลือ (ที่จะไม่เป็นคำตอบที่ถูกของสิ่งนี้) เพื่อให้ได้ choice เป็น 4 choice สำหรับการทำโจทย์แบบตัวเลือกออกมา
- หลังจากนั้น กำหนด pattern ตัวอย่างตามเดิม โดยกำหนดเป็น Example ที่เราอยากได้
- และหลังจากนั้น นำคำตอบที่ได้มาใช้ Regular Expression เพื่อแกะ choice และส่งเป็น Array ออกมา
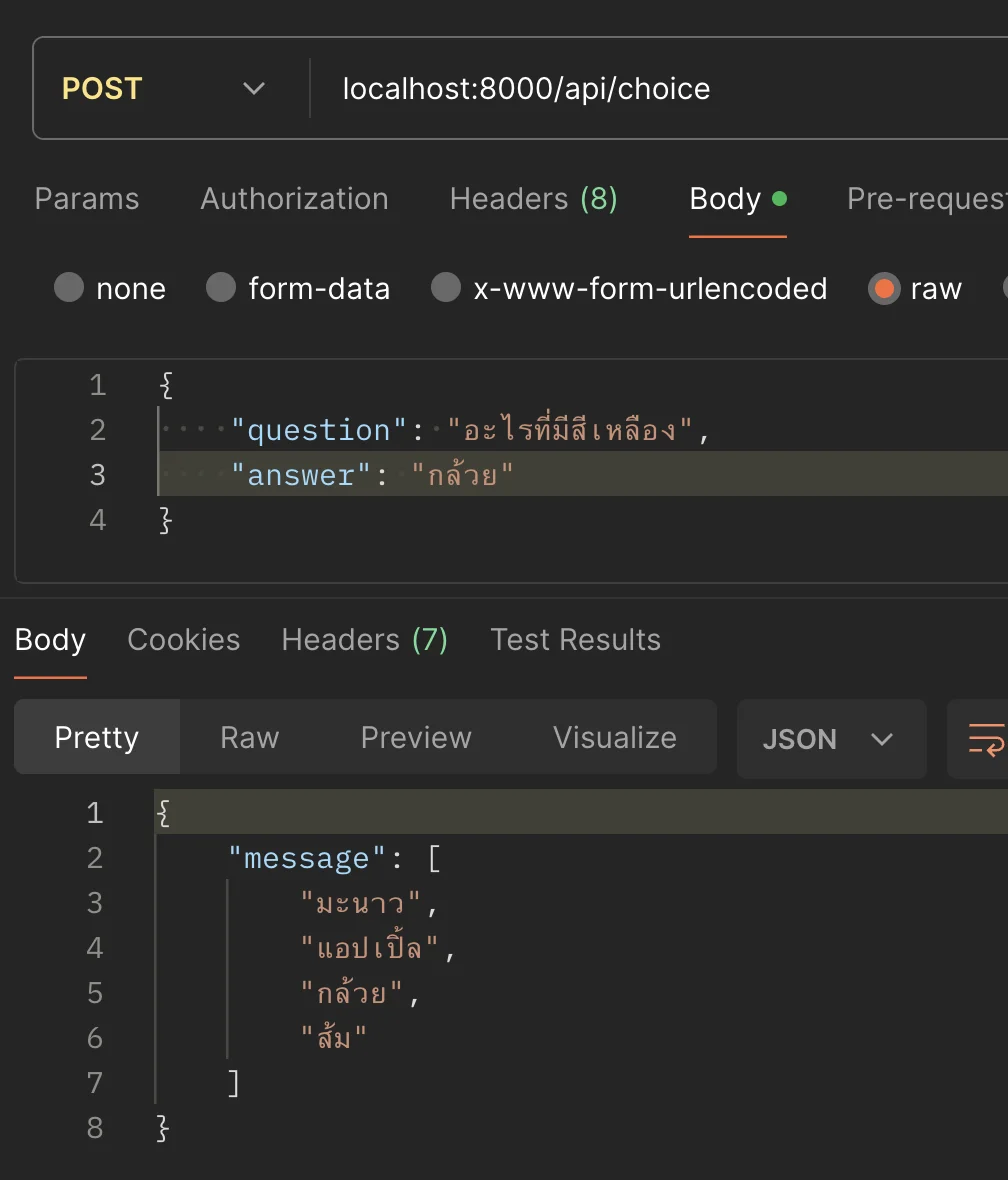
// Case 2: generate choice from answerapp.post("/api/choice", async (req, res) => { try { const { question, answer } = req.body const chat = `Question: ${question}. Answer: ${answer}. Generate 3 Choices` const result = await chatHistoryPrompt(chat, [ { role: "user", parts: ` I have question and answer. Please generate 3 choices that related with answer (but it is incorrect answer).
