

สรุปเนื้อหา Exploring the Power of Gemini (I/O Extend 24)
/ 9 min read

Introduction
สวัสดี ผู้เจริญทุกท่าน
บทความนี้ เป็นบทความที่เกิดขึ้นเพื่อจะเขียน “สิ่งที่เราอยากสื่อสารจริงๆ” ใน Session “Beyond Chat: Exploring the Power of Gemini” ที่ผ่านมานะครับ เพื่อให้ทุกคนได้รับความรู้จาก Session ของเรา (ที่ demo แบบบ้งๆไป 😝) เราเลยจะขอแชร์เป็นสรุปเนื้อหาจาก Session ของเราแทน
โดยบทความนี้ จะเป็นบทความสรุปส่วนที่เป็นเนื้อหาสาระสำคัญจากหัวข้อที่เราแชร์ไป โดยเราจะหยิบ topic สำคัญๆที่คิดว่าเป็นประโยชน์กับผู้ที่เคยฟัง Session และ ผู้อ่านที่อาจจะไม่ได้ฟัง Session เรามา ให้ get idea ของ slide ที่เราแชร์ไป ว่า เนื้อหาของ Session นี้มีเนื้อหาประมาณไหนนะครับ
(สำหรับใครอยากซึมซับ เรื่องราวสมมุติที่เรายกตัวอย่างไปของ Jeff และ Johnson ที่อยู่ใน slide ติดตามกันต่อได้ใน ย้อนหลัง Google I/O น้า แต่บอกก่อนว่าอย่าคาดหวังเยอะนะ มันอาจจะบ้งมากๆเลยละ 😂)
โดยใน Session นี้ เราจะมาพูดถึง product AI ที่ Google พูดถึงและย้ำบ่อยมากใน Google I/O อย่าง “Gemini” ที่หลายๆคนมักจะรู้จักกันว่ามันคือ Generative AI chat ที่สามารถสร้างเนื้อหาออกมาได้จากการพูดคุยกับ AI ออกมาได้
ทีนี้สำหรับชาว Developer อย่างเราๆ ถ้าเราลองขยายมุมมองของ Gemini ให้กว้างขึ้น เราจะพบว่า จริงๆแล้ว Gemini (หรือแม้แต่ Generative AI ตัวอื่นๆ) มันสามารถทำได้มากกว่าความเป็น “Chat” ที่เราคุ้นเคยกัน ใน Session นี้ ผมเลยพามาเปิดมุมมองไปพร้อมๆกันว่า หากเราลองแบ่ง Gemini ออกตามผลลัพธ์ที่สามารถสร้างขึ้นมาได้ เราจะสามารถแบ่ง Gemini ออกได้เป็น 3 แกนคือ Chat, API และ RAG
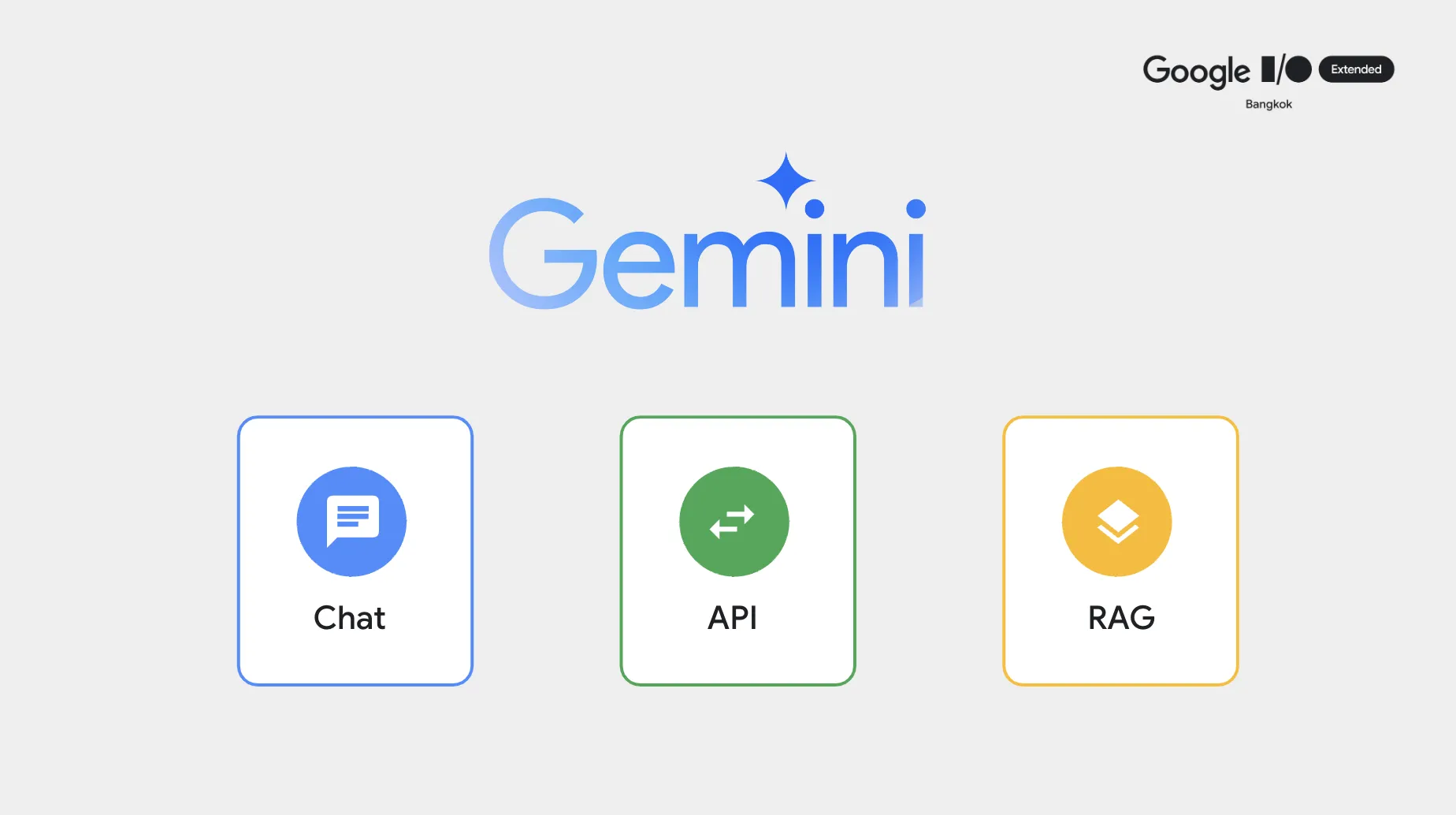
เพื่อให้เห็นภาพได้ชัดเจนขึ้น เราจึงขอเล่าผ่านสถานการณ์ต่างๆที่เราจะมีโอกาสได้ใช้ Gemini ในแต่ละเคสกัน
แกนที่ 1 - Chat
สถานการณ์ที่ 1 = เมื่อข้อมูลทีมีอยู่ไม่ตอบโจทย์ที่มี (แปลงข้อมูล)
โดยปกติ พวก Generative AI นั้นมีความสามารถทำความเข้าใจข้อมูลบางส่วนได้อยู่แล้ว จากการที่เรา input ข้อมูลเข้าไป ดังนั้นจึงมีความสามารถในการนำข้อมูลแปลงจาก แบบหนึ่งไปสู่อีกรูปแบบหนึ่งได้อยู่แล้ว เช่น
- CSV เป็น JSON
- JSON เป็น XML
ใน สถานการณ์สมมุติที่เรายกตัวอย่างใน Session นั้น เราได้รับโจทย์มาให้สร้างเว็บไซต์ แต่เราไม่ทราบว่า จริงๆแล้วข้อมูลที่จะมา input เข้าเว็บไซต์นั้นจะเป็นข้อมูล format อะไร
เนื่องจากเราใช้ Next.js (ที่เป็น Fullstack javascript) ในการพัฒนาอยู่แล้ว เราจึงเลือกใช้ format อย่าง “json” เนื่องจากเป็น format ที่ support กับ javascript อยู่แล้ว และสามารถใช้งานได้โดยตรงจาก Node.js ได้เลย
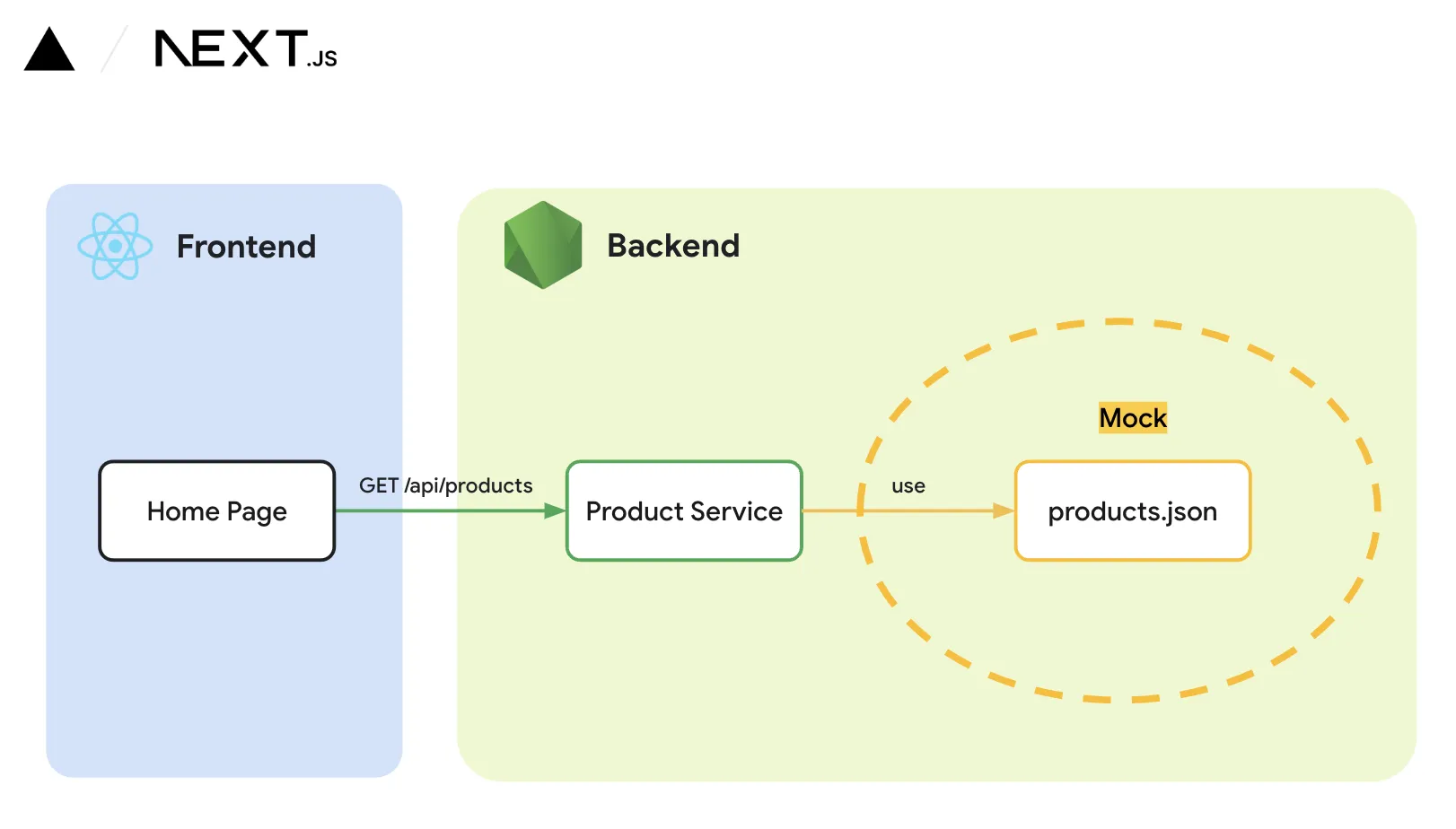
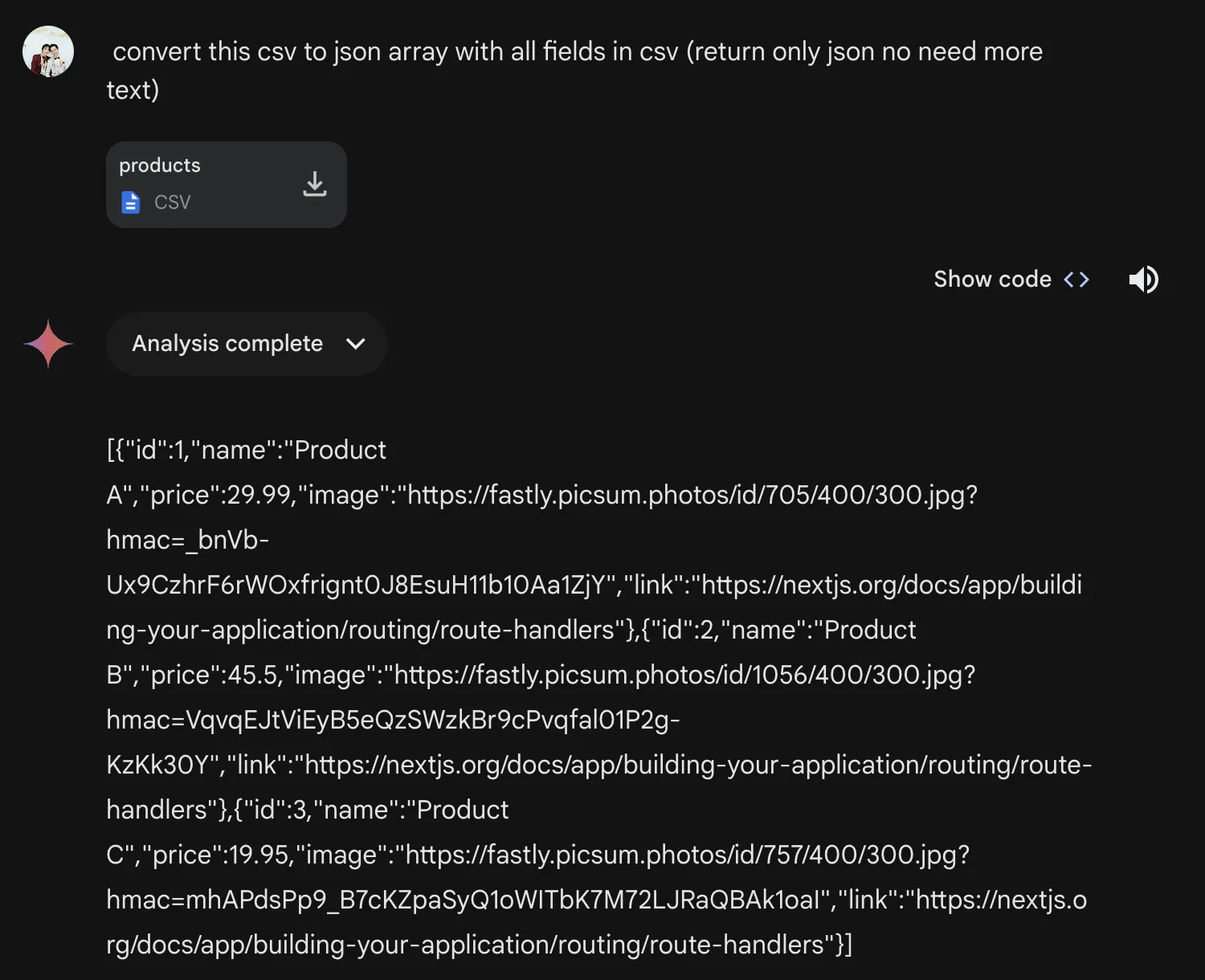
ทีนี้ เราดึงมาเจอเคสว่า ข้อมูลที่ user ส่งมานั้น ดันไม่ใช่ format json (ซึ่งก็เข้าใจได้ user ส่วนใหญ่ไม่ได้พูดคุยกับผ่าน format นี้อยู่แล้ว) แต่เลือกที่จะส่งมาเป็น format CSV แทน
โดย ในเคสนี้ก็สามารถทำได้โดยตรงจาก Gemini Advanced ได้เลย โดยการ upload file เข้าไป (ตัว Advanced หรือตัวเติมเงินจะเป็นตัวที่สามารถ upload file เข้าไปได้) และก็ให้มันพ่น format ตามที่เราต้องการออกมา
ตัวอย่าง prompt ก็เช่นแบบนี้ ก็จะสามารถได้ผลลัพธ์ที่ต้องการออกมาได้
