

 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
Common Collection
https://doc.rust-lang.org/book/ch08-00-common-collections.html
ใน Rust มี Collection ที่ใช้งานกันอย่างแพร่หลาย ซึ่งเป็นโครงสร้างข้อมูลที่ช่วยให้เราสามารถจัดเก็บและจัดการข้อมูลได้อย่างมีประสิทธิภาพ โดย Collection ใน Rust มักพบใน standard library (std::collections) และมีความปลอดภัยเพราะใช้ระบบ ownership และ borrowing ของ Rust ช่วยลดข้อผิดพลาดได้
ซึ่งเอาจริงๆ Collection ที่มีอยู่ใน Rust มีอยู่พอสมควร แต่เราจะขอหยิบ 3 ตัวที่มีการใช้งานบ่อยๆ เพื่อให้เห็นภาพของการใช้งาน collection กัน
Vectors
Vector หรือ Vec<T> ใน Rust เป็น collection ชนิดหนึ่งที่ใช้สำหรับเก็บลำดับของข้อมูลประเภทเดียวกัน (homogeneous data) โดยมีขนาดที่สามารถเปลี่ยนแปลงได้ (dynamic size) ต่างจาก array ที่มีขนาดคงที่ นอกจากนี้ Vector มี function และคุณสมบัติที่ช่วยให้เราจัดการข้อมูลได้อย่างสะดวก เช่น การเพิ่ม, ลบ, และแก้ไขข้อมูลในลำดับได้
ความสามารถเด่นๆของ Vector คือ
- Dynamic Size: เพิ่มหรือลบข้อมูลได้โดยไม่ต้องกำหนดขนาดล่วงหน้าได้
- Efficient Memory Management: Rust ใช้ระบบ ownership และ borrowing เพื่อจัดการหน่วยความจำของ Vector ที่ยังคงทำให้อยู่ภายในระบบ ownership ได้ แม้ว่าจะมีการ dynamic ที่ส่วนของ Memory ก็ตาม
- Generic Type: รองรับการจัดเก็บข้อมูลทุกประเภท เช่น
Vec<i32>,Vec<String>(เดี๋ยวเราจะอธิบายเรื่อง Generic กันใน topic หลังๆอีกที)
ตัวอย่างการใช้ Vector
ตัวอย่างที่ 1: ใช้ Vec::new() หรือ vec![] เพื่อสร้าง Vector
fn main() { // สร้าง Vector เปล่า let mut numbers: Vec<i32> = Vec::new(); numbers.push(1); numbers.push(2); numbers.push(3); println!("{:?}", numbers); // [1, 2, 3]
// ใช้ vec![] สร้าง Vector let fruits = vec!["Apple", "Banana", "Cherry"]; println!("{:?}", fruits); // ["Apple", "Banana", "Cherry"]}Note
- สังเกตว่า fruits เราไม่ได้มีการประกาศประเภทของ Vector เอาไว้ แต่เมื่อเราเก็บข้อมูลเป็นประเภทเดียวกัน compiler จะสามารถรับรู้ว่าเป็นประเภท
&strและสามารถกำหนดเป็นVec<&str>ออกมาได้
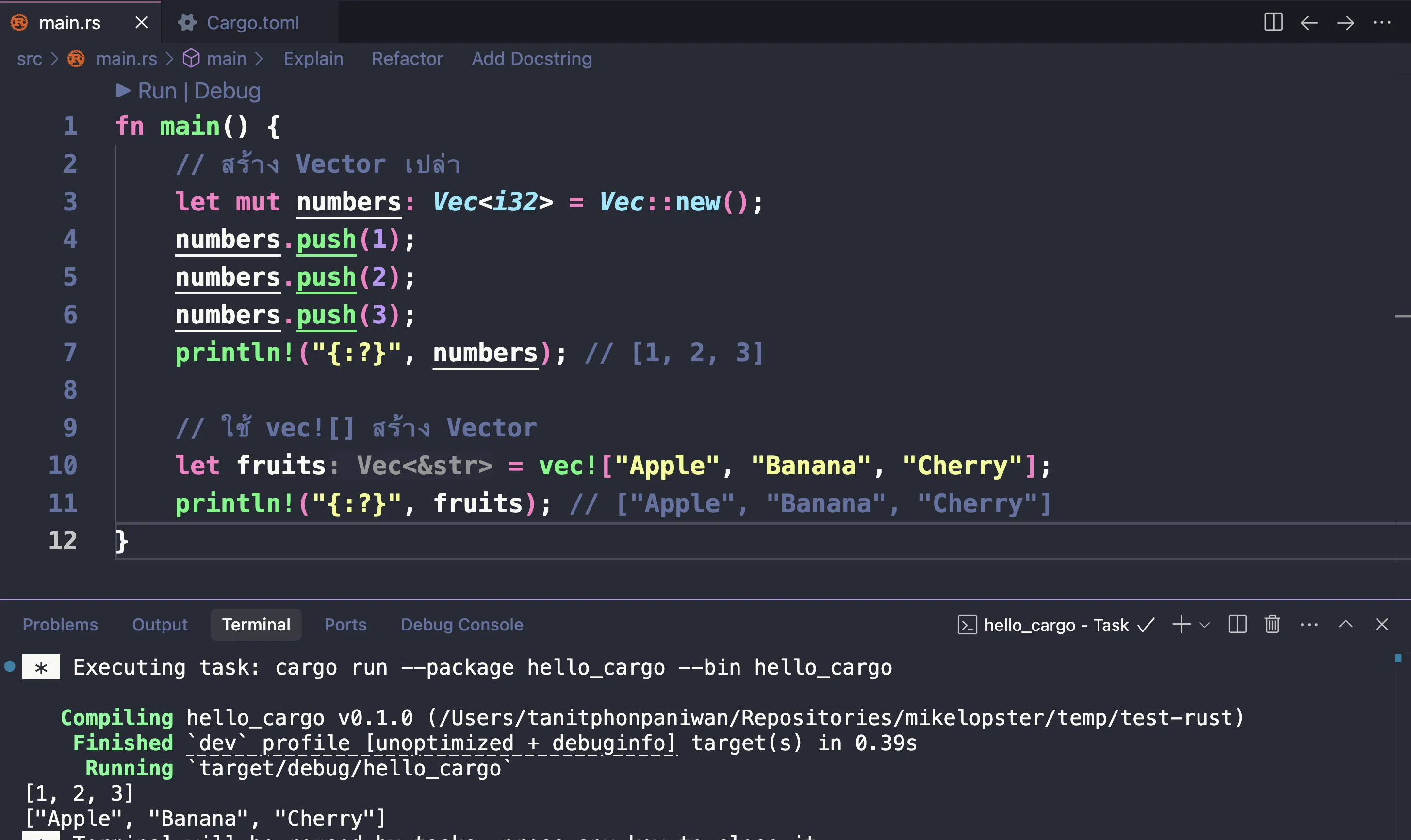
ตัวอย่างที่ 2: การเพิ่ม, การเข้าถึงข้อมูล, การลบข้อมูล, การปรับเปลี่ยนข้อมูล ใน Vector
fn main() { // 1. การสร้าง Vector และเพิ่มข้อมูล let mut numbers = Vec::new(); // สร้าง Vector เปล่า numbers.push(10); // เพิ่มค่า 10 numbers.push(20); // เพิ่มค่า 20 numbers.push(30); // เพิ่มค่า 30 println!("หลังเพิ่มข้อมูล: {:?}", numbers); // [10, 20, 30]
// 2. การเข้าถึงข้อมูล let first = numbers[0]; // เข้าถึงข้อมูลที่ตำแหน่งแรก println!("ข้อมูลตำแหน่งแรก: {}", first);
match numbers.get(5) { Some(value) => println!("ข้อมูลตำแหน่งที่ 5: {}", value), None => println!("ไม่มีข้อมูลในตำแหน่งที่ 5"), // ป้องกันข้อผิดพลาด index เกินขอบเขต }
// 3. การวนลูปข้อมูล println!("วนลูปข้อมูลใน Vector:"); for num in &numbers { println!("{}", num); // ใช้ reference เพื่อไม่ให้ ownership เปลี่ยนแปลง }
// 4. การปรับเปลี่ยนข้อมูล if let Some(last) = numbers.last_mut() { *last += 5; // เพิ่มค่า 5 ให้ข้อมูลตำแหน่งสุดท้าย } println!("หลังปรับเปลี่ยนข้อมูล: {:?}", numbers); // [10, 20, 35]