Example like this (follow this pattern for generate choices) Question : What is the red color? Answer: Apple
AI should result like this (no more description like this) Generate 3 Choices: 1. Banana 2. Orange 3. Grape `, }, { role: "model", parts: "Please provide Question and Answer. I will give Generate 3 Choices for you.", }, ])
const pattern = /\d\.\s(.+?)(?=\n|$)/g
// Extract matches let choices = [answer] let match while ((match = pattern.exec(result)) !== null) { choices.push(match[1].replace("*", "")) }
choices = shuffleArray([...choices])
res.json({ message: choices }) } catch (error) { console.log("error", error) res.status(400).json({ message: "sorry, cannot extract data." }) }})ผลลัพธ์
3. หาสถานที่ภายในภาพ
เราจะมาลองทำกับ multimodel บ้าง โดยเราจะเปลี่ยน input จาก text เป็นภาพบ้าง ซึ่งจากหัวข้อก่อนหน้านี้เราได้ลองรับภาพมาพร้อมกับ prompt แล้ว
เราจะมาลองไอเดียคล้ายๆกันโดยสร้างสิ่งที่เราอยากได้ และ กำหนด pattern ตัวอย่างที่เราอยากได้เช่นกัน
ในเคสแรกนี้ เราจะทำการสร้าง API ออกมา โดยให้ AI ลองทายสถานที่ในภาพว่า มันคือที่ไหนและอยู่ประเทศอะไร โดย
- ทำการกำหนดคำถามว่า สถานที่ในภาพคือสถานที่อะไร
- ระบุว่า คำตอบที่เราอยากได้นั้นมีหน้าตาเป็นแบบไหน และขอให้ส่งแค่คำตอบออกมาเท่านั้น (กันว่า Gemini จะมีการอธิบายเพิ่ม)