รวมถึง ด้วยความที่มันเป็น Generative AI มันสามารถแปลงของที่ไม่ตรงไปตรงมา แต่มีมุมมองที่เหมือนกันได้ เช่น
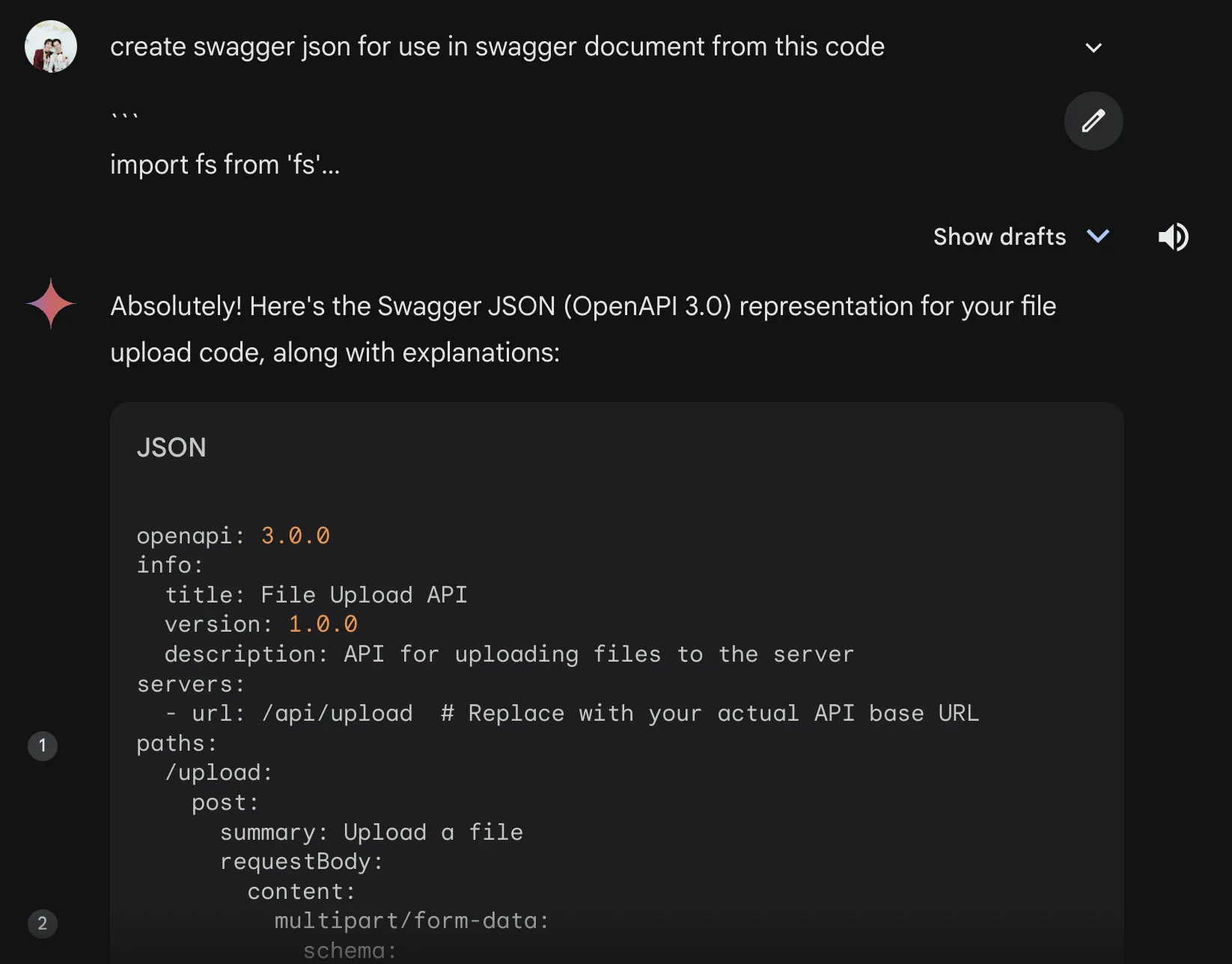
- Frontend Code เป็น mermaid docs
- Backend Code เป็น Swagger
- หรือแม้แต่แปลง Code จากภาษาหนึ่ง เป็น อีกภาษาหนึ่งได้ (เช่น python เป็น node.js)
ซึ่งประโยขน์จากจุดนี้ทำให้เราสามารถใช้ Gemini ทำเรื่องของ “Data Conversion” ได้ ซึ่งอำนวยความสะดวกให้เราจากที่เราต้องมาคอยหาเครื่องมือแปลงข้อมูล เราสามารถใช้ AI ในการช่วยเรื่องนี้ได้ โดยใช้เพียงแค่ Gemini ตัวเดียวสามารถจัดการ use case เหล่านี้ได้
สถานการณ์ที่ 2 = เมื่อเราต้องการให้มันกลายเป็น Automation
ต่อมา เมื่อเราเริ่มรู้สึกว่า use case เดิมที่เรากำลังทำอยู่มันมีความ manual มาก (คือต้องอาศัยการทำโดยคน มาทำการ upload มาทำการแปลง แม้ว่าเราจะใช้ Gemini อยู่ก็ตาม)
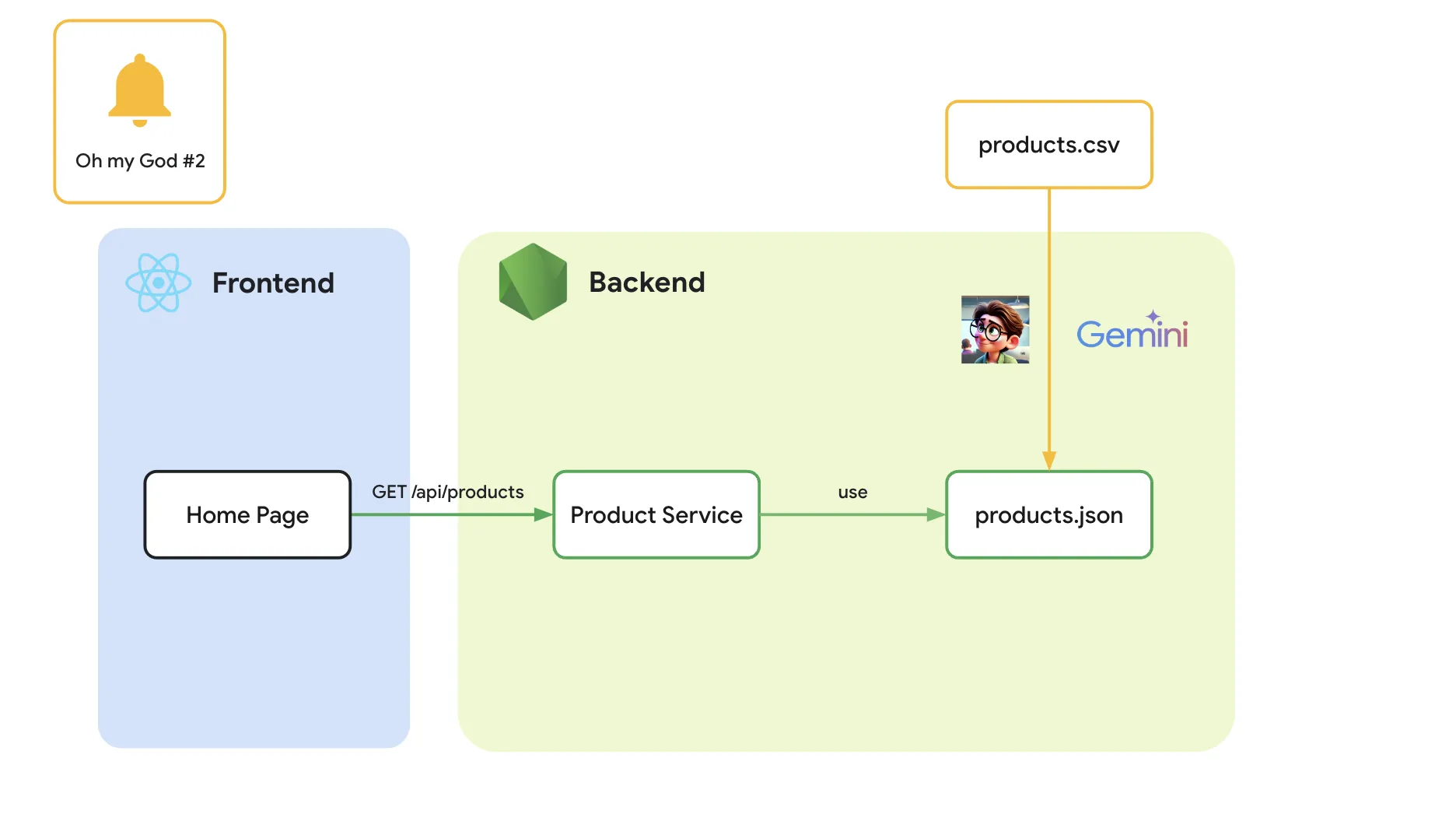
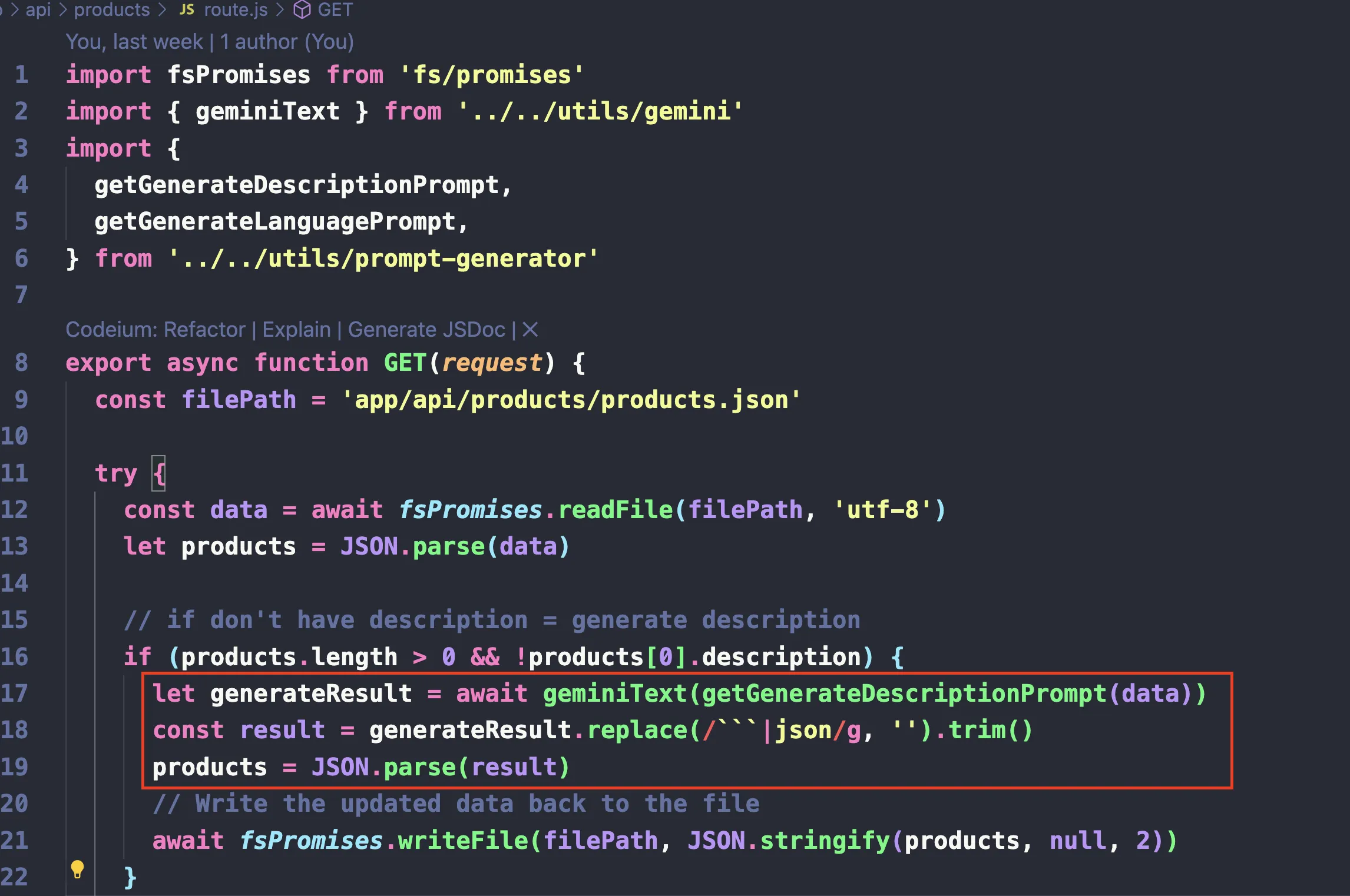
ความสามารถต่อมาของ Gemini (รวมถึงพวก Generative AI หลายๆตัวเองก็มีเช่นกัน) คือ “การสร้าง solution ด้วย code ได้” หรือที่เรามักจะเรียกกันว่า “Code Generation” หรือการที่ Gemini สามารถ generate code ตามโจทย์หรือ prompt ที่ระบุออกมาได้
จาก use case ของสถานการณ์แรกที่แต่เดิม เราจะต้อง upload file เข้า Gemini Advanced เพื่อมาแปลง เราจึงได้เปลี่ยนมาเป็น “สร้าง code เพื่อแปลง file ที่ upload จากระบบเข้ามาจาก csv และทำการ upload file ให้เป็น json แทน” ทีนี้ก็จะขึ้นอยู่กับ skill programming ที่เรามีและว่าเราถนัดภาษาไหนอยากได้ภาษาอะไร โดยความเจ๋งของพวก Generative AI อย่าง Gemini คือ “เราสามารถ code ภาษาอะไรที่เราถนัดก็ได้ ภายใต้ Solution ที่เราต้องการ”
use case นี้ จึงเป็นการพยายามนำทาง Gemini ให้ทำการ code ตัว solution นั้นออกมา แทนที่จะให้ Gemini แปลงข้อมูลนั้นโดยตรงนั่นเอง โดยในเคสนี้สิ่งที่เราให้ Gemini ทำคือ
- ให้ Gemini สร้างหน้า upload ขึ้นมา (ภายใต้ Next.js ตัวเดิมที่เราทำ)
- ให้ Gemini สร้าง api สำหรับ upload ขึ้นมาโดยรับ file csv เข้ามา
- ให้ Gemini สร้าง code สำหรับอ่านข้อมูลจาก csv
- ให้ Gemini สร้าง code สำหรับแปลงข้อมูลจาก csv เป็น json แล้ว upload ลงตำแหน่งไฟล์ตำแหน่งเดิมเข้าไป
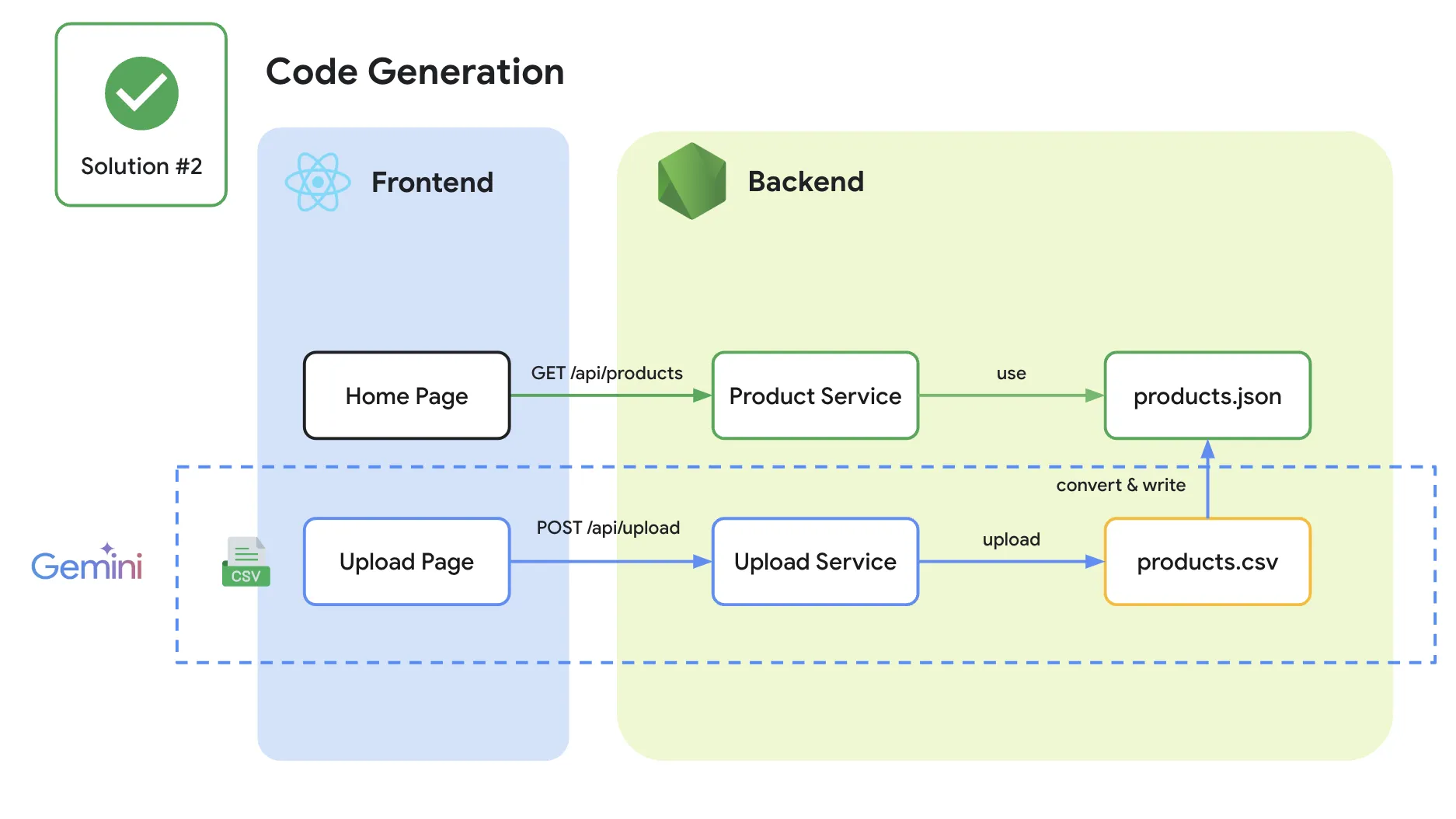
เพียงเท่านี้ เราก็สามารถใช้ solution นี้เปลี่ยนจากแต่เดิมที่ต้องไปใช้บริการผ่าน Gemini Advanced ให้มาทำผ่าน code ที่เราสร้างผ่าน Gemini ออกมาแทนได้
สิ่งนี้ถือเป็นข้อได้เปรียบสำหรับคนที่เป็น developer มาก เนื่องจาก หลากหลาย solution นั้น เป็น solution ที่เราสามารถทำ automate ได้จากการทำงานผ่าน code เข้าไป ซึ่ง Generative AI อย่าง Gemini นั้นสามารถช่วยคิดเรื่องนี้ได้ แม้ว่าบางทีเราจะ no idea ในการ code มันก็สามารถที่จะ guide code ออกมาให้เราได้ (เอาจริง แม้เราจะ demo ในเวทีพลาดก็ตาม แต่เรากล้าพูดเลยว่า หากพยายาม prompt สักหน่อย เราสามารถได้คำตอบหลายๆเคสมาได้ไม่ยากเลย และในชีวิตประจำวัน เราแทบจะ prompt มากกว่า code แล้วด้วยซ้ำ 😂)
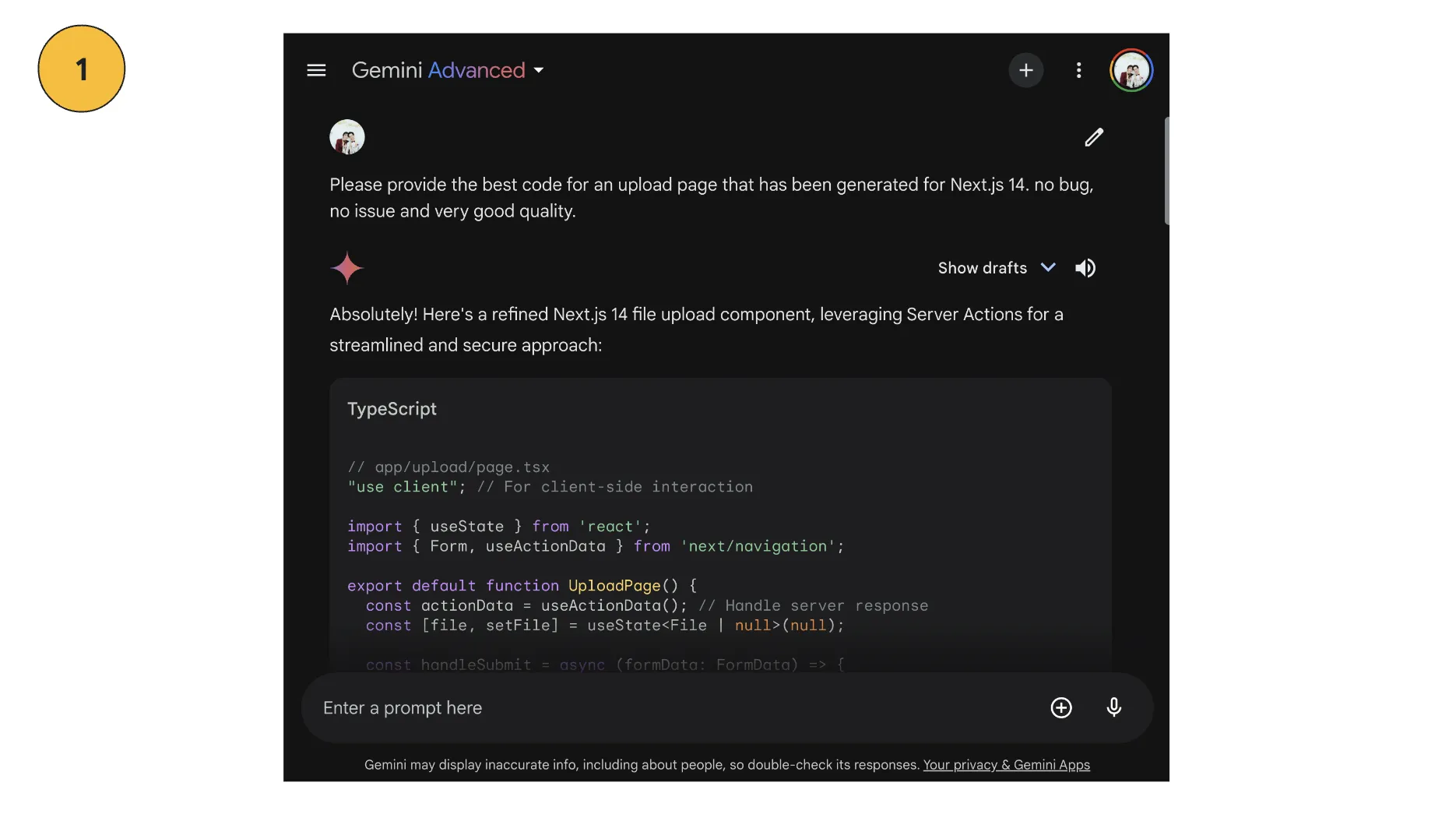
ทีนี้ สิ่งที่เราอยากเพิ่มเติมเอาไว้นั่นคือ Google มี solution สำหรับการทำ Code generation อยู่ทั้งหมด 2 วิธีคือ
-
Gemini Advanced = ส่ง prompt / สิ่งที่อยากได้แล้ว ได้ code ออกมา
-