// 5. การลบข้อมูล numbers.pop(); // ลบข้อมูลตำแหน่งสุดท้าย println!("หลังลบข้อมูลตำแหน่งสุดท้าย: {:?}", numbers); // [10, 20]
numbers.remove(0); // ลบข้อมูลตำแหน่งแรก println!("หลังลบข้อมูลตำแหน่งแรก: {:?}", numbers); // [20]}ผลลัพธ์ที่ได้
หลังเพิ่มข้อมูล: [10, 20, 30]ข้อมูลตำแหน่งแรก: 10ไม่มีข้อมูลในตำแหน่งที่ 5วนลูปข้อมูลใน Vector:102030หลังปรับเปลี่ยนข้อมูล: [10, 20, 35]หลังลบข้อมูลตำแหน่งสุดท้าย: [10, 20]หลังลบข้อมูลตำแหน่งแรก: [20]Note
- การเพิ่มข้อมูล: ใช้
push()เพื่อเพิ่มค่าเข้าไปใน Vector - การเข้าถึงข้อมูล: ใช้
[]หรือget()เพื่อตรวจสอบค่าที่ตำแหน่งต่าง ๆ - การวน loop ข้อมูล: ใช้
forเพื่อวน loop ค่าภายใน Vector - การปรับเปลี่ยนข้อมูล: ใช้
last_mut()เพื่อปรับค่าตำแหน่งสุดท้าย - การลบข้อมูล: ใช้
pop()เพื่อลบค่าตำแหน่งสุดท้าย หรือremove()เพื่อลบค่าที่ตำแหน่งที่ต้องการ
ข้อควรระวังในการใช้ Vector
- Index Out of Bounds: หากเข้าถึงตำแหน่งที่เกินขอบเขตของ Vector จะทำให้โปรแกรม panic ได้
fn main() { let v = vec![1, 2, 3]; println!("{}", v[5]); // panic}- Ownership: หากต้องการให้ Vector ถูกใช้งานหลายที่ ต้องใช้
borrowหรือclone(ตามหลักการของ Ownership)
fn main() { let v = vec![1, 2, 3]; let v_borrowed = &v; // Borrowed reference println!("{:?}", v_borrowed);}Strings
ใน Rust String เป็นหนึ่งในชนิดข้อมูลสำหรับจัดเก็บ ข้อความ ซึ่งสามารถเปลี่ยนแปลงขนาดได้ (dynamic size) ต่างจาก &str ที่เป็น string slice ซึ่งมีขนาดคงที่และอ้างอิงไปยังข้อมูลที่อยู่ในหน่วยความจำ
String: ข้อมูลที่จัดการหน่วยความจำเอง และสามารถเพิ่มหรือลดขนาดได้&str(String Slice): ข้อมูลที่อ้างอิงข้อความ เช่น ตัวอักษรใน literal string ("Hello")
ความสามารถเด่นๆของ String
- Dynamic Size: สามารถเพิ่มหรือลดข้อความได้
- Ownership:
Stringมี ownership ของข้อมูล และจะจัดการหน่วยความจำเอง - UTF-8 Encoding: String ใน Rust เข้ารหัสแบบ UTF-8 ทำให้รองรับอักขระจากหลายภาษา
ตัวอย่างการใช้ String
ตัวอย่างที่ 1: การสร้าง และการเพิ่มข้อความใน String
fn main() { // สร้าง String ใหม่ let mut greeting = String::new(); greeting.push_str("Hello"); // เพิ่มข้อความ println!("{}", greeting); // Hello
// สร้าง String จาก literal string let name = String::from("Rust"); println!("{}", name); // Rust}ผลลัพธ์
HelloRustตัวอย่างที่ 2: เข้าถึงข้อมูล, การเชื่อมข้อความ, และ การลบข้อความ ใน String
fn main() { // 1. การสร้างและเพิ่มข้อความใน String let mut text = String::from("Hello, Rustaceans!");
// 2. การเข้าถึงข้อมูล println!("ข้อความทั้งหมด: {}", text); println!("ข้อความตัวแรก: {}", text.chars().next().unwrap()); // H println!("ข้อความตัวสุดท้าย: {}", text.chars().last().unwrap()); // ! println!("ข้อความบางส่วน: {}", &text[7..17]); // Rustaceans
// 3. การเชื่อมข้อความ let additional_text = String::from(" Welcome to Rust programming."); text.push_str(&additional_text); // เชื่อมข้อความ println!("หลังเชื่อมข้อความ: {}", text);
// 4. การลบข้อความ text.replace_range(7..17, "Rust"); // ลบและแทนที่ "Rustaceans" ด้วย "Rust" println!("หลังลบข้อความบางส่วน: {}", text);