- หลังจากนั้นก็ทำการส่ง prompt พร้อมภาพไป = เราก็จะได้ API สำหรับการคาดเดาสถานที่ในภาพออกมาได้
// Case 3: find location in imageapp.post("/api/location", upload.single("myfile"), async (req, res) => { try { const file = req.file if (!file) { return res.status(400).send("No file uploaded.") }
const fileData = file.buffer.toString("base64") const fileMimetype = file.mimetype
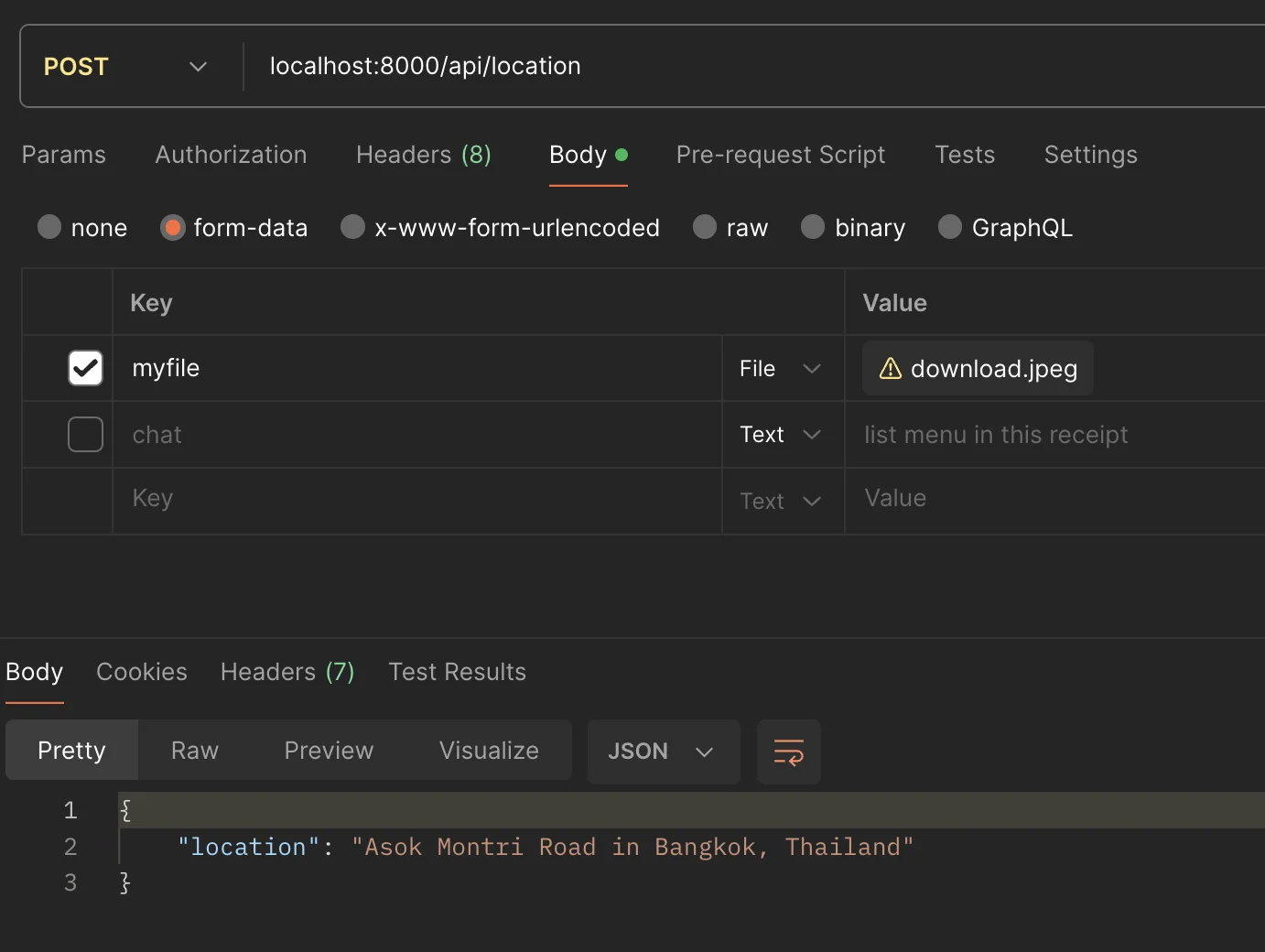
const location = ( await imageChat( ` what is the location in this image ? just answer location. Example answer: Asok Montri Road in Bangkok, Thailand `, fileData, fileMimetype ) ).trim()
res.json({ location, }) } catch (error) { console.log("error", error) res.status(400).json({ message: "sorry, cannot extract data." }) }})นี่คือภาพตัวอย่างที่เรานำมาใช้
และนี่คือผลลัพธ์ที่ได้ออกมา
4. ทำ OCR กับภาพ
นอกเหนือจากเคสการทำความเข้าใจภาพแล้ว อีกหนึ่งความสามารถของ Gemini คือความสามารถในการ “อ่านภาพ” ด้วยเช่นเดียวกัน ซึ่งนั่นก็คือการทำ OCR ออกมานั่นเอง แน่นอน จริงๆในโลกของเรามี API ทำ OCR อยู่แล้ว เพียงแต่ด้วยความสามารถ Prompt ของ Gemini เองทำให้เราสามารถทำสิ่งนี้ออกมา โดยใช้ Service Gemini ตัวเดียวกันออกมาได้เช่นกัน
สิ่งที่เราทำคือ
- ทำการรับภาพมาเช่นเดิม
- เพิ่มเติม prompt ไปว่า ให้ดึงข้อมูล menu ออกมาจากใบเสร็จ โดยระบุ format ที่อยากได้ออกมา
- หลังจากนั้นนำ Regular Expression มาแกะข้อมูล menu ออกมา