Gemini Code Assist = comment หรือ chat แล้วได้ code ผ่าน vs code Editor
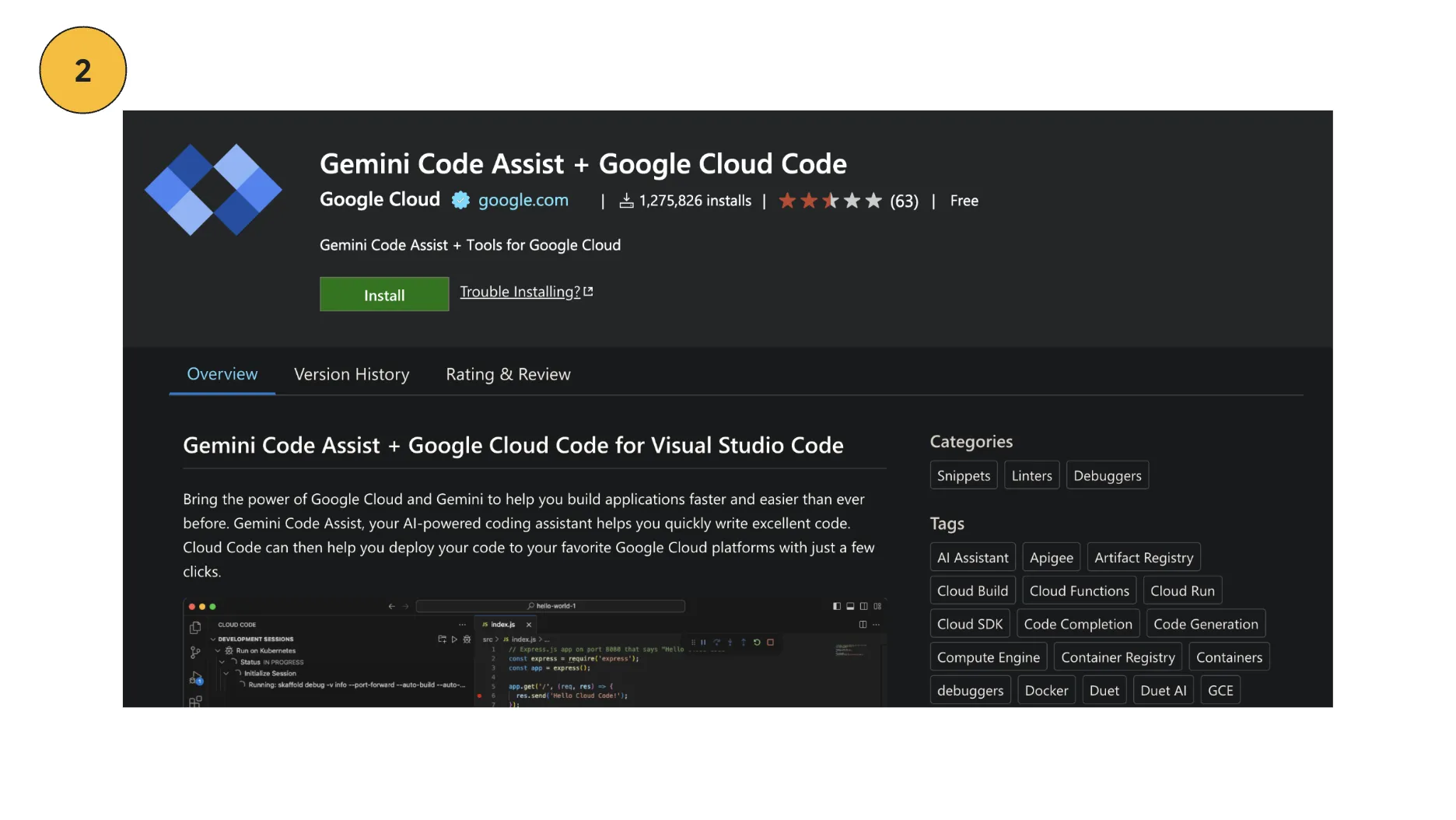
สำหรับ Gemini Code Assist ทุกคนสามารถลองไปดูกันเพิ่มเติมได้ ณ ตอนที่ผมเขียนบทความอยู่นี้ “ยังไม่เสียตัง” นะครับผม ลองไปดูตัวอย่างผ่าน plugin หรือ เว็บมันได้ ถ้าอธิบายแบบสั้นๆเลย “มันคือ github copilot ฉบับ gemini นั่นแหละ 555” (แต่มันเก่งกว่านั้นนิดนึง ตรงมันสามารถใช้งานร่วมกับ GCP ได้ ไว้เราค่อยมาเล่าเจาะลึกตัวนี้อีกที)
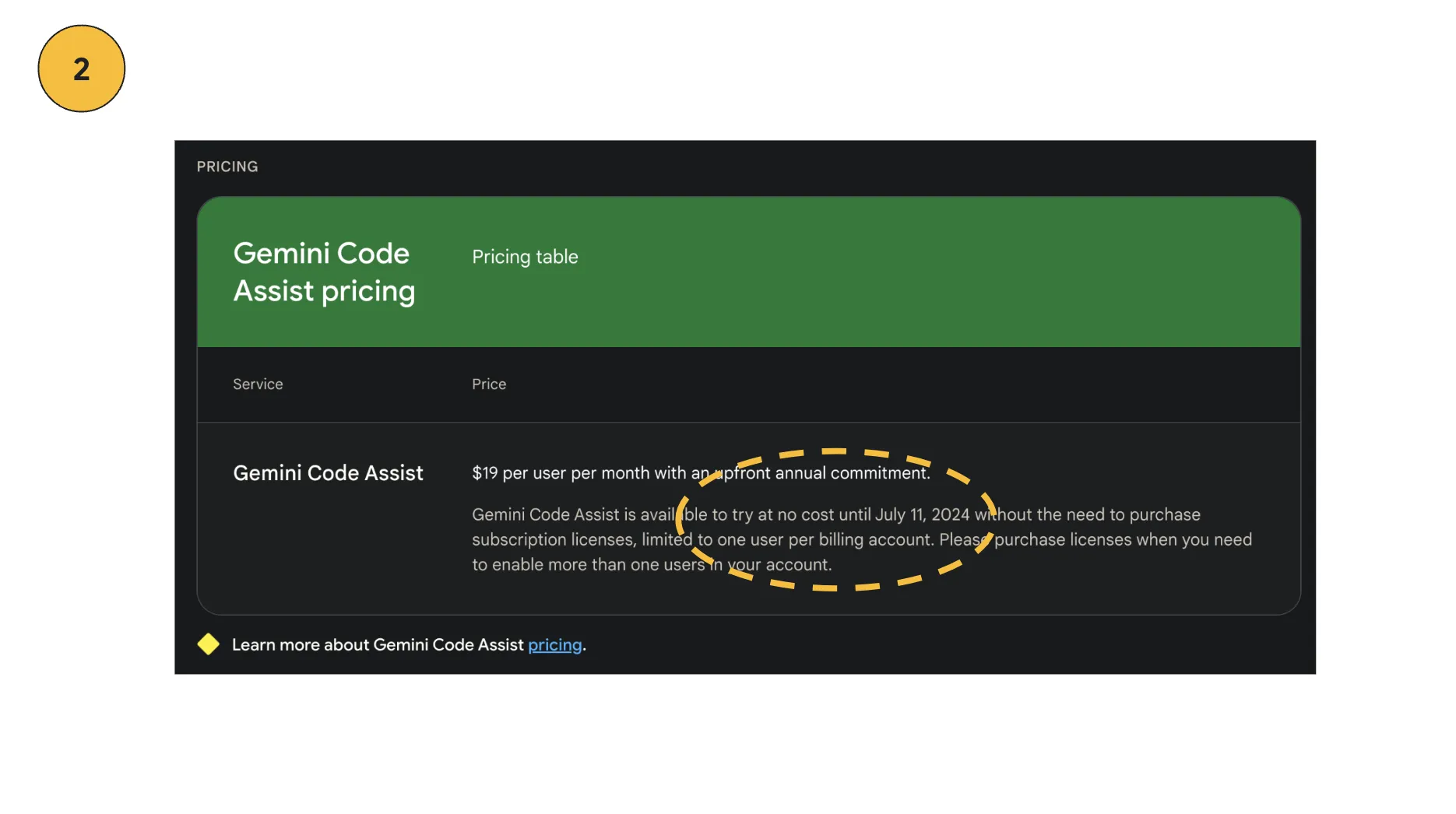
** ในบทความนี้ เราจะขอให้เป็น keyword โดยประมาณไว้ก่อน สำหรับใครที่สสนใจเรื่อง code generation เดี๋ยวเรามีหัวข้อโผล่มาเป็น video ให้ดูกันเร็วๆนี้แน่นอน ขอไปตั้งหลักกับเหตุการณ์ที่เกิดขึ้นก่อนนะครับ 😂

แกนที่ 2 - API
สถานการณ์ต่อมา คราวนี้เป็น สถานการณ์ที่จะเพิ่มเติม “ความ realtime” เข้ามา โดย โจทย์คือเรามีเคสที่ต้องสร้าง Content ครับ แต่การสร้าง Content นั้นต้อง “เกิดขึ้นแบบ dynamic ภายใน application” เช่น
- ต้อง generate description โดยใช้ชื่อ product ออกมา (เนื่องจากเจ้าของงานขี้เกียจคิดชื่อ product)
- ต้อง แปลภาษาใหม่ๆขึ้นมาได้ โดยที่ไม่ต้องใช้ locales ในการกำกับภาษา (เนื่องจาก ไม่มีคนช่วยแปลให้ เราเลยจะใช้ AI ช่วย)
- หรืออนาคต อาจจะเป็นเคส OCR กับรูปภาพ ทำการดึงข้อมูลเมนูจากรูปภาพออกมาทันทีที่ upload เข้าระบบไป (เราจะไม่ใช้ OCR Service เนื่องจากมันจะเปลืองเงินนะ)
ซึ่งแน่นอน สถานการณ์พวกนี้ เราก็สามารถนำ Gemini มาประยุกต์ใช้ได้ โดยใช้งานผ่าน Gemini API แทน
Gemini API (https://ai.google.dev/)** คือ **ส่วนต่อประสาน API สำหรับ Gemini ที่ช่วยให้นักพัฒนาสามารถเข้าถึงและใช้ประโยชน์จากความสามารถของ Gemini “ภายใน application” ได้ จากแต่เดิมที่ต้องมา prompt ผ่านหน้าจอของ Gemini Chat ออกมา (ซึ่งเอาจริงๆความสามารถนี้ไม่ได้มีแค่ Gemini เจ้าเดียวนะ ทุกๆเจ้าในตลาดเอาจริงก็สามารถทำได้เช่นกัน และความสามารถในการ Generate อะไรได้บ้าง หรือ support ข้อมูลอะไรบ้างก็จะขึ้นอยู่กับเจ้านั้นๆ)
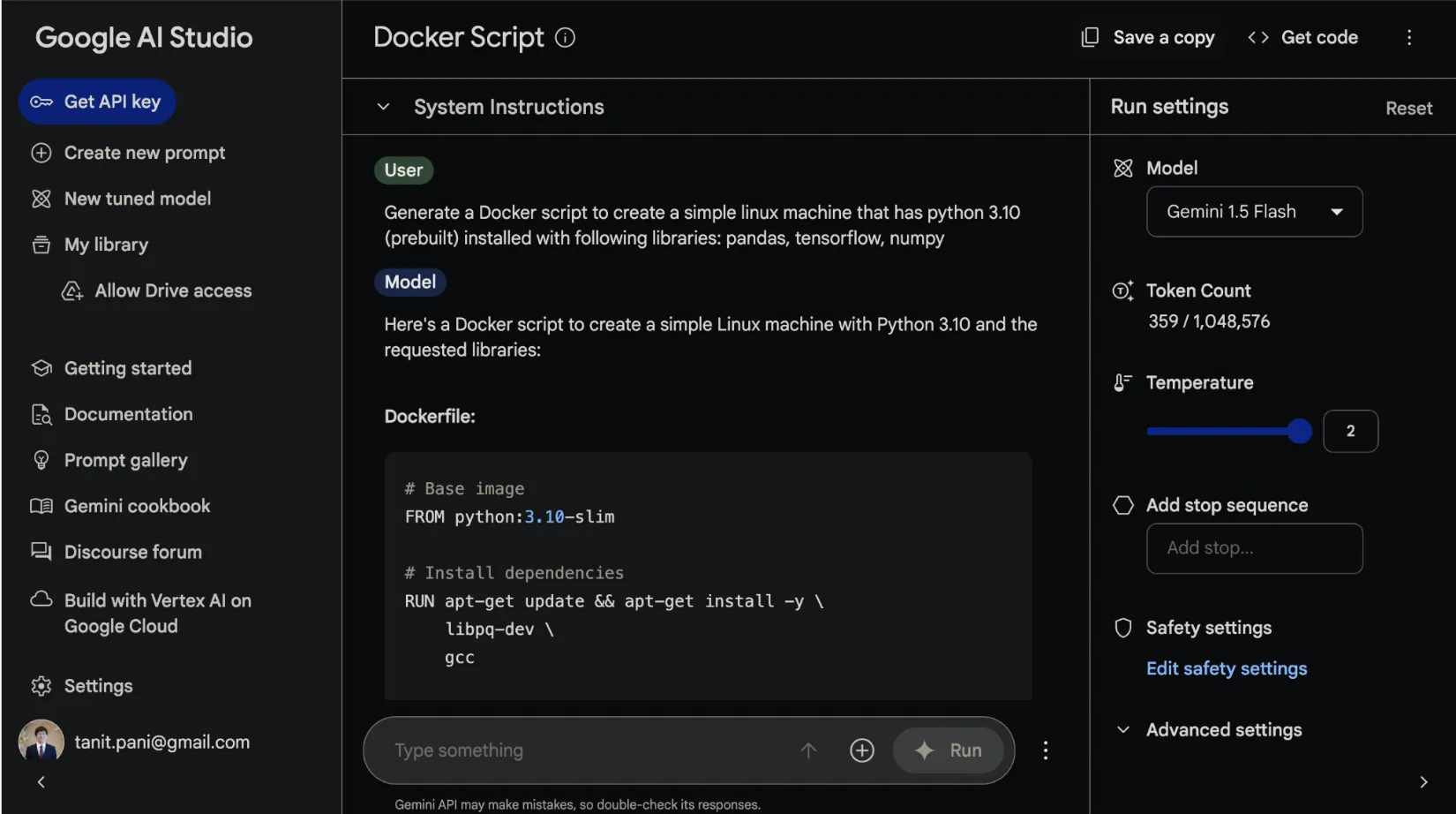
โดย Gemini API นั้น ได้อำนวยความสะดวกโดยการให้สามารถทดสอบผลลัพธ์การใช้งาน API ได้ ผ่าน Google AI Studio รวมถึงได้เตรียม source code สำหรับให้ไปใช้งานต่อใน application ภาษาต่างๆไว้ให้พร้อมด้วยเช่นเดียวกัน
ไอเดียของการใช้ Gemini API สำหรับ Session นี้คือ เรากำลังเจอกับสถานการณ์ที่ท้ายที่สุด ไม่ว่าจะทำยังไงก็ตาม เราจะต้องลงเอยด้วยการที่ “มี user สักคนต้องทำ manual” ที่ operation หนึ่งขั้นตอน เช่น
- อยากได้เว็บหลายภาษา = ต้องมีคนแปลภาษา เพื่อทำเว็บหลายภาษา
- อยากได้เว็บที่มี description ของ product เพิ่ม = ต้องมีคนคอยเขียน description หากมี product ใหม่ขึ้นมา (แต่บริษัทดันไม่มีคนเขียน Content ให้)
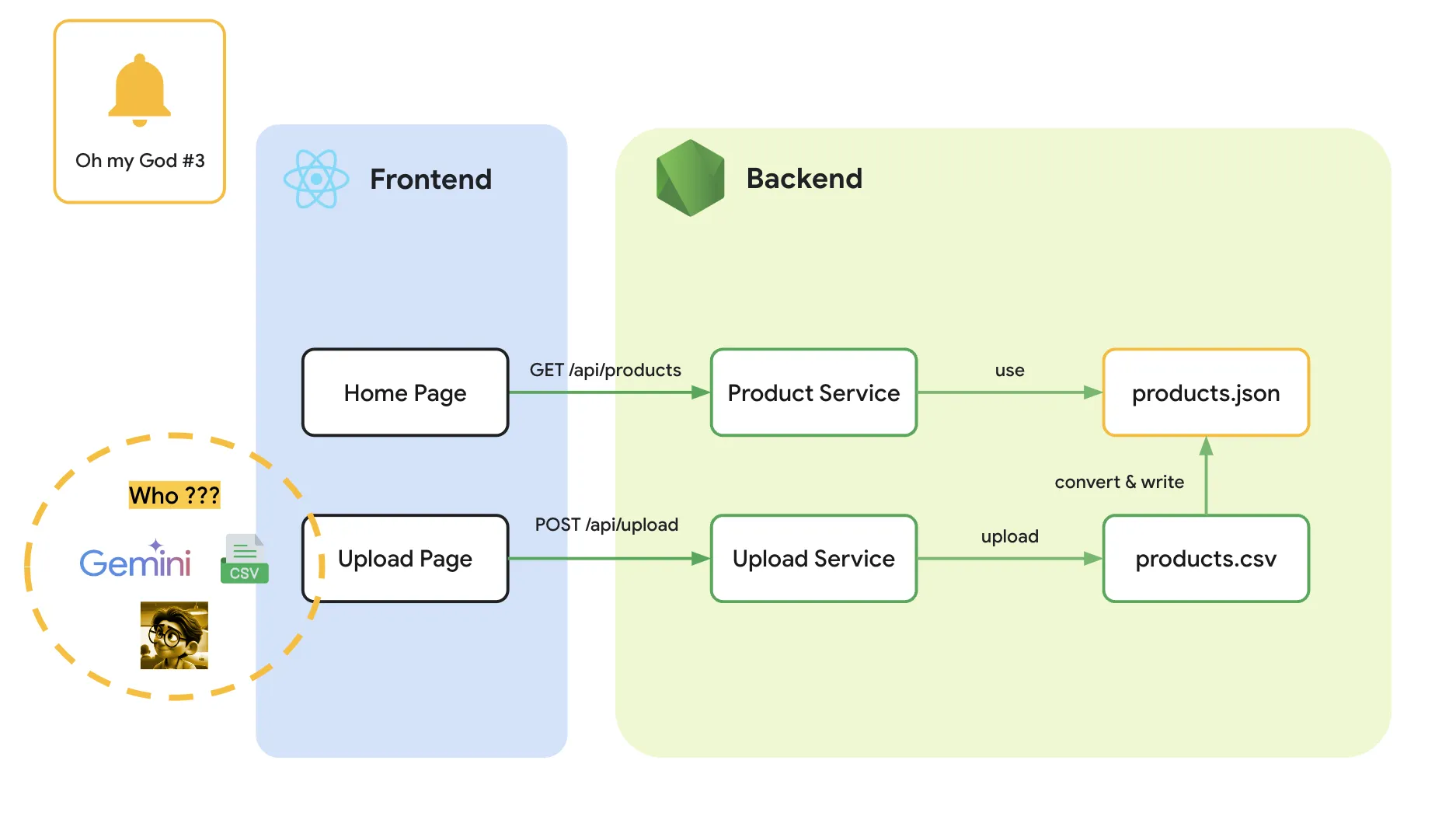
และไม่ว่าจะคิดยังไง (แม้แต่พยายามที่จะใช้ Gemini Advanced) ก็ยังค้นพบว่า “ไม่สามารถแทน user สักคน” นี้ออกไปจากวงโคจรได้ (มันจะต้องมีสักคนมาใช้งาน Gemini Chat และเอาข้อมูลนั้นมาใส่ระบบอยู่ดี)
ดังนั้น สิ่งที่เราทำคือ เราจึงพยายามแทน “user สักคน” นั้น ด้วย “Gemini API” และให้ operation ทุกอย่างไปจัดการผ่าน Gemini API พร้อมกับ “Prompt ที่เรามีการ setup” เอาไว้แทน
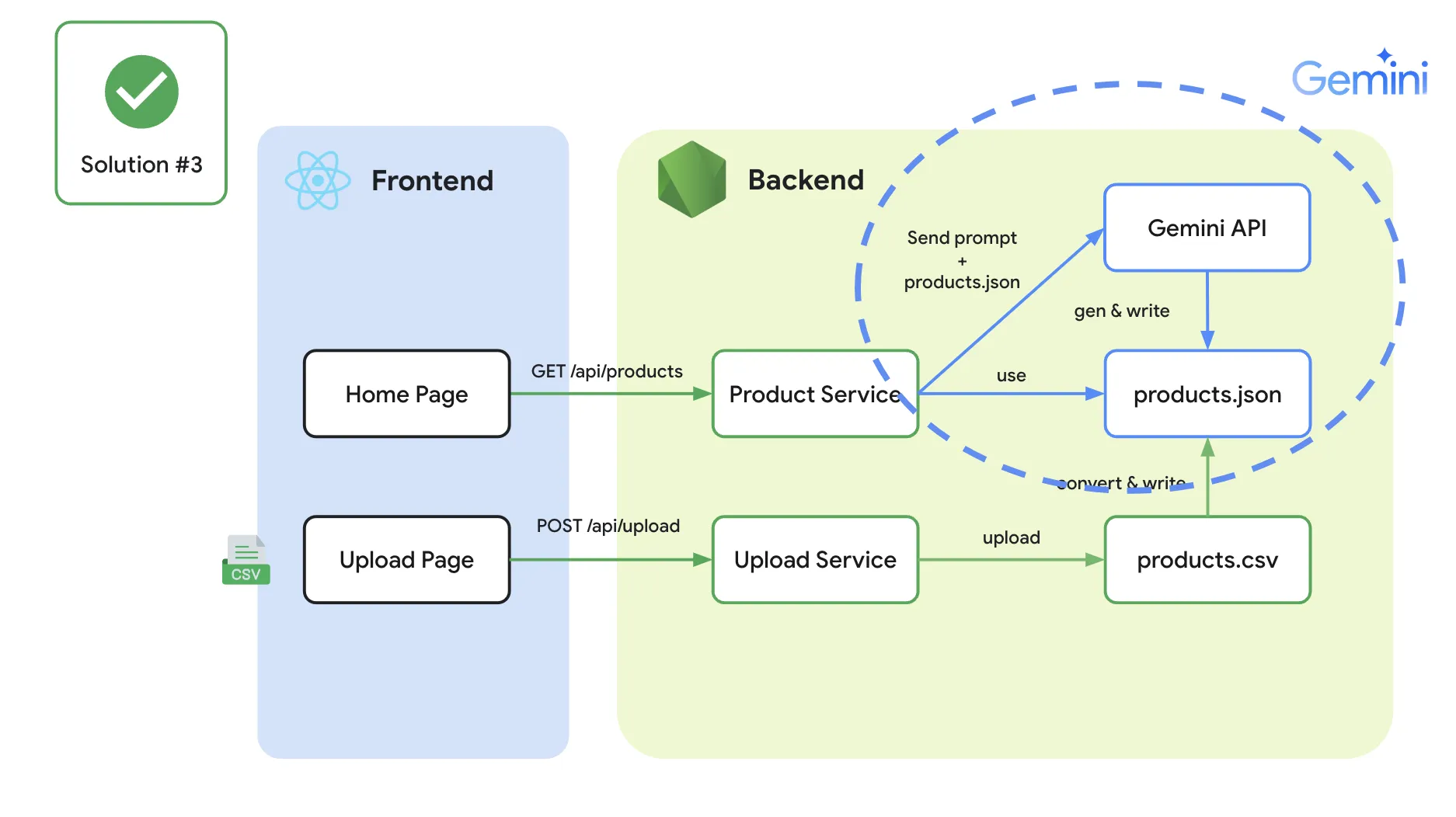