text.pop(); // ลบอักขระสุดท้าย println!("หลังลบอักขระสุดท้าย: {}", text);}ผลลัพธ์ที่ได้
ข้อความทั้งหมด: Hello, Rustaceans!ข้อความตัวแรก: Hข้อความตัวสุดท้าย: !ข้อความบางส่วน: Rustaceansหลังเชื่อมข้อความ: Hello, Rustaceans! Welcome to Rust programming.หลังลบข้อความบางส่วน: Hello, Rust! Welcome to Rust programming.หลังลบอักขระสุดท้าย: Hello, Rust! Welcome to Rust programmingNote
- ใช้
push_str()เพื่อเชื่อมข้อความใหม่ - ใช้
.chars().next()เพื่อเข้าถึงตัวแรก, ใช้.chars().last()เพื่อเข้าถึงตัวสุดท้าย - ใช้ slicing
[start..end]เพื่อดึงข้อความบางส่วน - ใช้
replace_range(start..end, "new_text")เพื่อลบข้อความในช่วงที่กำหนดและแทนที่ด้วยข้อความใหม่ - ใช้
pop()เพื่อลบอักขระสุดท้ายของข้อความ
ตัวอย่างที่ 3: การแปลงชนิดระหว่าง String และ &str
fn main() { let literal_str = "This is &str"; // String slice let string_obj = literal_str.to_string(); // แปลงเป็น String println!("{}", string_obj);
let string_back_to_str = &string_obj; // แปลงกลับเป็น &str println!("{}", string_back_to_str);}Note
- ใช้**
.to_string()** เพื่อแปลง&strให้เป็นStringโดย.to_string()จะสร้าง String object ใหม่ ที่จัดการหน่วยความจำและสามารถเปลี่ยนแปลงขนาดได้ ผลลัพธ์ที่ได้คือข้อความเดียวกันในชนิดString - การใช้เครื่องหมาย
&เพื่อสร้าง String slice (&str) ที่อ้างอิงข้อมูลในStringการแปลงนี้ไม่มีการคัดลอกข้อมูล (copy) เพราะ&strเป็นเพียงการอ้างอิงตำแหน่งในหน่วยความจำของString &strที่สร้างขึ้นจะยังคงใช้ได้ตราบเท่าที่Stringที่มันอ้างอิงยังคงมีอยู่ (เดี๋ยวจะมีอธิบายเพิ่มเติมในหัวข้อ lifetime)
Hash maps
HashMap ใน Rust เป็นโครงสร้างข้อมูลที่ใช้เก็บ key-value pairs โดยสามารถค้นหา, เพิ่ม, และลบข้อมูลโดยใช้ hashing เพื่อจัดการข้อมูลและการค้นหา
โดย HashMap อยู่ใน standard library (std::collections::HashMap) และรองรับ key และค่าที่มีประเภทใด ๆ ที่เป็น Hashable และ Eq เช่น String, i32, หรือชนิดข้อมูลที่กำหนดเองที่ implement ตาม traits เหล่านี้ขึ้นมา (เดี๋ยวจะอธิบายเรื่อง trait อีกที)
ความสามารถเด่นๆของ HashMap
- Key-Value Pairs: เก็บข้อมูลในรูปแบบคู่ (key, value)
- Unique Keys: key ต้องไม่ซ้ำกันใน HashMap
- Dynamic Size: สามารถเพิ่มหรือลบคู่ key-value ได้ตามต้องการ
- Fast Lookup: ใช้เวลาค้นหาใกล้เคียง O(1) ในกรณีทั่วไป
ตัวอย่างการใช้งาน HashMap
ตัวอย่างที่ 1: การสร้าง HashMap และเพิ่มข้อมูล
use std::collections::HashMap;
fn main() { // สร้าง HashMap ใหม่ let mut scores = HashMap::new();
// เพิ่มข้อมูลคู่ key-value scores.insert(String::from("Alice"), 50); scores.insert(String::from("Bob"), 80);
println!("{:?}", scores); // {"Alice": 50, "Bob": 80}}ผลลัพธ์
{"Bob": 80, "Alice": 50}ตัวอย่างที่ 2: การเข้าถึงข้อมูล, การวน loop, และ การอัปเดตและการลบ ใน HashMap
use std::collections::HashMap;
fn main() { // สร้าง HashMap และเพิ่มข้อมูล let mut scores = HashMap::new(); scores.insert("Alice", 50); scores.insert("Bob", 80); scores.insert("Charlie", 70);
// 1. การเข้าถึงข้อมูล if let Some(score) = scores.get("Alice") { println!("คะแนนของ Alice: {}", score); // คะแนนของ Alice: 50 } else { println!("ไม่มีข้อมูลของ Alice"); }