- ก็จะสามารถได้ list ของเมนูออกมาได้แล้ว
// Case 4: OCRapp.post("/api/menu-extract", upload.single("myfile"), async (req, res) => { try { const file = req.file if (!file) { return res.status(400).send("No file uploaded.") }
const fileData = file.buffer.toString("base64") const fileMimetype = file.mimetype
const result = await imageChat( ` list menu in this receipt in this format - menu 1 - menu 2 `, fileData, fileMimetype )
// Regex pattern to match the items const pattern = /-\s(.+?)(?=\n|$)/g
// Extract matches const menus = [] let match while ((match = pattern.exec(result)) !== null) { menus.push(match[1]) }
res.json({ menus, }) } catch (error) { console.log("error", error) res.status(400).json({ message: "sorry, cannot extract data." }) }})นี่คือภาพใบเสร็จตัวอย่าง

และนี่คือผลลัพธ์ของ API
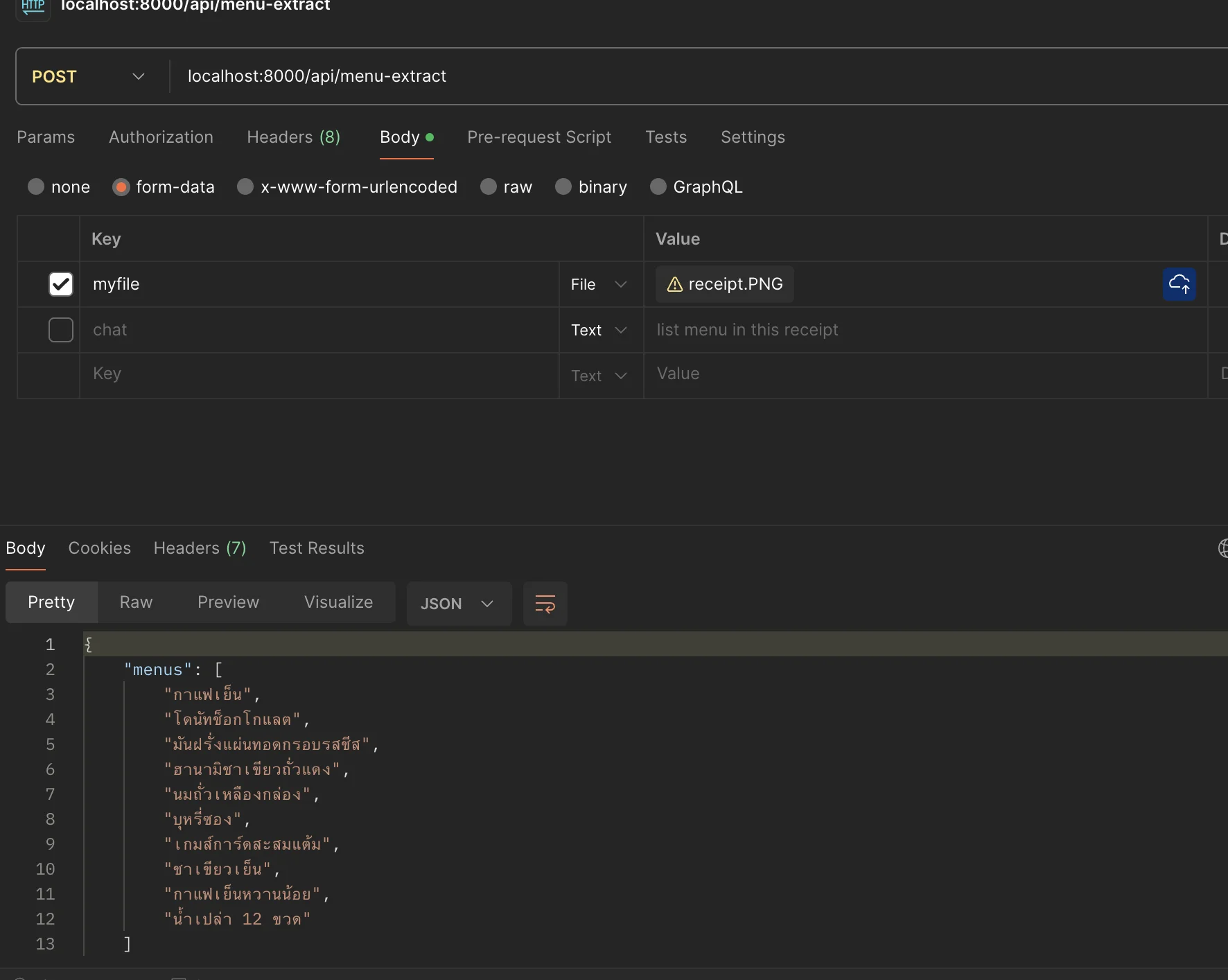
และใช่ครับ มันตอบไม่ถูกเลยครับ 😂 (คือมันสามารถทำตามคำสั่งเราได้เป๊ะก็จริง แต่ใช่ว่าคำตอบจะถูกนะครับ) แต่ถ้าเราลองกับใบเสร็จภาษาอังกฤษบ้างละ
ผลลัพธ์ก็จะได้ทรงๆนี้ออกมา
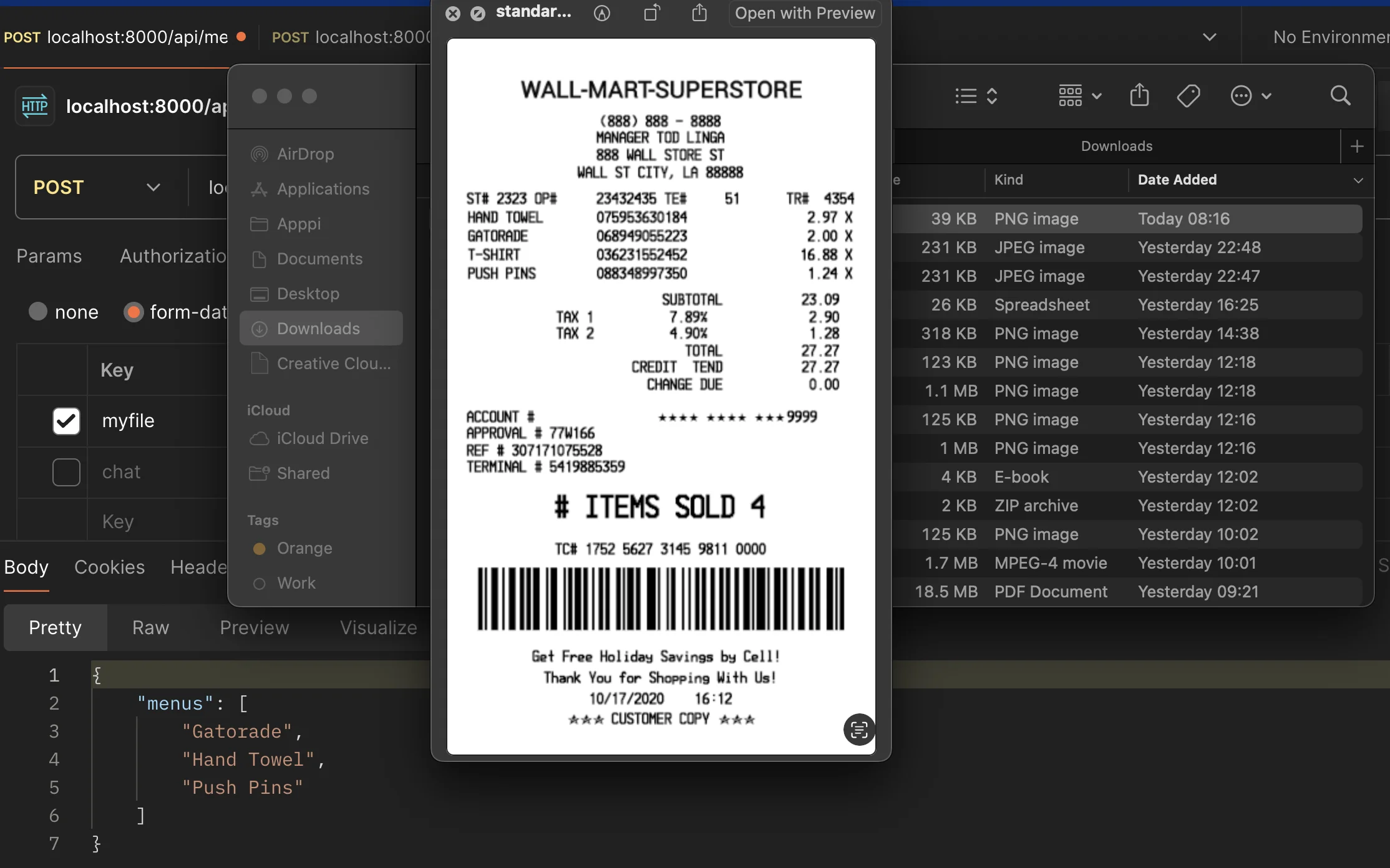
ซึ่งจะเห็นว่า พอเป็นภาษาอังกฤษนั้นตัว Gemini พอที่จะอ่าน OCR ออกมาได้ (อย่างน้อยก็ดีกว่าภาษาไทย) เพราะฉะนั้นหากจะประยุกต์ใช้เคสแบบนี้ ควรเพิ่ม validation เข้ามา เพื่อเป็นการตรวจสอบข้อมูลไว้ด้วยเช่นกันนะครับ