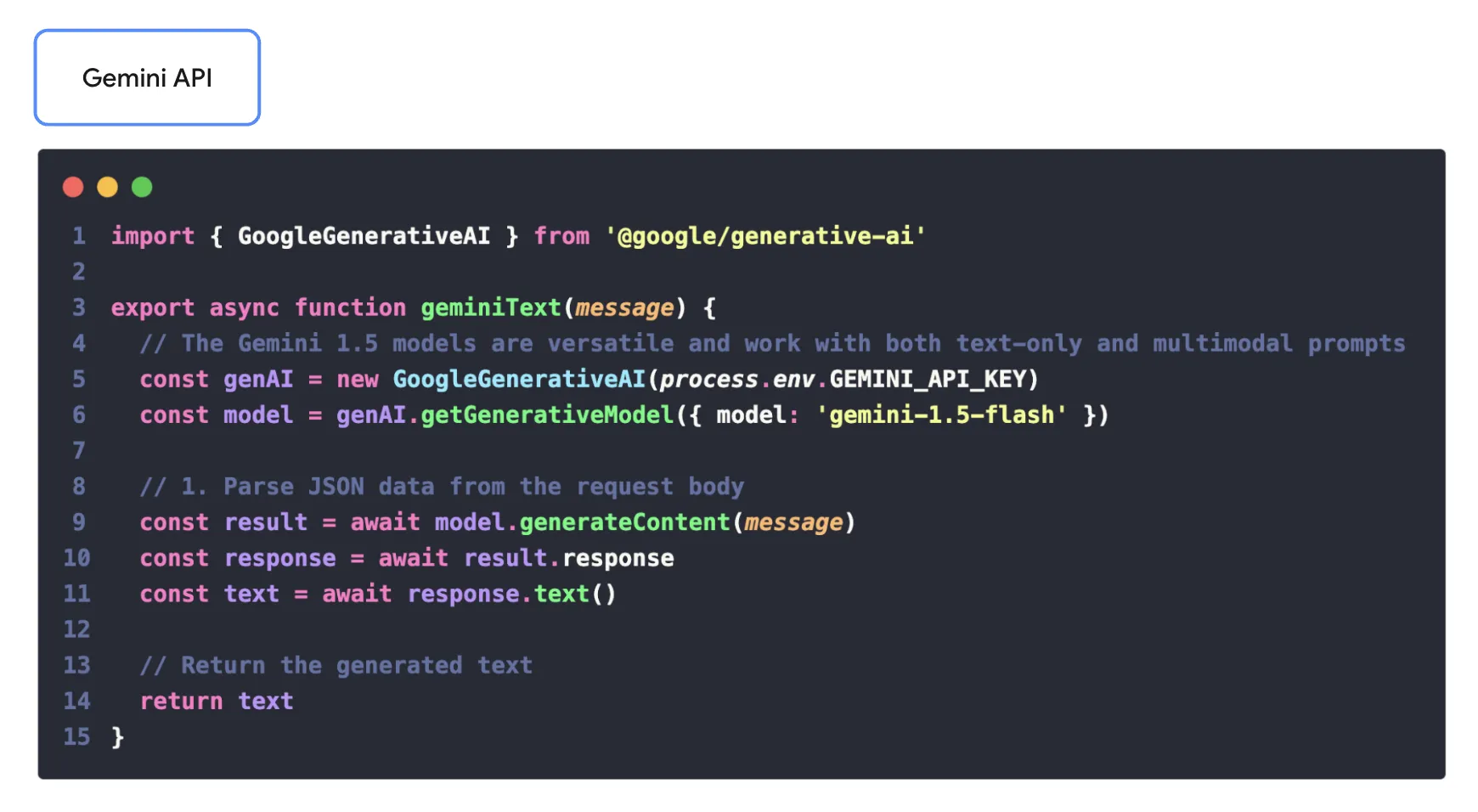
เพียงเท่านี้ เราก็จะสามารถตัด process manual ทิ้งออกไปได้แล้ว และนี่คือตัวอย่างของ code จาก Gemini SDK ผ่าน node.js
และตัวอย่างการ setting prompt ที่ให้ได้ผลลัพธ์ออกมา ซึ่งเราสามารถแยก function ออกมาจากกันได้ เช่นแบบนี้

และตัวอย่างการใช้งานใน code ก็สามารถที่จะเรียกใช้งานลักษณะนี้ได้เลย (การทำแบบนี้ จะทำให้เราสามารถ reuse code ส่วน gemini + สามารถ design ผลลัพธ์จาก prompt function ออกมาได้เลย)
เพียงเท่านี้ ไม่ว่าเคสไหนๆ เราก็สามารถ design ให้ Gemini API มาเป็นส่วนหนึ่งของ application เราได้แล้ว เพียงแค่ “เปลี่ยน prompt” ให้เป็นไปตามจุดประสงค์ที่ต้องการออกมา
ทีนี้ prompt เองก็เป็นส่วนสำคัญสำหรับการใช้งานร่วมกับ Gemini API เช่นกัน ว่ากันว่าผลลัพธ์จะออกมาดี หรือ ไม่ดี ส่วนสำคัญขึ้นอยู่กับ prompt ด้วยเช่นกัน

ซึ่งด้วยความสำคัญระดับ 5 ดาวนี้เอง ในปัจจุบัน ก็ได้มีคนทำ prompt guide ไว้ให้สำหรับชาว prompt engineer ที่อยากได้เทคนิคแบบละเอียด จริงจัง และเป็นหลักการ สามารถไปอ่านจากที่นี่ได้ https://www.promptingguide.ai/ (หลายไอเดียสามารถนำมาประยุกต์ใช้กับ application จริงๆได้ด้วยเช่นกัน)
แต่แน่นอน สำหรับคนขี้เกียจ (เช่น เรา) เราจะขอแนะนำ solution ที่ง่ายกว่านั้น นั่นคือ “การให้ Gemini ช่วย generate prompt ให้” ดั่งคำกล่าวที่ว่า “ไม่มีใครรู้วิธีใช้งานดีที่สุด เท่ากับตัวมันเองอีกแล้วละ”
เช่น หากเราอยากได้ prompt สำหรับเปลี่ยนภาษาจากภาษาหนึ่งไปอีกภาษาหนึ่ง แต่เราไม่แน่ใจว่า เราควรจะใช้ prompt อะไรดี เราก็ลองถาม Gemini Advanced ดูเลย
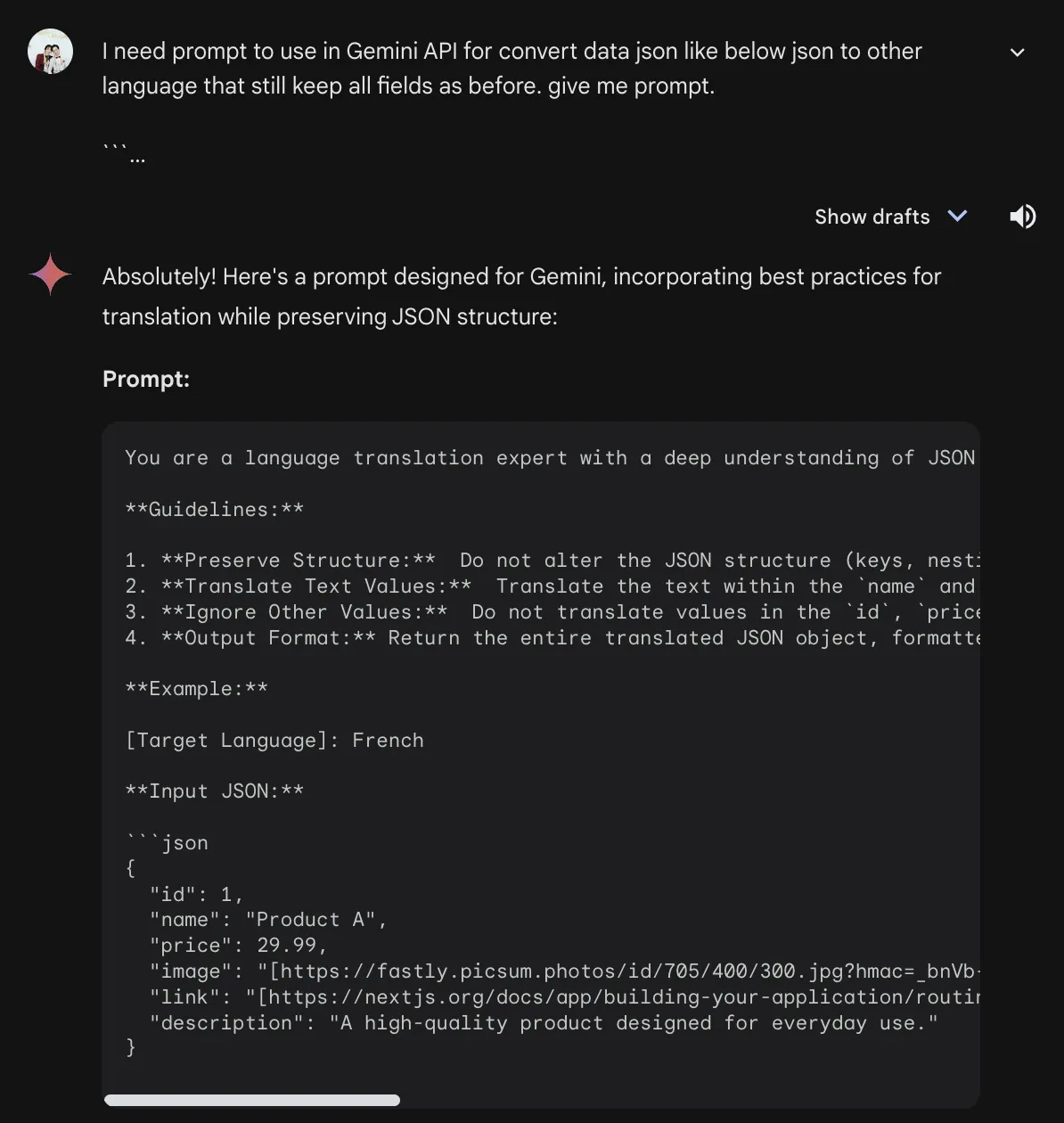
เพียงเท่านี้เราก็จะได้ prompt ตัวอย่างไปใช้งานต่อได้แล้ว (สามารถระบุได้เช่นกันนะครับ ว่าเราอยากได้ code function เป็นของภาษาอะไร ก็จะอำนวยความสะดวกให้นำไปใช้งานได้เลย ด้วยวิธีเดียวกันกับการทำ code generation นั่นแหละ)
และนี่คือตัวอย่างผลลัพธ์โดยประมาณของการใช้ Gemini API ร่วมกันกับ Node.js API
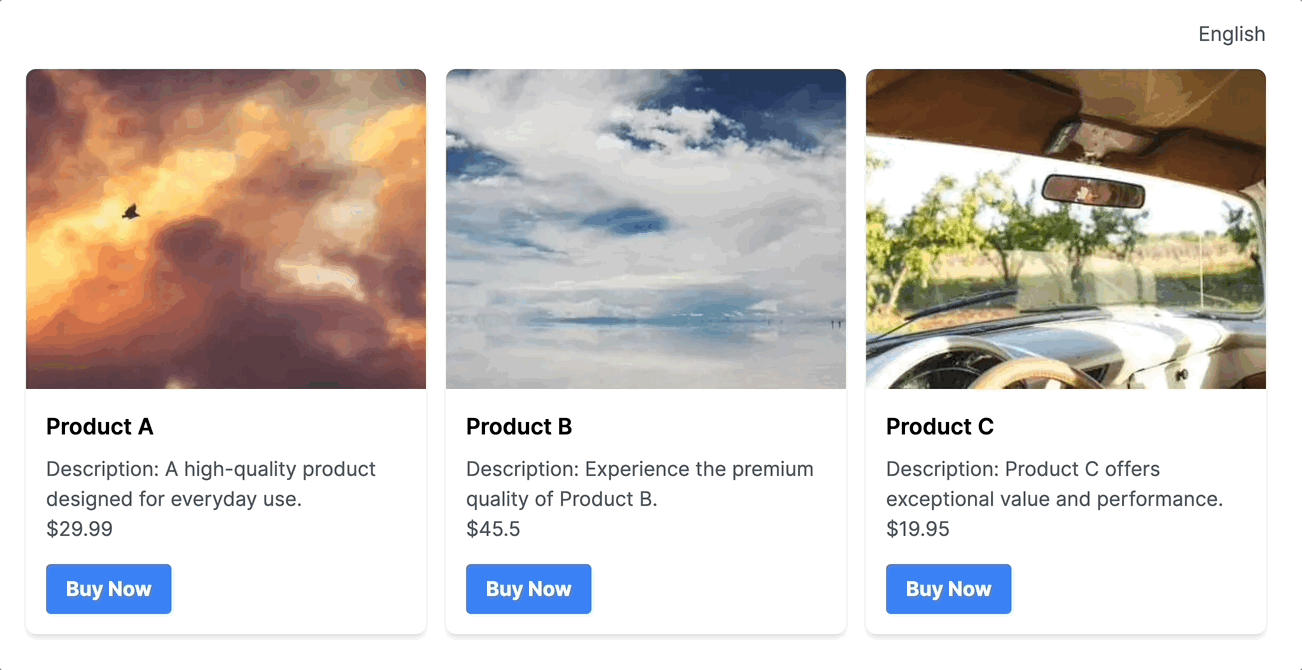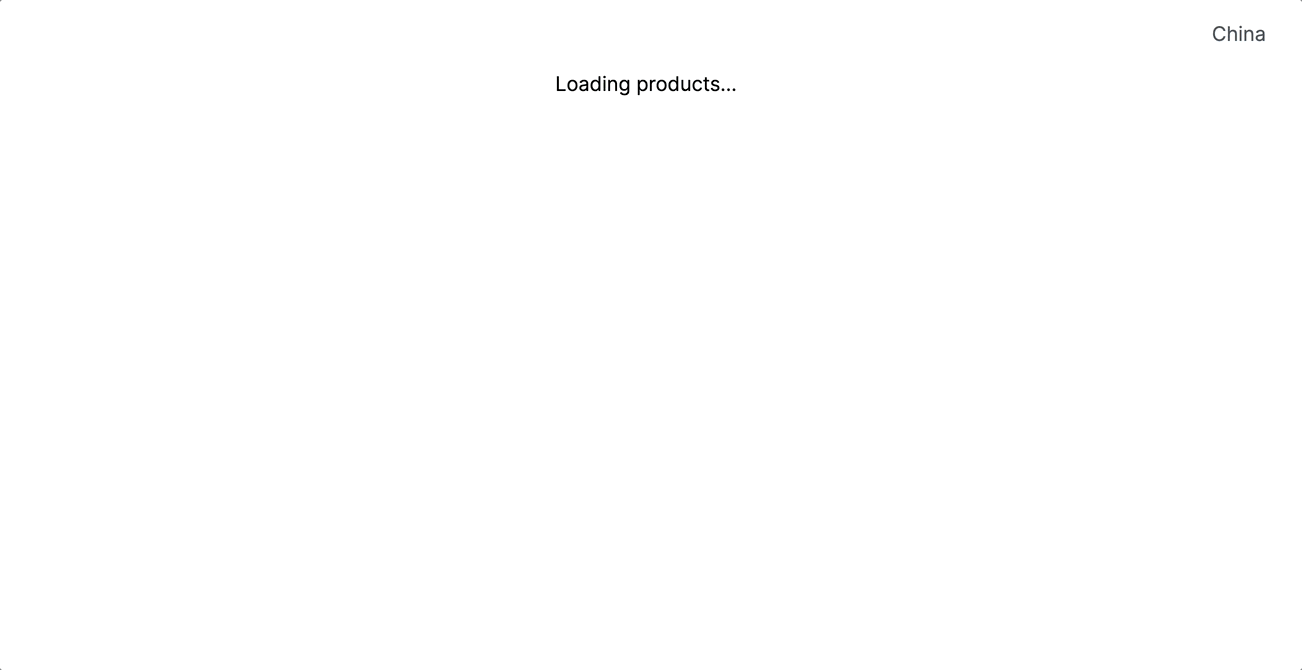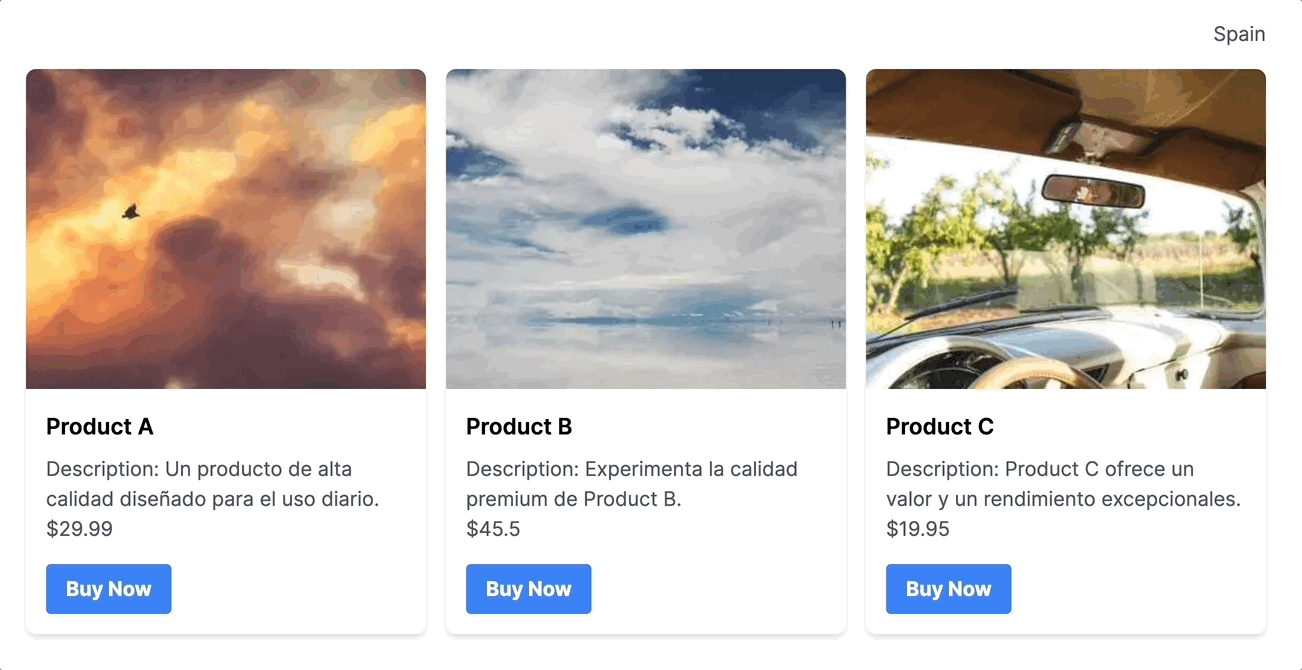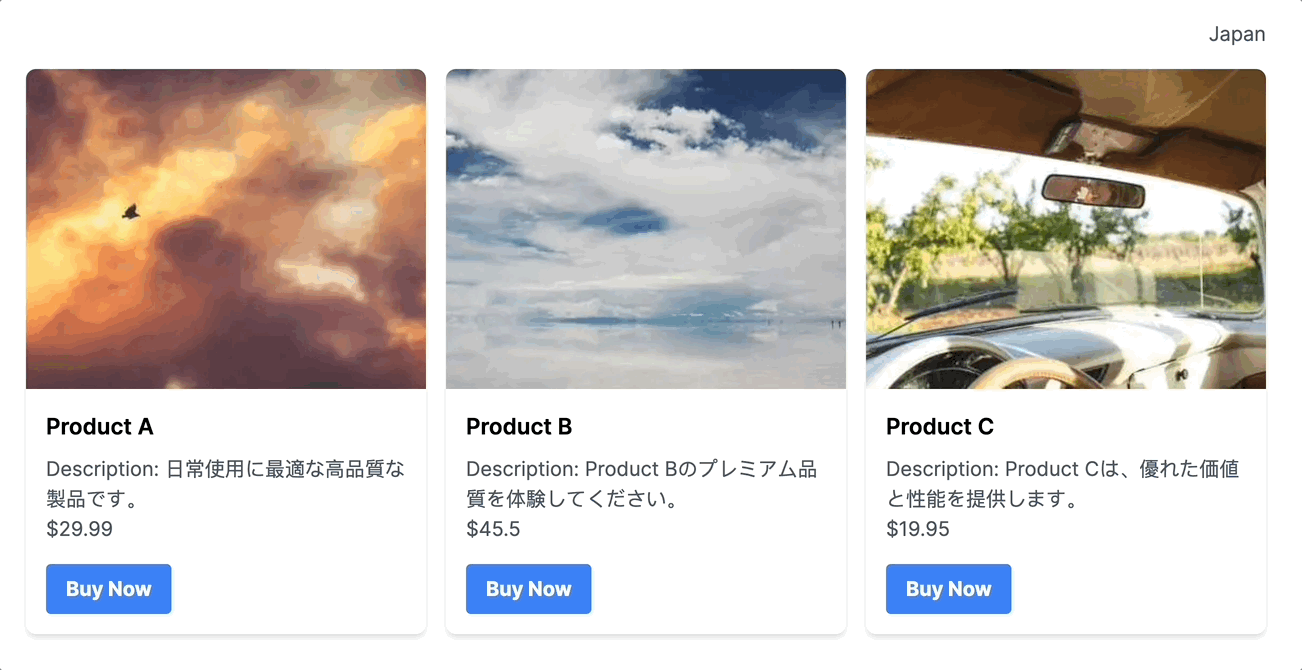
นอกเหนือจากเรื่อง Content Generation (จากตัวอย่างที่กล่าวมา) Gemini เองยังมีความสามารถในการกินข้อมูลขนาดที่ใหญ่มาก เช่น กินเอกสารทั้งฉบับเข้าไปได้, อ่านภาพเข้าไปได้ รวมถึง สามารถเข้าใจ context ของข้อความ และสามารถตอบกลับไปข้อความได้ดูเป็นธรรมชาติราวกับเข้าใจ context ของข้อความนั้น
นั่นเท่ากับว่า อีกเรื่องที่ Gemini API สามารถนำมาประยุกต์ใช้คือ “Automated workflows” บางส่วนภายใน application ของเราได้ หากเรามีเคสเช่น
- การสกัดข้อมูล ออกจาก pdf (เช่น ดึงข้อมูลใบเสร็จ)
- วิเคราะห์จากรูปภาพ (เช็คว่า ภาพนี้มีแมวอยู่กี่ตัว, มีการถ่ายภูเขามาจริงหรือไม่, นี่คือใบเสร็จหรือป่าว)
- ทำ Report ข้อมูลจากไฟล์ csv (Prediction ยอดขายจากข้อมูลที่มี)
Gemini API ก็สามารถที่จะนำมาประยุกต์ใช้ได้เช่นกัน ดังนั้น keyword ของการใช้งาน Gemini API ของเราจะมี 2 keyword คือ
“Integration Application” + “Automated Workflow” เมื่อไหร่ก็ตามที่เราต้องการ design ให้ทุกอย่างเป็นอัตโนมัติ และมี AI เข้าช่วยภายใน application = เมื่อนั้นแหละ Gemini API จะมีประโยชน์ในการช่วยเรื่องนี้อย่างมาก