// กรณีคีย์ไม่อยู่ใน HashMap if let Some(score) = scores.get("David") { println!("คะแนนของ David: {}", score); } else { println!("ไม่มีข้อมูลของ David"); // ไม่มีข้อมูลของ David }
// 2. การวนลูป println!("คะแนนทั้งหมด:"); for (name, score) in &scores { println!("{}: {}", name, score); } // Output: // Alice: 50 // Bob: 80 // Charlie: 70
// 3. การอัปเดตข้อมูล scores.insert("Alice", 60); // แทนที่ค่าที่มีอยู่ println!("คะแนนของ Alice หลังอัปเดต: {}", scores.get("Alice").unwrap()); // 60
// ใช้ entry API เพื่ออัปเดตแบบมีเงื่อนไข scores.entry("David").or_insert(90); // เพิ่มเฉพาะเมื่อไม่มีคีย์นี้ println!("คะแนนของ David: {}", scores.get("David").unwrap()); // 90
// 4. การลบข้อมูล scores.remove("Bob"); // ลบคีย์ "Bob" println!("หลังลบ Bob:"); for (name, score) in &scores { println!("{}: {}", name, score); } // Output: // Alice: 60 // Charlie: 70 // David: 90}ผลลัพธ์
คะแนนของ Alice: 50ไม่มีข้อมูลของ Davidคะแนนทั้งหมด:Bob: 80Alice: 50Charlie: 70คะแนนของ Alice หลังอัปเดต: 60คะแนนของ David: 90หลังลบ Bob:Charlie: 70David: 90Alice: 60Note
- ใช้
get(key)เพื่อดึงค่าที่ต้องการจาก HashMap - ใช้
if letเพื่อจัดการกรณีที่ key ไม่มีใน HashMap - ใช้
forเพื่อวน loop HashMap โดยแต่ละรอบจะได้(key, value)เป็นคู่ออกมา - ใช้
insert(key, value)เพื่อเพิ่มหรือแทนค่าของ key ที่มีอยู่ - ใช้
entry(key).or_insert(value)เพื่อเพิ่มค่าถ้า key ยังไม่มีอยู่ - ใช้
remove(key)เพื่อลบคู่ key และ value ที่ต้องการออกจาก HashMap
และนี่ก็คือ collection พื้นฐานที่มักจะมีการใช้งาน Rust สามารถดู collection อื่นๆเพิ่มเติมใน Rust Book หรือ document อื่นๆของ Rust เพิ่มเติมได้ (หรือสามารถศึกษาตาม use case ที่มีการใช้งานเพิ่มเติมก็ได้เช่นเดียวกัน)
Generics
https://doc.rust-lang.org/book/ch10-00-generics.html
Generics ใน Rust คือกลไกที่ช่วยให้เราสามารถเขียน code ที่รองรับหลายชนิดข้อมูล (data types) โดยที่”ไม่ต้องเขียน code ซ้ำซ้อน” กันได้ Generics ทำให้ function, โครงสร้างข้อมูล (struct), และ enum สามารถทำงานได้กับชนิดข้อมูลที่หลากหลาย โดยที่ยังคงความปลอดภัยและประสิทธิภาพสูงสุดเอาไว้ได้
โดยหลักการของ Generic ใน Rust คือ
- Parametric Polymorphism: Generics ช่วยให้โ code สามารถทำงานกับชนิดข้อมูลต่าง ๆ ได้โดยไม่ระบุชนิดข้อมูลล่วงหน้าได้
- Rust จะ monomorphize code (แปลงเป็นชนิดข้อมูลเป้าหมาย) ในขั้นตอน compile ทำให้ประสิทธิภาพไม่ลดลง และยังได้คุณสมบัตินี้จาก Compile Time เหมือนเดิม หรือ เล่าอีกอย่างคือ Generic แม้จะไม่ได้มีการระบุประเภทของประกาศออกมา แต่เมื่อตอน Compile state compile จะทำการสร้าง type ตามที่มีการใช้งานใน Generic ขึ้นมา เพื่อให้ไม่ต้องไปคำนวนใหม่ในตอนจังหวะ runtime นั่นเอง
โดยเป้าหมายของการใช้ Generic คือ
- Code Reusability: Generics ช่วยให้เราเขียน code ที่นำกลับมาใช้ซ้ำได้โดยไม่ต้องระบุชนิดข้อมูลหลายครั้งได้
- Type Safety: Rust จะตรวจสอบชนิดข้อมูลในจังหวะ compile ทำให้สามารถหลีกเลี่ยงข้อผิดพลาดได้เช่นเดิม
- Performance: Generics ใน Rust ถูก monomorphized ในขั้นตอนคอมไพล์ ซึ่งหมายความว่าไม่มี overhead ใน runtime เกิดขึ้น
ตัวอย่างการใช้งาน Generic