แต่อย่างที่ทุกคนเห็น ทุกอย่างสามารถเป็นไปได้ ขอเพียงสร้าง “Prompt” ที่เป็นไปได้ออกมาได้เช่นกัน
เพิ่มเติมสำหรับ use case อื่นๆ
ซหากใครจะใช้ตัวที่เกี่ยวกับเรื่องเสียงและ video ให้ลึกซึ้งขึ้นจะขอแนะนำตัว Vertex AI ของ Google ที่สามารถทำได้ตั้งแต่
- Speech-to-Text ที่สามารถแกะข้อความจากเสียงออกมาได้ (transcribe)
- Video Processing ที่ถึงแม้ว่าตัว Vertex AI จะไม่สามารถ process ตรงๆได้ แต่สามารถใช้เครื่องมือช่วยอย่าง FFmpeg ในการจัดการ video file เพิ่มเติมได้
สามารถอ่านเพิ่มเติมกันได้ที่ https://cloud.google.com/vertex-ai แน่นอน Vertex AI support Gemini เหมือนกัน เราสามารถใช้พลังของ Gemini ร่วมกับ multimodel เพื่อให้ได้ AI ที่สามารถทำความเข้าใจของได้หลากหลายยิ่งขึ้นออกมาได้เช่นเดียวกัน
รวมถึง จริงๆแล้ว บทความนี้ ผมได้รับแรงบันดาลใจมาจากบทความของพี่ตี๋ Firebase ซึ่งเขาได้ประยุกต์ใช้ chatbot เข้ากับ LINE Messaging API เพื่อให้สามารถทำ LINE AI chatbot ที่มีประสิทธิภาพออกมาได้ สำหรับใครที่สนใจอยากประยุกต์ใช้กับ use case LINE เป็นพิเศษสามารถไปอ่านจากบทความนี้ได้ (บอกเลยว่าทำได้ง่ายมากๆ ถ้าใครที่อ่านหรือดูตามคลิปของหัวข้อนี้ไป สามารถทำตามได้ไม่ยากเช่นเดียวกัน)
https://medium.com/linedevth/linebot-x-gemini-9cd2dc22d9c9
สรุปจากการทดลองทั้งหมด