แกนที่ 3 - RAG
ทีนี้มาถึงสถานการณ์สุดท้าย เราอยากทำระบบโดยใช้ Generative AI มาช่วย เรารู้จักทั้ง Gemini API และเรียบร้อย (จากหัวข้อก่อนหน้า) แต่เราดันมีสถานการณ์ที่ต้องใช้งาน “ร่วมกับข้อมูลที่มี” เช่น
- การสร้าง chatbot ที่ต้องถามตอบประเด็นที่เกี่ยวกับ product ชิ้นนั้น ตามเอกสาร document ที่มี
- หรือ ต้องทำ search engine ที่เราอยากใช้ภาษาธรรมชาติแบบที่เราใช้ แต่ต้องสามารถค้นหาข้อมูลจากภายใน database ของเราออกมาได้
ในเคสนี้ เราจำเป็นต้องเพิ่ม “ของบางอย่าง” เข้าไปใน Generative AI ทีนี้ หลายคนอาจจะสงสัยว่า ถ้างั้นเราก็ใช้ Idea อย่างการ “ใส่ข้อมูล” + Gemini API ก็สามารถทำสิ่งเหล่านี้ได้เช่นกัน (เหมือนกับตอนที่เราทำตัวอย่าง prompt เข้าไปในหัวข้อ Gemini API ของเคส content generatation ที่ทำการสร้าง description จาก product ที่ใส่ product json เข้าไปใน prompt โดยตรงเลย)
ปัญหาอย่างหนึ่งที่น่าสะพรึงกลัวคือ Generative AI พวกนี้จะมีอาการหนึ่งที่เรามีศัพท์เทคนิคที่เรียกกันว่า “AI Hallucination”
AI Hallucination หรือ “อาการหลอนของ AI” คือปรากฏการณ์ที่ model AI สร้างข้อมูลที่ไม่ถูกต้อง ไม่สอดคล้องกับความเป็นจริง หรือสร้างข้อมูลที่ไม่มีอยู่จริงขึ้นมา โดยนำเสนอข้อมูลเหล่านี้ราวกับว่า “เป็นความจริงที่เชื่อถือได้” เช่นตามภาพนี้ ที่ Generative AI ดันสามารถตอบผู้ชนะ รางวัลปี 2025 มาได้เฉย ทั้งๆที่ปีที่เขียนอยู่นี้เป็นปี 2024

ซึ่งอาการนี้นั้น แม้ว่าเราจะพยายามใส่ข้อมูลร่วมกับ Gemini API ไปยังไงก็ตาม ก็มีแนวโน้มสูงมาก ที่ Gemini API (หรือ Generative AI ทั่วๆไป) “จะไม่ใช้ข้อมูลที่ใส่เข้าไป” และทำให้ตอบข้อมูลอื่นที่นอกเหนือจากขอบเขตมา (เช่น หากเราใช้กับ Search Engine ของเรา มันอาจจะไปตอบ product ร้านอื่นแทนที่จะตอบของร้านเราก็ได้)
(** เกร็ดเล็กน้อยสำหรับ AI Hallucination : อาการหลอนของ AI มองในมุมร้ายๆ คือ “เห้ยทำไม มันให้ข้อมูลผิดออกมา เชื่อถือไม่ได้ ไม่ใช้และ” แต่ถ้าเรามองอีกมุมหนึ่ง “เราอาจจะได้มุมมองแปลกใหม่ที่เราไม่เคยเห็นมาก่อนจาก AI ออกมา” ได้เช่นกัน เพียงแต่ เราต้องตั้งอยู่บนพื้นฐานว่า “อย่าเชื่อทุกสิ่งที่ AI ให้มา” แค่นั้นแหละ)
ทีนี้ เพื่อป้องกันปัญหานี้ โลกเราก็เลยผลิตอีกหนึ่งเทคนิคที่ช่วยตีกรอบ AI ให้อยู่กับร่องกับรอยมากขึ้น นั่นคือ “Retrieval-Augmented Generation (RAG)”
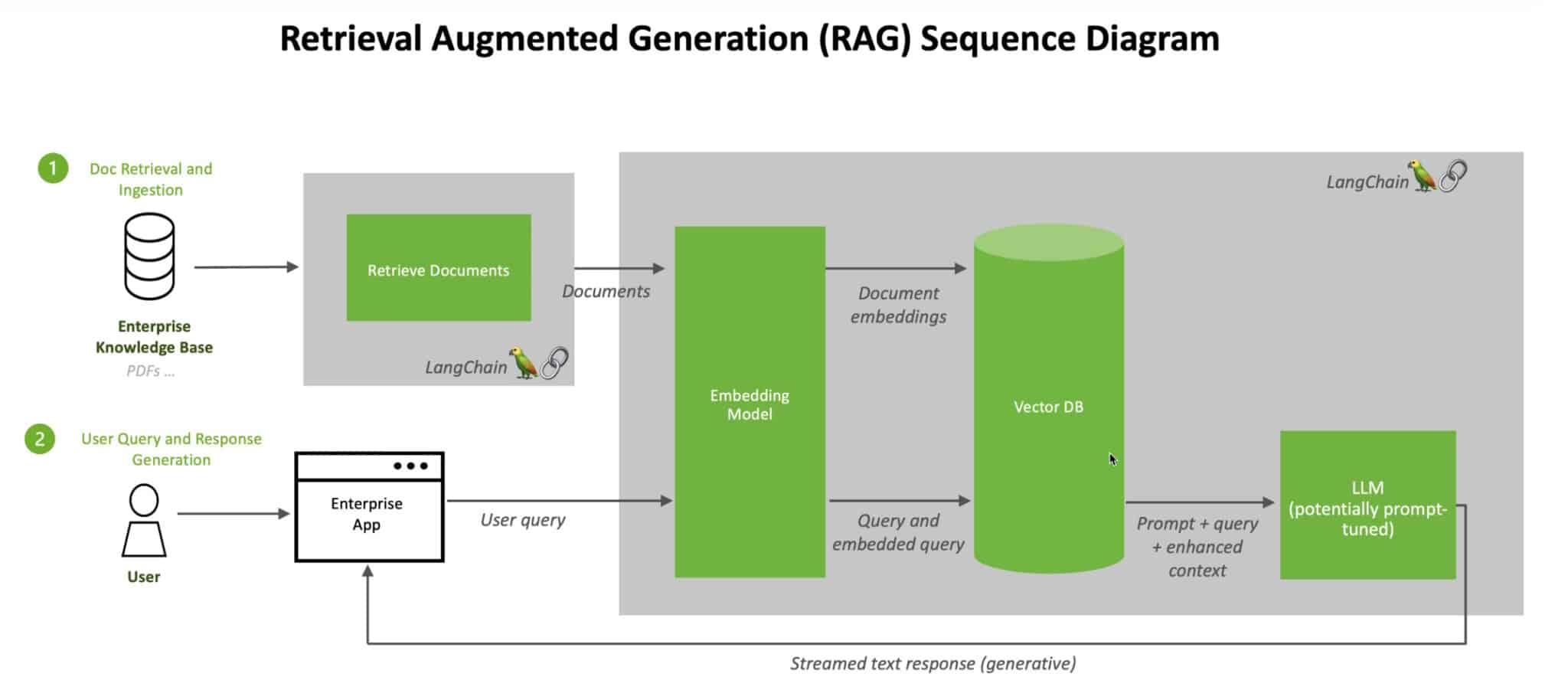
Ref: https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
Retrieval-Augmented Generation (RAG) คือ เทคนิคที่ใช้ในการเพิ่มประสิทธิภาพของ Large Language Model (LLM) ใน Generative AI อย่าง Gemini โดยการเชื่อมต่อ LLM เข้ากับแหล่งข้อมูลภายนอกที่น่าเชื่อถือและมีความเกี่ยวข้องกับหัวข้อที่กำลังสนทนาอยู่
โดยปกติแล้ว LLM จะใช้ข้อมูลที่ได้รับการฝึกฝนมาในการตอบคำถาม ซึ่งข้อมูลเหล่านี้อาจมีอย่างจำกัดหรือล้าสมัยไปแล้ว (รวมถึง อาจจะเชื่อมโยงมามั่วๆด้วย) RAG ช่วยแก้ปัญหานี้โดยการดึงข้อมูลที่เกี่ยวข้องจากแหล่งข้อมูลภายนอก เช่น ฐานข้อมูลภายในองค์กร wikipedia หรือแหล่งข่าวสารจากเว็บไซต์ต่างๆ แล้วนำมาใช้ในการสร้างคำตอบที่แม่นยำและเป็นปัจจุบันมากขึ้น ซึ่งไอเดียอย่าง RAG นี่แหละ ที่จะช่วย “ลดโอกาสที่ LLM จะสร้างข้อมูลที่ผิดพลาดหรือไม่มีมูลความจริง” ออกไปได้ (AI Hallucination)