fn print_two_values<T>(value1: T, value2: T) { println!("ค่าแรก: {:?}", value1); println!("ค่าที่สอง: {:?}", value2);}
fn main() { print_two_values(42, 99); // ใช้กับ i32 print_two_values("Hello", "Rust"); // ใช้กับ &str print_two_values(3.14, 2.71); // ใช้กับ f64}ผลลัพธ์
ค่าแรก: 42ค่าที่สอง: 99ค่าแรก: "Hello"ค่าที่สอง: "Rust"ค่าแรก: 3.14ค่าที่สอง: 2.71Note
Tเป็น Generic Type Parameter ที่สามารถเป็นชนิดข้อมูลใดก็ได้- function
print_two_valuesรองรับชนิดข้อมูลที่หลากหลายโดยไม่ต้องระบุชนิดล่วงหน้า
ตามที่เห็นใน code จะเห็นว่า Generic นั้นส่งผลทำให้เรามีความสามารถในการรับข้อมูลแบบยืดหยุ่นเอาไว้ได้ และทำให้สามารถ support ข้อมูลหลากหลายประเภทใน function เอาไว้ได้ ส่งผลทำให้เราจัดการข้อมูลกับหลายประเภทไปพร้อมๆกันได้โดยที่ไม่จำเป็นต้องสร้าง code แยกเพื่อทำการ handle ในแต่ละประเภทมา (เนื่องจาก Rust เป็นภาษาที่ต้องมีการระบุ type เสมอ เพื่อคงคุณสมบัติของ type safety เอาไว้)
เพื่อให้เห็นภาพมากขึ้น โดยปกติ Generic มักใช้ร่วมกับ Struct เพื่อให้สามารถ handle ข้อมูลหลายๆประเภทไว้ในโครงสร้างเดียวกันได้ ตัวอย่างต่อไป เราจะลองมาดูการใช้งานร่วมกับ Struct กัน
การใช้ Struct, Enum กับ Generic
การใช้ Struct กับ Generic ใน Rust คือการทำให้ Struct รองรับการจัดเก็บข้อมูลหลายชนิด (data types) โดยไม่ต้องระบุชนิดข้อมูลล่วงหน้าเมื่อกำหนด Struct ช่วยให้โครงสร้างข้อมูลสามารถยืดหยุ่นและนำไปใช้งานซ้ำได้กับหลายชนิดข้อมูลได้
โดย concept ของการใช้ Generic ใน Struct คือ
- ใช้ Generic Type Parameter (
<T>) กับ Struct โดยTเป็นตัวแทนสำหรับชนิดข้อมูลที่จะถูกกำหนดในตอนใช้งานจริง - Struct ที่มี Generic สามารถเก็บข้อมูลชนิดใด ๆ ที่กำหนดให้ในตอนสร้างได้
เช่น ตัวอย่างนี้ เราจะประกาศ Struct Point<T> รองรับข้อมูลทั้ง i32 และ f64 โดยไม่ต้องสร้าง Struct แยกออกมา ก็จะส่งผลทำให้ สามารถรองรับข้อมูลทั้ง 2 ประเภทได้
struct Point<T> { x: T, y: T,}
fn main() { // ใช้ Struct กับชนิดข้อมูล i32 let point_int = Point { x: 10, y: 20 };
// ใช้ Struct กับชนิดข้อมูล f64 let point_float = Point { x: 1.5, y: 3.8 };
println!("Point (i32): ({}, {})", point_int.x, point_int.y); println!("Point (f64): ({}, {})", point_float.x, point_float.y);}ผลลัพธ์
Point (i32): (10, 20)Point (f64): (1.5, 3.8)รวมถึงสามารถใช้กับ Enum ได้ด้วยเช่นกัน
enum Option<T> { Some(T), None,}
fn main() { let some_number: Option<i32> = Option::Some(42); let no_value: Option<i32> = Option::None;
match some_number { Option::Some(value) => println!("Value: {}", value), Option::None => println!("No value"), }}ผลลัพธ์
Value: 42สังเกตว่า ตอน handle error ในหัวข้อก่อนหน้านี้เองก็จะเป็นการประกาศ Enum Option ลักษณะนี้เหมือนกัน เพื่อใช้สำหรับการ handle error ในประเภทต่างๆเอาไว้ได้ โดยใช้รูปแบบข้อมูลที่มีโครงสร้าง Generic เช่น Result และ Option เพื่อจัดการข้อผิดพลาดได้
Trait
อยู่ภายในหมวด Generic เช่นกัน https://doc.rust-lang.org/book/ch10-00-generics.html
Trait เป็นเหมือน interface ในภาษาโปรแกรมอื่น ๆ ซึ่งกำหนดชุดของ function ที่ประเภทต่าง ๆ สามารถนำมาใช้ได้ โดยการกำหนด Trait ทำให้เราสามารถสร้างพฤติกรรมร่วมกันระหว่างประเภทต่าง ๆ ได้