สิ่งที่ได้เรียนรู้จาก Gemini คือ ดูเผินๆ ความสามารถของ Gemini นั้นเราก็สามารถทำได้เหมือนๆกับเวลาเราใช้ ChatGPT หรือ Bard ที่นำ API มาใช้งานที่ระดับ Chat แต่เมื่อเรานำมาใช้งานร่วมกับการ Programming แล้วมันสามารถเพิ่มความสามารถที่ on top เข้าไปจาก Chat ที่มีอยู่แต่เดิมได้ และทำให้เราสามารถนำมาใช้งานร่วมกับ feature อื่นๆได้ ขอเพียงแค่เรา design prompt ออกมาถูกต้อง และทำการระบุเป้าหมายที่ถูกต้องผ่าน prompt ออกมา ก็จะสามารถได้สิ่งที่ต้องการออกมาได้เช่นเดียวกัน
ดังนั้น หากใครกำลังหา Service AI ตัวไหนที่ช่วยเพิ่มความสามารถให้ application อยู่ ลองเล่น Gemini API กันดูได้นะครับ (รีบเล่นก่อนที่มันจะเลิกให้ใช้ฟรีนะครับ)
Github
https://github.com/mikelopster/gemini-usecase-example
- รู้จักรูปแบบ Authentication ระหว่าง Frontend และ Backendมี Video มี Github
เราจะพามาทำ Authentication กับการ Login กัน ว่ามีกี่วิธีที่สามารถทำได้ และสามารถทำได้ยังไงกันบ้าง ซึ่งจะพาทำกันตั้งแต่ฝั่งของ API Backend

- มารู้จักกับ Prompt Engineering กันมี Video
สรุปแก่นสำคัญของ Prompt Engineering ว่าคืออะไร มีองค์ประกอบอะไรบ้าง และ 4 เทคนิคพื้นฐานที่ช่วยให้เราสื่อสารกับ AI ได้ผลลัพธ์ที่ดีขึ้น

- สรุปเนื้อหา Exploring the Power of Gemini (I/O Extend 24)มี Github มี Slide
สรุปเนื้อหา use case Gemini ทั้ง 3 ประเภท Chat, API และ RAG คืออะไรและมี use case ประมาณไหนบ้าง

- มาทำ Authentication ด้วย NestJS และ Passport กันมี Video
เรียนรู้การผสานพลังระหว่าง NestJS framework ยอดนิยมฝั่ง Node.js กับ Passport