ใช่ครับ ทุกท่านไม่ได้กำลังอ่านผิด มันคือ “การลดโอกาสที่จะสร้างข้อมูลผิดออกมา” แม้ว่า RAG จะช่วยลดโอกาสที่ LLM จะสร้างข้อมูลที่ผิดพลาดหรือไม่มีมูลความจริง (AI Hallucination) ได้อย่างมีนัยสำคัญ แต่ก็ไม่ได้หมายความว่าจะสามารถกำจัดปัญหานี้ได้ 100% นะ มันก็จะขึ้นอยู่กับ RAG ที่เรานำมาใช้ รวมถึงตัว LLM เองด้วยว่าสามารถเข้าใจบริบทจาก RAG ได้ดีมากน้อยแค่ไหนเช่นกัน (ดังนั้น การเลือก Model ที่จะนำมาใช้กับ RAG เองก็สำคัญเช่นกัน)
แต่ถึงอย่างไร เทคนิค RAG นี้ก็ถือว่าช่วยทำให้อาการ AI Hallucination ลดลงได้เยอะมาก รวมถึง ไม่ต้องเสียเวลา Train model ใหม่ในทุกๆรอบที่มีข้อมูลใหม่เข้ามาเหมือน Machine Learning ทั่วไป ทำให้ RAG เริ่มเป็นที่นิยมในการ “สร้าง AI ฉบับมี reference” ขึ้นมาได้
(** เราจะไม่ข้อเจาะลึกทฤษฎี RAG ในบทความนี้มากนะครับ เพื่อไม่ให้บทความนี้ยาวเกินไป เราจะให้ทุกคนที่ยังไม่รู้จัก RAG ได้ get feeling ของ RAG กันก่อนนะครับว่าประโยชน์ของมันคืออะไร และมีไอเดียในการ development ประมาณไหนบ้างนะครับ)
ทีนี้ เอาจริงๆ การทำ RAG นั้นมีหลากหลาย library และหลากหลาย idea ที่สามารถทำได้ (ให้ keyword ตัวเบิ้มๆคือ “langchain” หากใครสนใจเรื่องนี้แบบจริงจังนะครับ) สำหรับ Solution ที่ทางผมได้นำเสนอใน Session นี้ ผมใช้ประโยชน์จาก 2 products ชื่อดัง ที่เมื่อนำมารวมกัน สามารถได้คุณสมบัติ RAG + LLM ออกมา รวมถึง code ไม่เยอะมากด้วย นั่นคือ
- Vertex AI (https://cloud.google.com/vertex-ai) = Platform Machine Learning บน Google Cloud ที่ครอบคลุมเครื่องมือและบริการต่างๆ ที่ช่วยให้ developer หรือ data science สามารถสร้าง ปรับใช้ และจัดการ model AI ได้อย่างมีประสิทธิภาพ ซึ่งรวมถึง LLM (Large Language Models) ด้วยเช่นกัน (Model ที่ Vertex AI support ไม่ได้มีเฉพาะ Gemini นะ Vertex AI นี่ support เพียบ ไปอ่านจาก document ต้นทางได้)
- LlamaIndex (https://www.llamaindex.ai/) คือ open source framework ที่ออกแบบมาเพื่อช่วยให้นักพัฒนาสามารถเชื่อมต่อ Large Language Models (LLMs) เช่น Gemini เข้ากับแหล่งข้อมูลภายนอกได้ โดยตัว LlamaIndex ช่วยให้ LLM สามารถเข้าถึงและประมวลผลข้อมูลจากแหล่งต่างๆ เช่น เอกสาร PDF website หรือ database เพื่อนำมาใช้ในการสร้างคำตอบที่แม่นยำมากขึ้นได้
ทีนี้ ด้วยความสามารถ ของ Vertex AI (Platform Machine Learning ที่สามารถต่อเข้ากับ LLM อย่าง Gemini ได้) และ LlamaIndex (ตัวประมวลผลข้อมูลที่เชื่อมต่อกับแหล่งข้อมูล Data ได้) ในบทความของ Google Cloud จึงได้นำเสนอ Solution ที่ทำให้เราสามารถสร้าง RAG + LLM ด้วยเครื่องมือ Vertex AI + LlamaIndex ออกมา โดยใช้ไอเดียตามบทความนี้ได้
https://cloud.google.com/vertex-ai/generative-ai/docs/llamaindex-on-vertexai
โดยไอเดียหลักๆของบทความนี้คือ
- Vertex AI ใช้ในการเข้าถึง Gemini Model อย่าง Gemini Pro, Gemini 1.5 Flash รวมถึงใช้ในการจัดเก็บและค้นหา embeddings ของข้อมูล เพื่อนำมาใช้ในการดึงข้อมูลที่เกี่ยวข้องกับคำถามของ user
- ใช้ LlamaIndex ในการเชื่อมต่อกับแหล่งข้อมูลต่างๆ (เป็น Data Connectors) เช่น Google Drive, Google Cloud Storage รวมถึงใช้สำหรับการเป็น Node Parsers (แยกและแปลงข้อมูลจากแหล่งต่างๆ ให้เป็นรูปแบบที่ LLM สามารถเข้าใจได้) และ Retriever (ใช้ในการดึงข้อมูลที่เกี่ยวข้องจาก index) เพื่อส่งต่อไปยัง LLM ให้ LLM สามารถวิเคราะห์ข้อมูลออกมาให้อยู่ภายใน scope ของแหล่งข้อมูลที่เราเชื่อมต่อไว้ได้