ลักษณะเด่นๆของ Trait
- การกำหนดพฤติกรรม: Trait เป็นการอธิบายว่าอะไรที่ประเภทควรจะสามารถทำได้ เช่น การคำนวณ การเปรียบเทียบ หรือการพิมพ์ข้อความ
- การใช้งานร่วมกับ Generic: Trait มักใช้ใน Generic Bound เพื่อบังคับว่าประเภทที่ใช้ต้องมีพฤติกรรมตามที่กำหนดใน Trait จึงจะสามารถใช้งานได้
- การใช้งาน (Implementation): ประเภทที่ต้องการพฤติกรรมของ Trait จะต้อง implement function ใน Trait เหล่านั้น
เช่น ตัวอย่าง code นี้ เป็นส่วน code สำหรับสร้าง trait
trait Greet { fn say_hello(&self);}จาก code นี้ จะทำการกำหนด
trait Greetกำหนดพฤติกรรมsay_helloที่ประเภทใด ๆ ที่ implement ต้องมี&selfคือการรับค่าตัวเอง (เหมือนthisในภาษาอื่น)
เมื่อนำ function นั้นมา implement trait
// trait จาก code ด้านบนtrait Greet { fn say_hello(&self);}
struct Person { name: String,}
impl Greet for Person { fn say_hello(&self) { println!("Hello, my name is {}", self.name); }}Note
impl Greet for Personบอกว่าPersonจะ implement TraitGreetsay_helloถูกกำหนดให้ทำงานตามที่ Trait ระบุไว้
เมื่อจังหวะมีการเรียกใช้งาน
fn main() { let person = Person { name: String::from("Alice"), };
person.say_hello();}ผลลัพธ์
Hello, my name is Aliceสังเกตว่า เราก็จะสามารถใช้ function ที่มีการกำหนดไว้ใน trait ที่ทำการ implement คู่กับ Struct เอาไว้ได้
สำหรับผู้ที่คุ้นเคยกับ OOP (Object-Oriented Programming) สามารถเปรียบ Trait ใน Rust ได้ว่าเป็นการรวมคุณสมบัติของ Interface และ Abstract Class จากภาษาอื่น ๆ เช่น Java หรือ C# ได้ โดย Trait จะทำหน้าที่กำหนดชุดพฤติกรรม (methods) ที่ประเภทใด ๆ (struct หรือ enum) ต้องนำไปใช้ โดย “ไม่มีการเก็บสถานะ (state) เหมือนกับ Interface ใน OOP” แต่ก็สามารถกำหนด Default Implementation ให้กับ methods ได้ เช่นเดียวกับ Abstract Class ซึ่งช่วยลดการเขียน code ซ้ำในกรณีที่พฤติกรรมมีลักษณะเดียวกันได้
Trait กับ Generic
การใช้งาน Trait กับ Generic ใน Rust ช่วยให้ code ยืดหยุ่นและสามารถรองรับประเภทข้อมูลต่าง ๆ ได้โดยบังคับว่าประเภทที่นำมาใช้ต้องมีพฤติกรรมตามที่กำหนดใน Trait นั้น ๆได้ โดยคุณสมบัตินี้สามารถทำได้ผ่านสิ่งที่เรียกว่า Trait Bound
Trait Bound ใช้กำหนดว่า Generic Type ต้อง implement Trait ใด Trait หนึ่ง เพื่อให้ function หรือ struct สามารถเรียกใช้งาน method ที่กำหนดใน Trait ได้
เช่น ดัง code ตัวอย่างนี้
trait Summable { fn sum(&self) -> i32;}
struct Numbers(Vec<i32>);
impl Summable for Numbers { fn sum(&self) -> i32 { self.0.iter().sum() }}
fn print_sum<T: Summable>(item: T) { println!("The sum is: {}", item.sum());}
fn main() { let nums = Numbers(vec![1, 2, 3, 4, 5]); print_sum(nums);}Note
T: Summableกำหนดว่าTต้อง implement TraitSummable- function
print_sumสามารถเรียกใช้ methodsumได้เพราะ Trait Bound รับประกันว่าTมี method นี้
Trait Bound ใน Generic ใช้เพื่อป้องกันข้อผิดพลาดที่อาจเกิดจากการใช้ Generic Type ที่ไม่มีพฤติกรรมหรือ function ตามที่ต้องการ โดย Trait Bound บังคับให้ประเภทที่ถูกใช้ใน Generic ต้อง implement Trait ที่ระบุไว้ เช่น
- ถ้าเป็นตัวเลข ก็ต้องมีคุณสมบัติบวกลบคูณหารเลขเหมือนกัน
- หากจะเปรียบเทียบกันด้วย
<,>ได้ ก็ต้องมีคุณสมบัติPartialOrdที่ใช้สำหรับเปรียบเทียบเหมือนกัน
(เดี๋ยวเราอธิบายเพิ่มเติมในหัวข้อ Standard library ของ trait อีกที)
รวมถึง สามารถกำหนดให้ Generic ต้อง implement หลาย Traits ได้โดยใช้ + ได้เช่นกัน
trait Greet { fn say_hello(&self);}
trait Farewell { fn say_goodbye(&self);}
fn conversation<T: Greet + Farewell>(item: T) { item.say_hello(); item.say_goodbye();}
struct Person;
impl Greet for Person { fn say_hello(&self) { println!("Hello!"); }}
impl Farewell for Person { fn say_goodbye(&self) { println!("Goodbye!"); }}
fn main() { let person = Person; conversation(person);}Note
T: Greet + Farewellกำหนดว่าTต้อง implement ทั้งGreetและFarewell
Default & Overload
Trait สามารถกำหนด Default Implementation ให้กับ method ได้ ซึ่ง Generic Type ที่ implement Trait นั้นสามารถใช้ได้ทันที
trait Greet { fn say_hello(&self) { println!("Hello!"); }}
struct Robot;
impl Greet for Robot {}
fn main() { let robot = Robot; robot.say_hello(); // ใช้ default implementation}รวมถึงการ override เช่นเดียวกัน หากต้องการ override การทำงานของ say_hello ใน Trait Greet สำหรับ Robot เพื่อให้มีพฤติกรรมเฉพาะ เราสามารถ implement method say_hello ใหม่ในโครงสร้าง Robot ได้ เช่น code ตามด้านล่างนี้
trait Greet { fn say_hello(&self) { println!("Hello!"); }}
struct Robot;
impl Greet for Robot { fn say_hello(&self) { println!("Greetings, human! I am a robot."); }}
fn main() { let robot = Robot; robot.say_hello(); // ใช้การ override}Note
say_helloในRobotถูก override ด้วยข้อความเฉพาะของRobotแทนที่ Default Implementation ที่มีการใส่ไว้ใน trait ตอนแรกสุด
Associated Types
Associated Types ใน Rust เป็นคุณสมบัติของ Trait ที่ช่วยให้คุณสามารถกำหนดประเภท (type) ที่เกี่ยวข้องกับ Trait ได้ ช่วยลดความซับซ้อนในการใช้งาน Generic โดยไม่ต้องระบุประเภทอย่างชัดเจนทุกครั้งที่ใช้งาน Trait
คำถามคือ “ทำไมต้องใช้ Associated Types”
- ช่วยลดความยุ่งยากในการระบุ Generic Type หลายตัว
- ทำให้ code อ่านง่ายขึ้น โดยการกำหนดประเภทที่เกี่ยวข้องกับ Trait ภายใน Trait เอง
- ใช้ในสถานการณ์ที่ Trait ต้องการอธิบายประเภทเฉพาะที่ implement ต้องใช้
โดยวิธีการใช้งานคือ ใช้คำสั่ง type ภายใน Trait เพื่อกำหนด Associated Type ขึ้นมา เช่น code นี้
trait Iterator { type Item;
fn next(&mut self) -> Option<Self::Item>;}type Itemคือ Associated Type ที่กำหนดว่าแต่ละประเภทที่ implement Trait นี้ต้องระบุว่าประเภทของItemคืออะไรSelf::Itemใช้เพื่ออ้างถึง Associated Type ที่ถูกกำหนดโดย implement นั้น ๆ
ทีนี้ในจังหวะ implement เมื่อประเภทใด ๆ implement Trait ที่มี Associated Type “ต้องกำหนดประเภทของ Associated Type ใน type ด้วย”
struct Counter { count: u32,}
impl Iterator for Counter { type Item = u32; // กำหนด Associated Type
fn next(&mut self) -> Option<Self::Item> { if self.count < 5 { self.count += 1; Some(self.count) } else { None } }}
fn main() { let mut counter = Counter { count: 0 };
while let Some(value) = counter.next() { println!("{}", value); }}ผลลัพธ์
12345Note