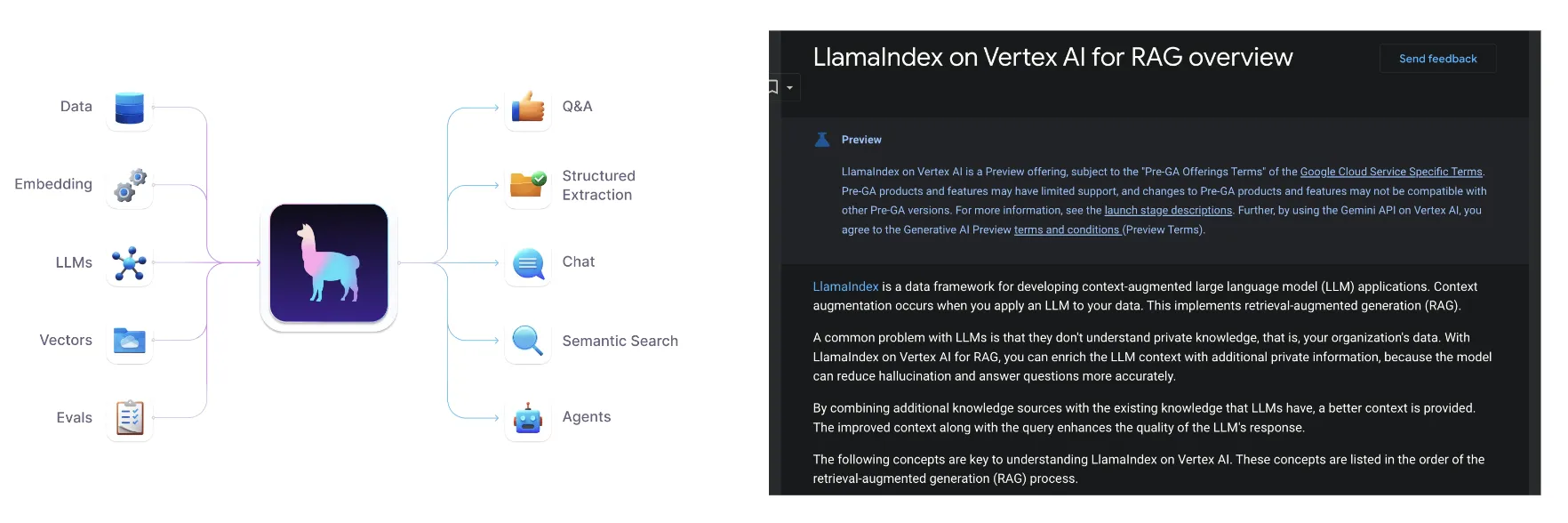
เมื่อนำ code ของ 2 product มารวม concept กัน ก็จะได้ diagram หน้าตาประมาณนี้ออกมา
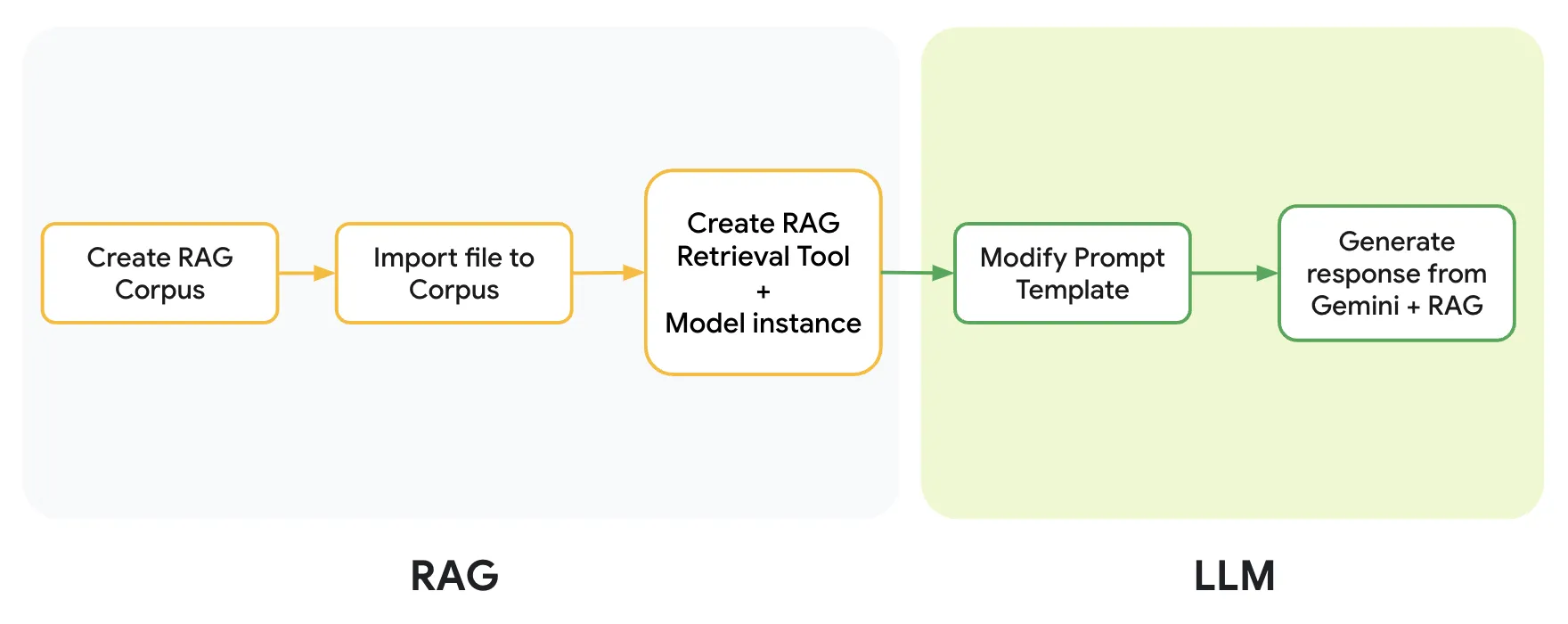
โดย Concept ของ Diagram นี้เราจะแยกออกเป็น 2 ส่วนคือ
- RAG
- ส่วนสำหรับสร้างแหล่งเก็บข้อมูล [ขั้นตอนที่ 1]
- รวบรวมข้อมูล [ขั้นตอนที่ 2]
- และทำการ embedded ข้อมูล ที่จะใช้งานใน LLM + define model LLM ว่าจะใช้ตัวไหน (ซึ่งในทีนี้เราจะใช้เป็น Gemini Pro) [ขั้นตอนที่ 3]

- LLM
- ส่วนสำหรับการ define prompt ออกมา (เหมือนกับที่เราทำใน Gemini API) เพื่อให้ข้อมูลออกมาตามที่เราต้องการได้ [ขั้นตอนที่ 4]
- และเมื่อนำทั้ง ส่วนของ RAG และ LLM มาประกอบกัน ก็จะสามารถเรียกใช้งานผ่าน code นี้ได้เลย [ขั้นตอนที่ 5]

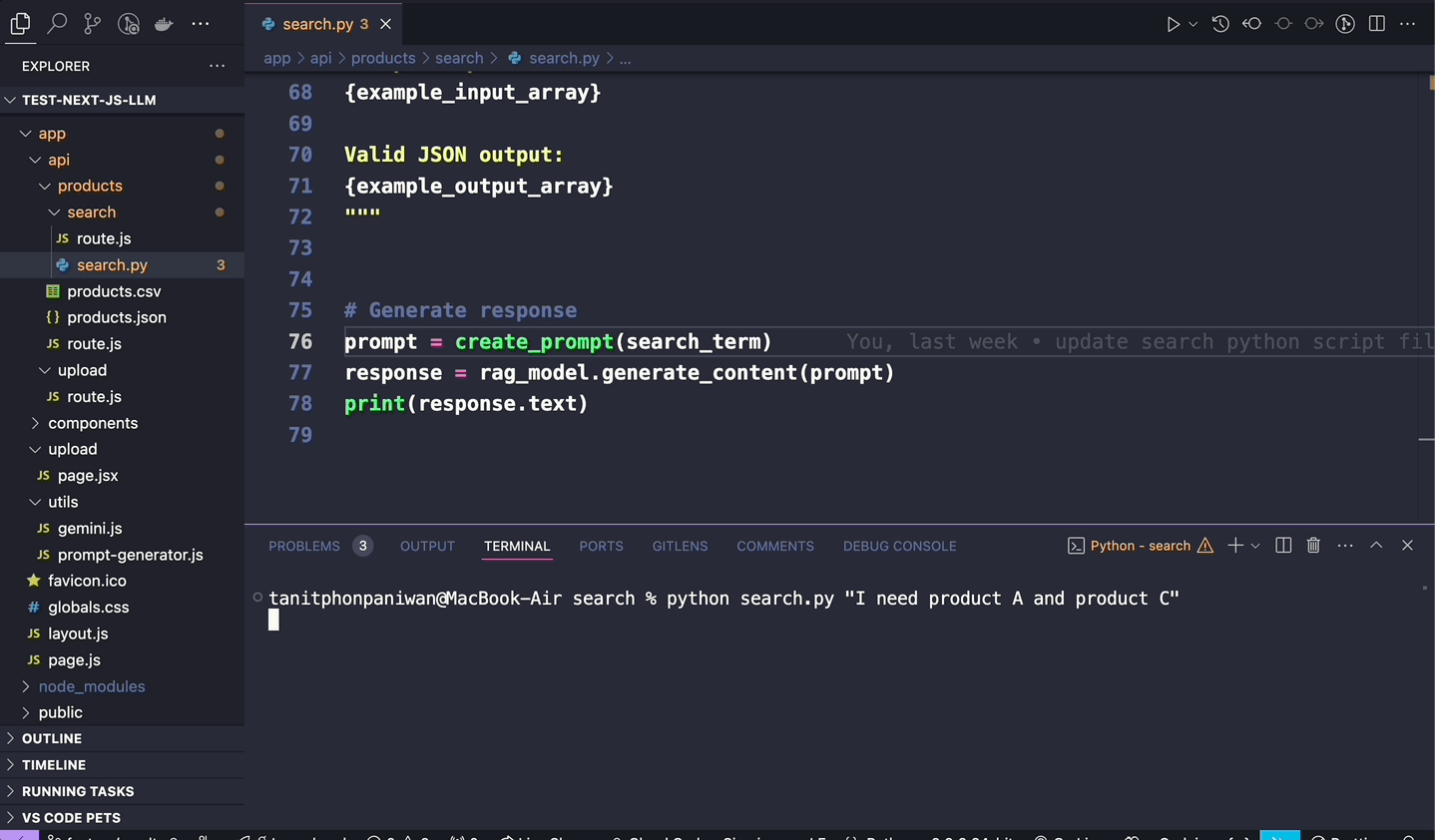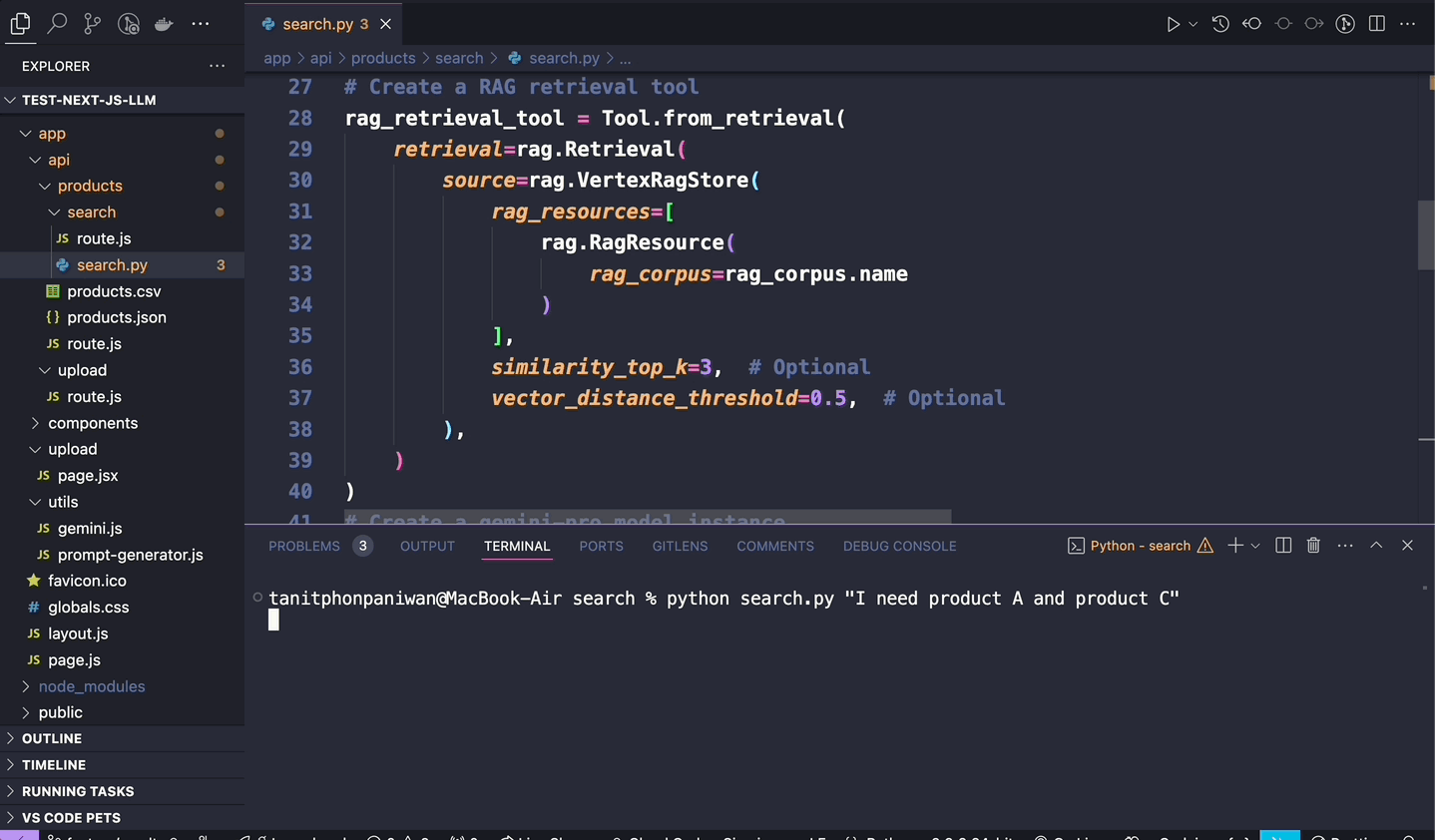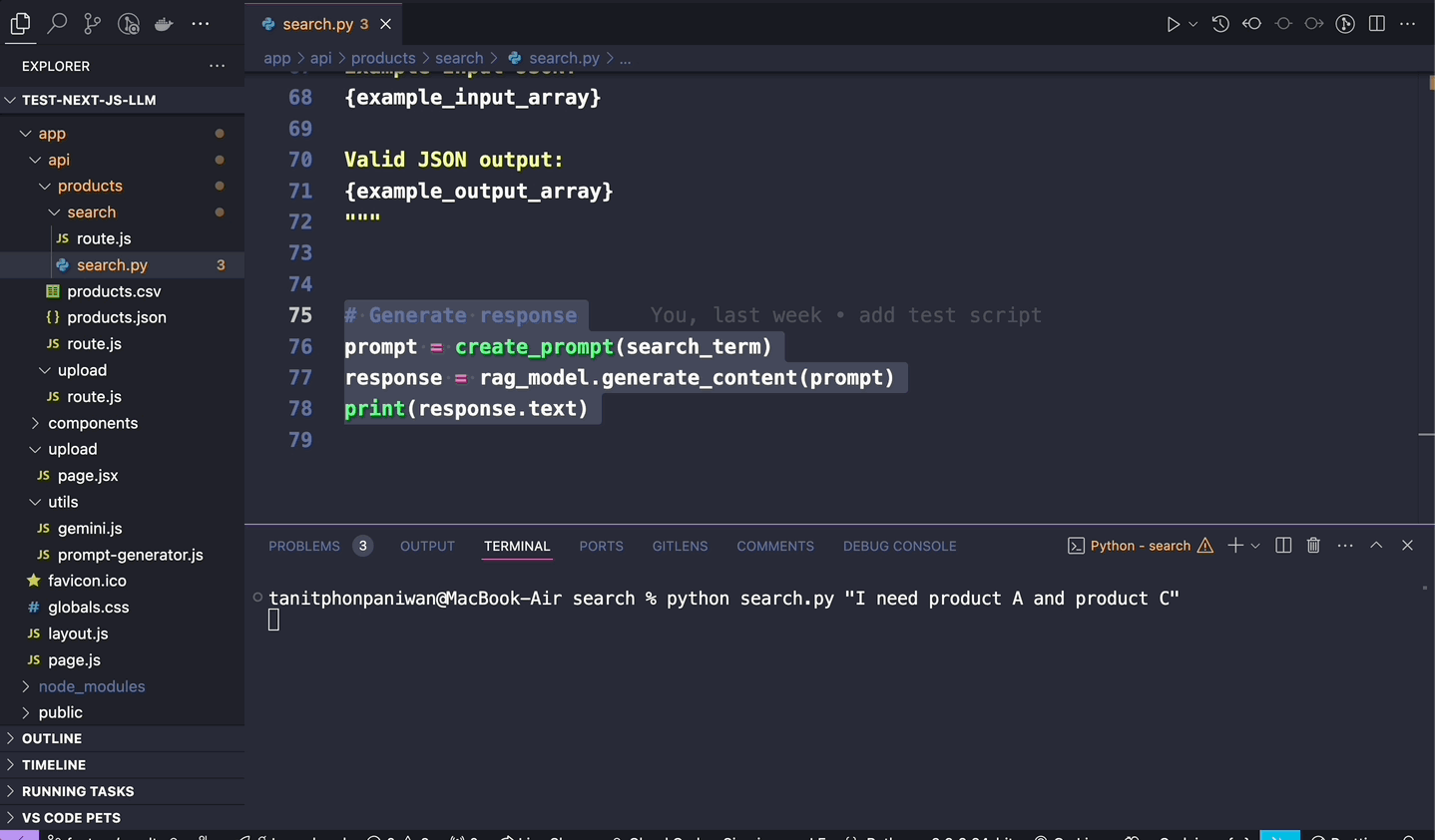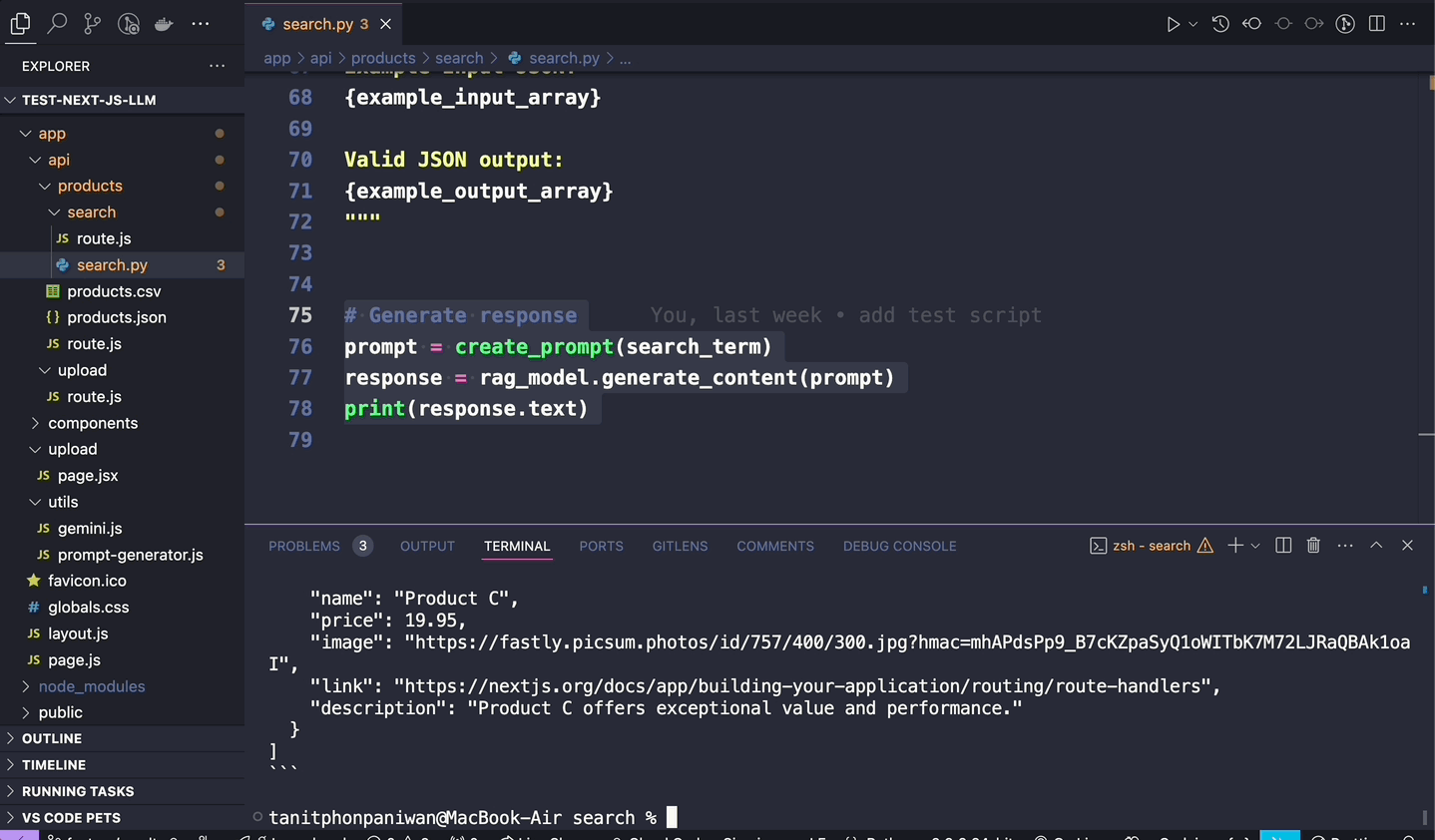
และนี่ก็คือผลลัพธ์การใช้งานผ่าน python เมื่อเราลองส่ง prompt เข้า RAG เข้าไป ก็จะได้ผลลัพธ์เป็น JSON ตาม data json (product.json ที่เราได้ทำการระบุผ่าน url google drive เอาไว้ เพื่อนำมาใช้เป็นแหล่งข้อมูลสำหรับทำ RAG)
ก็จะเห็นว่าคำตอบที่ได้มานั้น (จากคำถาม prompt ว่า “I need product A and product C”) ก็จะเป็นคำตอบที่อยู่ภายใน product.json (ที่เป็น product A และ product C ของ product.json ตัวนั้น) ออกมาได้
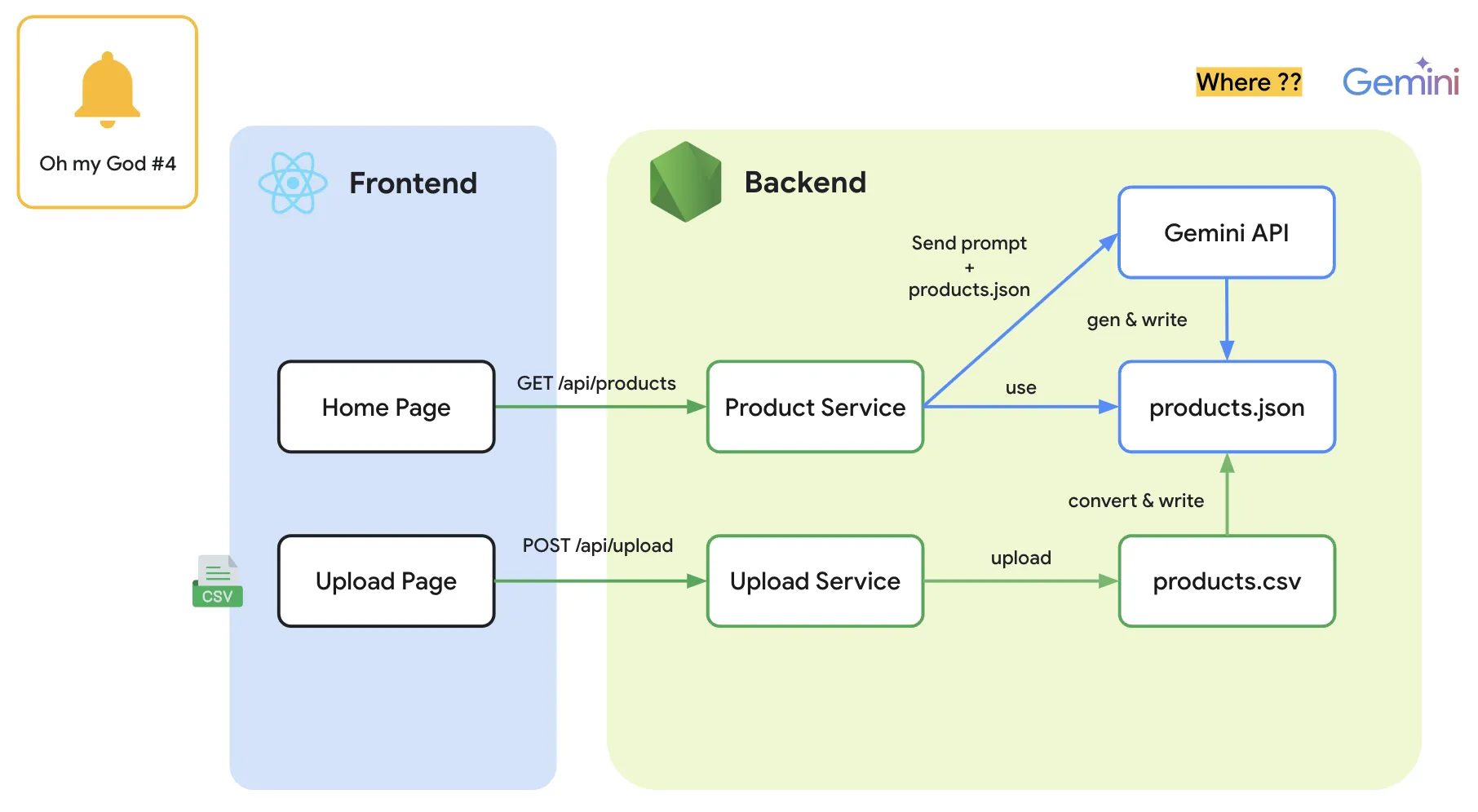
ทีนี้ ใน Session เรามีการแชร์ปัญหานิดหน่อยว่า ok solution จากบทความ Google Cloud มันดันเป็นภาษา python (จริงๆ llamaindex มัน support node.js นะ แต่เรายกตัวอย่าง python เนื่องจากทุกคนจะได้ศึกษาต่อจากบทความของ Google Cloud ได้ + ป้องกันปัญหาเรื่อง compatibility ของ library ด้วย กันพลาดว่ามันอาจจะมีช็อตที่ใช้งานร่วมกันไม่ได้ระหว่าง Vertex AI + llamaIndex)
คำถามคือ แล้วเราจะใช้งาน ภาษา python ใน node.js ได้อย่างไร
และเราก็ค้นพบว่า “Node.js มันสามารถ run process command ได้” ดังนั้น หากมอง python เป็น process ที่ run ผ่าน command หนึ่งได้ เราก็จะสามารถสั่งการใช้งาน python ผ่านการใช้ command “python” ภายใน code node.js ได้แล้ว ดังเช่นตัวอย่าง code ด้านล่างนี้

และท้ายที่สุดเราก็สามารถทำท่านี้ได้ ที่จะทำให้เราสามารถใช้ชีวิตร่วมกับ RAG (ที่เป็น code pyhon) ใน Node.js ได้ โดยยังคงใช้เพียงแค่ server ตัวเดียวในการจัดการได้
(** เพิ่มเติมใน diagram นี้คือ หากจะทำให้เรื่องราวนี้สมบูรณ์ เราอาจจะมีการ upload ตัวข้อมูลไปไว้สักที่หนึ่ง และให้ RAG ไปดึงผ่านข้อมูลที่ update ตัวนั้นแทน)
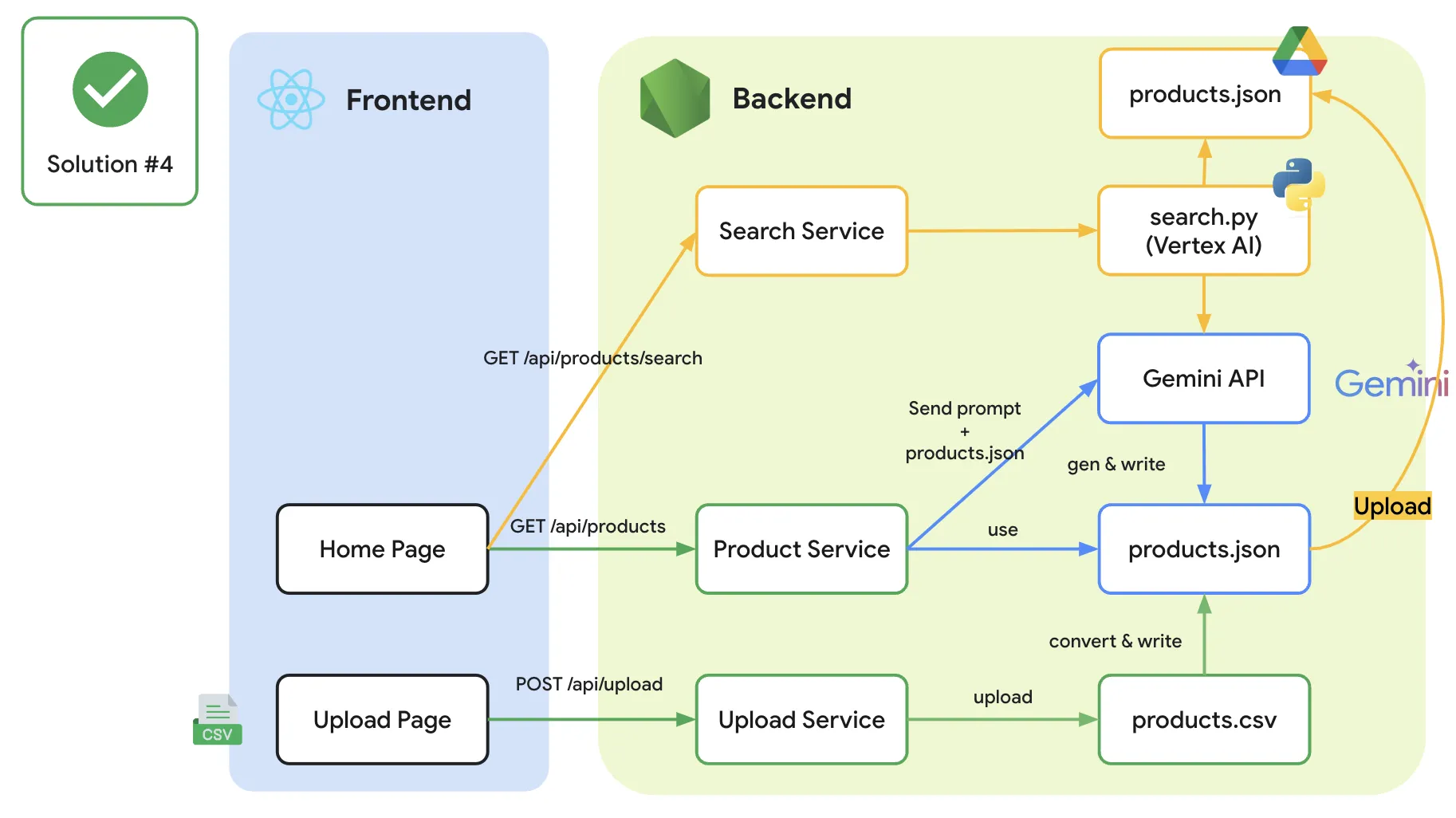
และนี่คือผลลัพธ์จากการใช้งานร่วมกันระหว่าง Node.js + python
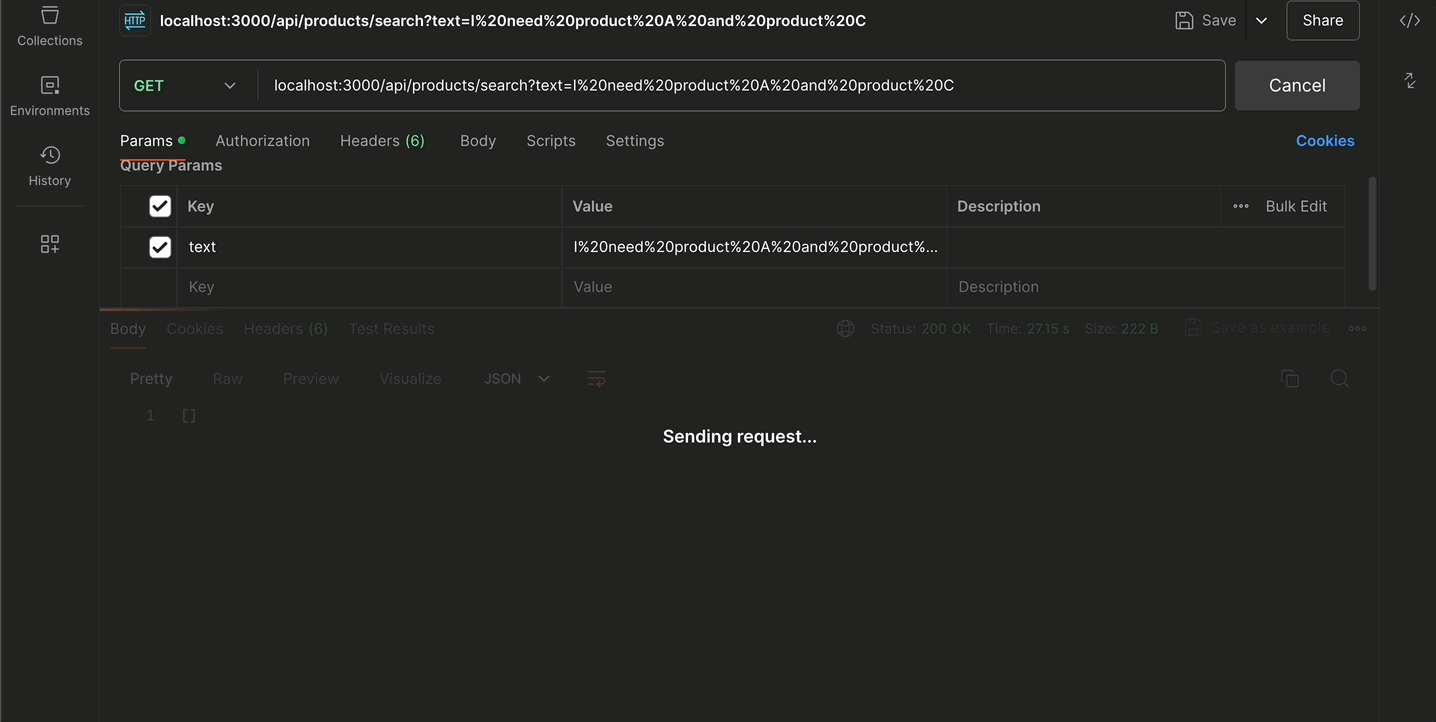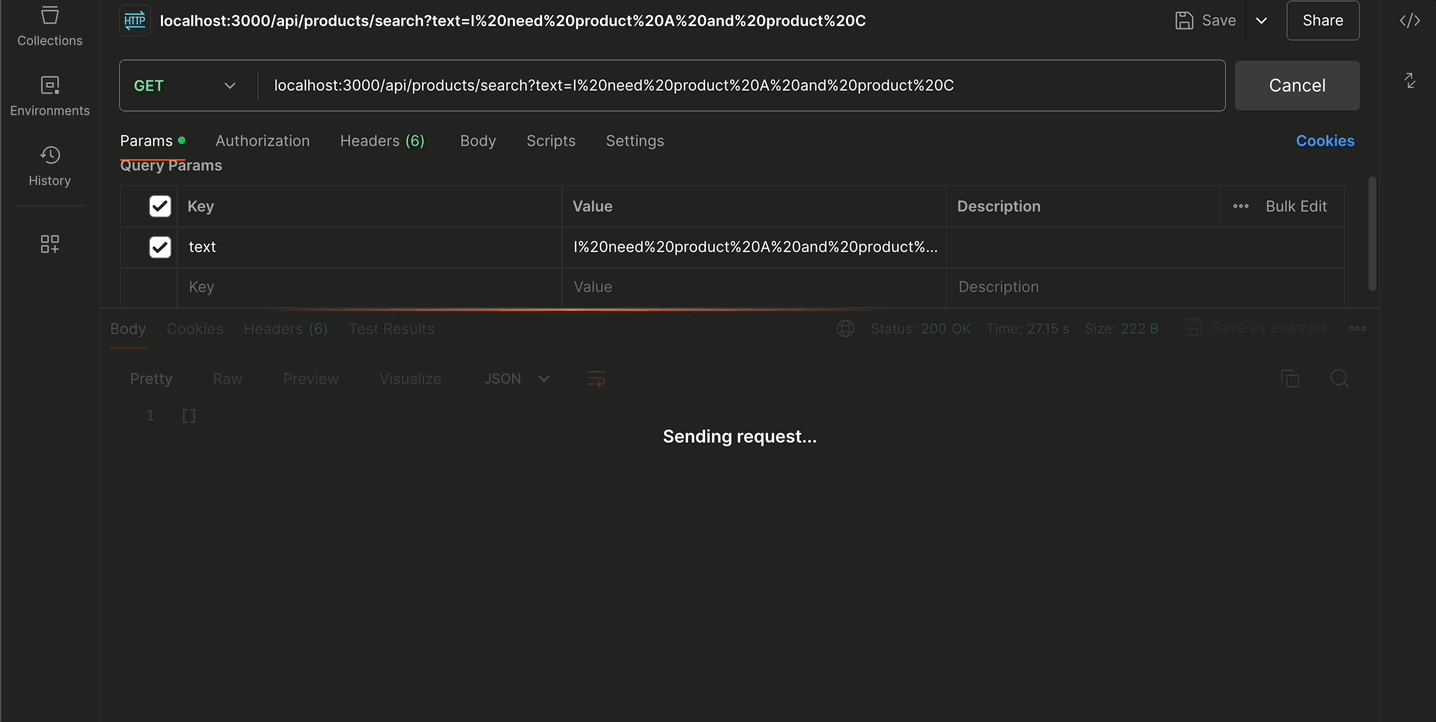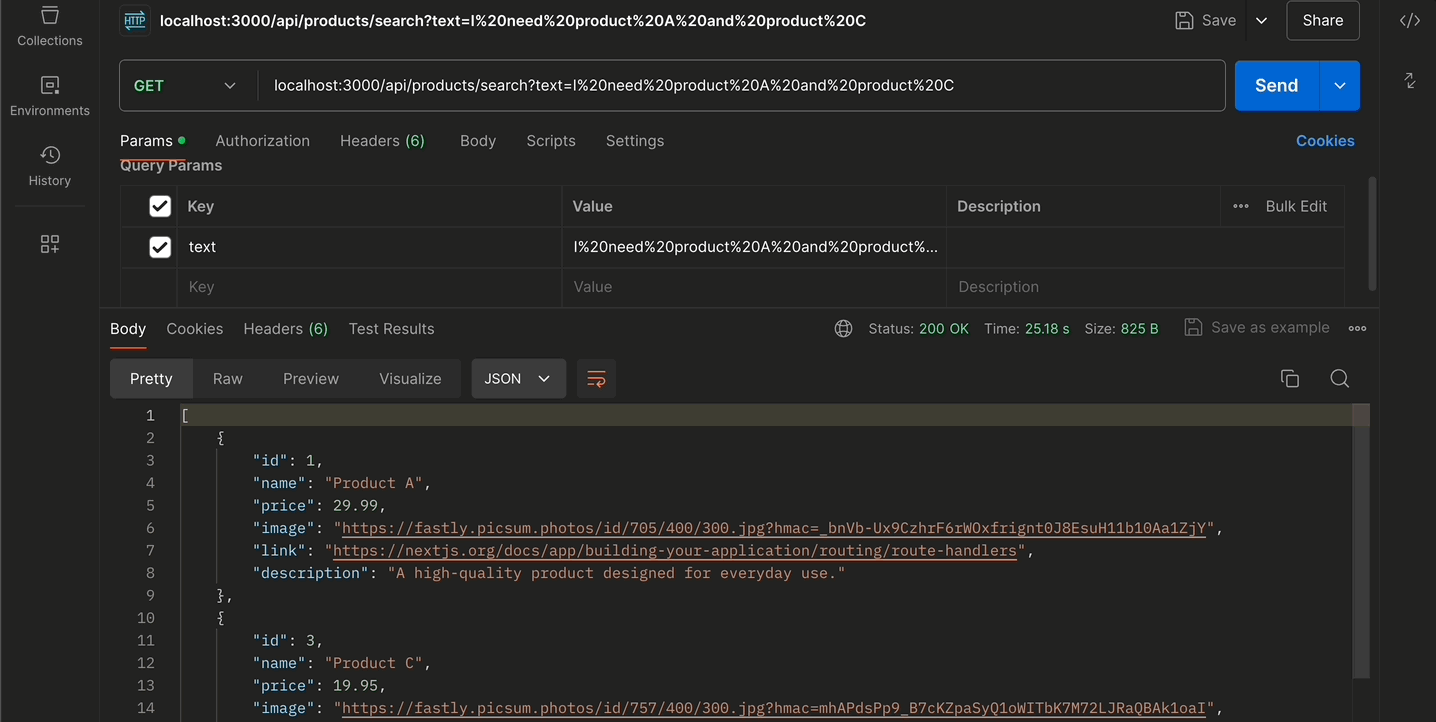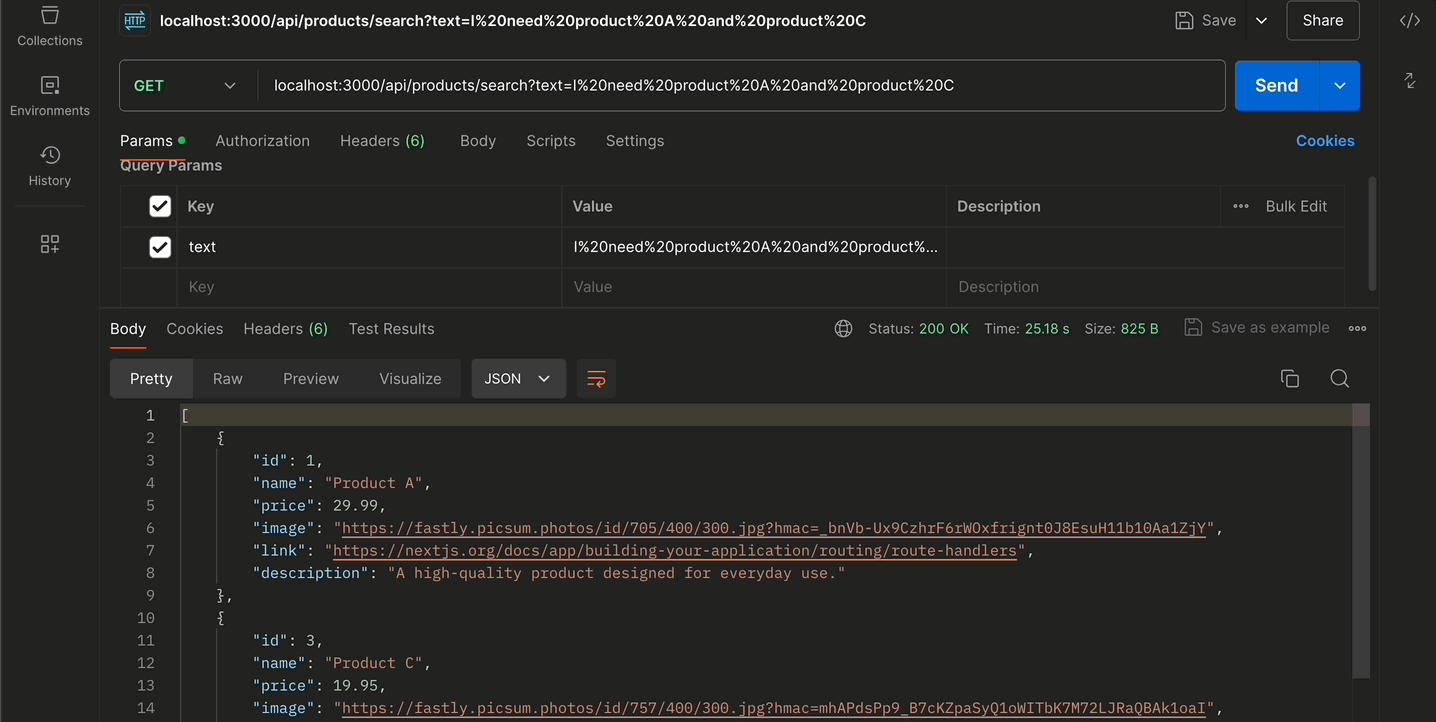
เล่าตามความจริง เรายังไม่เคยมีประสบการณ์ในการ production งาน RAG ของจริง (เราเองก็ยังอยู่ในช่วงศึกษาเช่นกัน) และเราคิดว่า หากต้องการใช้ RAG จริงๆ เราคงไม่นำมันมารวมเป็น service เดียวกันเช่นกัน (เราคงแยก microservice สำหรับทำเรื่องนี้ไป)
ดังนั้น ภาพ diagram ด้านบนนี้ สำหรับเราก็เป็นเพียง “POC ของ idea ของการใช้ RAG” นะครับ ถ้าหากจะใช้จริงอย่างไร ยังไงก็ต้องศึกษากันเพิ่มเติมนะครับ
และนี่ก็คือเรื่องราวของ Gemini API + RAG โดยประมาณ keyword ใหญ่ๆของการใช้สิ่งนี้คือ “Generative AI” + “Data Collection” หากเมื่อไหร่ก็ตามจำเป็นต้องมีการใช้ Generative AI ร่วมกันกับ Data ที่เราต้องการ เมื่อนั้น RAG จะเป็นไอเดียสำคัญที่ทำให้เราสามารถทำ AI Application รวมกับ data ของเราได้นั่นเอง

โดยสรุปทั้งหมด
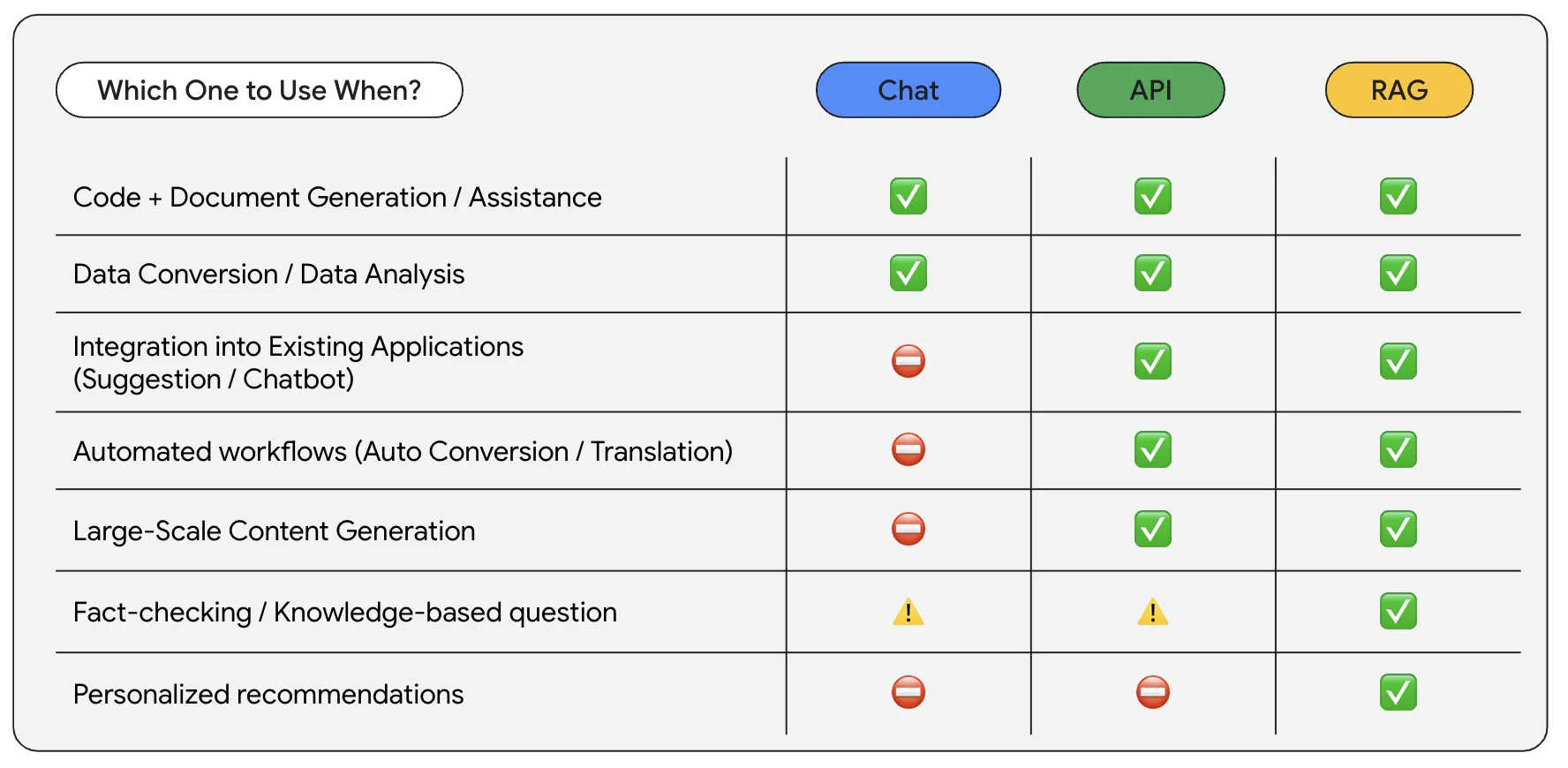
และนี่ก็คือเนื้อหาใน Session โดยประมาณจากหัวข้อ “Beyond Chat: Exploring the Power of Gemini” เมื่อเราลองดูจาก use case โดยประมาณ เราก็อาจจะพอสรุปได้ว่า เราควรพิจารณาเลือกใช้ Gemini Advanced (Chat), Gemini API หรือ Gemini API + RAG ด้วยไอเดียประมาณนี้ได้
- หากต้องการเพียงแค่ การสร้างข้อมูล / สร้าง code หรือการแปลงข้อมูล จากภาพนอก เข้าสู่ภาพในระบบ = Gemini Advanced (Chat) จะตอบโจทย์เรื่องนี้ค่อนข้างมาก (และใช้งานง่ายที่สุด)
- หากต้องการใช้งานร่วมกับ content ใน application (เช่น Translation) / ใช้งานเป็นส่วนหนึ่งกับ workflows ของ application (เช่น ดึงข้อมูลจากภาพหรือ pdf) = Gemini API จะตอบโจทย์เรื่องนี้ค่อนข้างมาก (เอา process manual ออกและเปลี่ยนใหม่เป็นไปเชื่อมต่อกับ Generative API แทน)
- หากต้องการความแม่นยำของข้อมูล และ ต้องการ LLM ที่ทำงานเฉพาะทางกับข้อมูลของเราเอง = Gemini API + RAG จะตอบโจทย์เรื่องนี้ โดยเราสามารถกำหนด Source ของข้อมูลขึ้นมาเองได้ และสามารถให้ LLM พิจารณาจากข้อมูลที่เราใส่ไปได้
ทั้งนี้ สิ่งที่เราอยากจะแชร์ไว้คือ ความยากของ Generative AI อย่าง Gemini นั้น นอกเหนือจากการคิด prompt / เลือกใช้ model llm แล้ว ยังมีเรื่องของ “use case” ที่เราสามารถทำให้ Generative AI มาเป็นส่วนหนึ่งของการทำงานเราได้เช่นกัน หวังว่า บทความ (และ Session นี้) จะช่วยเพิ่มเติมไอเดียสำหรับคนที่กำลังพยายามหาไอเดียใช้งานร่วมกับ Generative AI อยู่นะครับ
ขอบคุณที่อ่านมาจนถึงตอนนี้ หวังว่าจะได้รับความรู้กันไม่มากก็น้อยนะครับ ถือเป็นการไถ่โทษสำหรับ demo อันสุดมหัศจรรย์ในงาน Google I/O ที่ผ่านมานะครับ 😆
My Resource
Github https://github.com/mikelopster/test-llm-3-type
Slide https://docs.google.com/presentation/d/1oumX0Zm8WsvJdwy6CfZO_owIrBdJxX2SnW77_71ptXE/edit?usp=sharing
- ทำไมถึงต้องใช้ Nuxt ทั้งๆที่มี Vue อยู่แล้ว ?มี Video
มาทำความรู้จัก Nuxt กันว่ามันคืออะไร มีความแตกต่างกับ Vue ยังไงบ้าง และเคสแบบไหนควรใช้ Nuxt บ้าง

- แนะนำ Dynamic programming แบบนิ่มนวลที่สุดมี Video
บทความนี้จะแนะนำเบื้องต้นเกี่ยวกับ Dynamic programming เทคนิคหนึ่งที่ใช้สำหรับแก้ปัญหาที่ ปัญหาย่อยที่ทับซ้อนกัน (overlapping subproblem)

- รู้จักกับ Next.js 14 แบบ Quick Overviewมี Video มี Github
พาทัวร์ feature ต่างๆของ Next.js กันแบบรวดเร็วกัน ดูทุก feature ของ Next กัน

- NoSQL, MongoDB และ ODMมี Video
พามารู้จักกับ NoSQL พื้นฐาน database อีกตัวหนึ่ง ว่ามันคืออะไร มันเกิดขึ้นมาจากโจทย์อะไร มีลักษณะที่แตกต่างกับ SQL และมีวิธีการใช้งานที่ต่างกับ SQL ยังไงบ้าง