Counterimplement TraitIteratorโดยกำหนดtype Item = u32ซึ่งหมายถึงค่าที่nextคืนกลับมาจะเป็นu32- Method
nextใช้ Associated TypeSelf::Itemแทนu32โดยตรง ทำให้ code ยืดหยุ่น
ซึ่งถ้าเราลองสังเกตดูดีๆ “อันนี้มันทรงเดียวกับ Generic เลยนี่นา” (กำหนด type ก่อนจะเริ่มใช้งาน) เช่น code ชุดด้านบนนี้ หากเขียนเป็น Generic ก็จะได้ code ประมาณนี้ออกมา
trait Iterator<T> { fn next(&mut self) -> Option<T>;}
struct Counter { count: u32,}
impl Iterator<u32> for Counter { fn next(&mut self) -> Option<u32> { if self.count < 5 { self.count += 1; Some(self.count) } else { None } }}
fn main() { let mut counter = Counter { count: 0 };
while let Some(value) = counter.next() { println!("{}", value); }}คำถามคือ “แล้ว 2 อย่างนี้แตกต่างกันอย่างไร ?” หากเราลองเปรียบเทียบคุณสมบัติของแต่ละฝั่งดู
- Generic
- ต้องระบุประเภท (
T,U, ฯลฯ) ในขณะที่ใช้ Trait - ทุกครั้งที่ใช้ Trait หรือ implement Trait ต้องกำหนดประเภท Generic ให้ชัดเจน
- ยืดหยุ่นกว่า เพราะสามารถกำหนดประเภทได้หลากหลายเมื่อใช้งาน Trait ในที่ต่าง ๆ ได้
- เหมาะสำหรับสถานการณ์ที่ต้องการความยืดหยุ่นสูงหรือสามารถเปลี่ยนประเภทได้ในแต่ละครั้งที่ใช้
- ต้องระบุประเภท (
- Associated Types
- กำหนดประเภทที่เกี่ยวข้องภายใน Trait โดยตรง
- ประเภทนี้ถูก “ผูกติด” กับ Trait เมื่อถูก implement ทำให้ไม่ต้องระบุประเภทใหม่ทุกครั้งที่ใช้งาน ซึ่ง ก็จะมีข้อดีในการลดความยุ่งยากในการกำหนดประเภทซ้ำ ๆ เพราะประเภทถูก “ผูก” กับ Trait ตอน implement แล้วเรียบร้อย
- เหมาะสำหรับสถานการณ์ที่ Trait มีประเภทเฉพาะที่ไม่เปลี่ยนแปลงในแต่ละ implement
ดังนั้น จากการเปรียบเทียบ เราจะได้ข้อสรุปว่า
- ใช้ Generic: เมื่อคุณต้องการความยืดหยุ่นสูง และประเภทที่ใช้กับ Trait อาจแตกต่างกันไปในแต่ละครั้งที่ใช้งาน
- ใช้ Associated Types: เมื่อ Trait และประเภทมีความสัมพันธ์ที่แน่นอน และต้องการลดความซับซ้อนของการระบุประเภทใน code ได้
รวมถึงหากมองในแง่ compiler ตามหลักการของ Monomorphization
- Generic สำหรับ Generic Type Parameter (
T) compiler จะสร้าง code ที่แตกต่างกันสำหรับแต่ละประเภทที่ใช้ โดย หากมีประเภทจำนวนมากที่ถูกใช้งาน จะเพิ่มขนาดของ binary และอาจทำให้การ compile ช้าลงได้ - กลับกัน Associated Types ไม่เพิ่มจำนวน code ที่ต้องสร้างแบบ Monomorphized เพราะประเภทถูกกำหนดตายตัวในตอน implement Trait แล้ว
ดังนั้น ก็จะมีประเด็นนี้ด้วยที่อาจจะส่งผลต่อขนาด binary ได้เช่นกัน
Dynamic Dispatch
Dynamic Dispatch คือการกำหนดพฤติกรรมของ Trait แบบ dynamic ในเวลา runtime แทนที่จะกำหนดล่วงหน้าในเวลา compile (Static Dispatch) โดยใช้ Trait Object (dyn Trait) เพื่อสร้างความยืดหยุ่นในการจัดการประเภทที่แตกต่างกันที่ implement Trait เดียวกันไว้
Dynamic Dispatch ใช้ vtable (Virtual Table) ซึ่งเป็นโครงสร้างข้อมูลที่เก็บรายการของ function ที่ประเภทที่ implement Trait นั้นรองรับ เมื่อมีการเรียกใช้ function ผ่าน Trait Object compiler จะค้นหาและเรียก function ที่เหมาะสมจาก vtable ในเวลา runtime ออกมาได้
ดังเช่นแบบนี้ (ตัวอย่างจาก https://www.lurklurk.org/effective-rust/generics.html)
let square = Square { top_left: Point { x: 1, y: 2 }, size: 2,};let draw: &dyn Draw = □เมื่อตอนเก็บลงใน memory ก็จะมีหน้าตาประมาณนี้
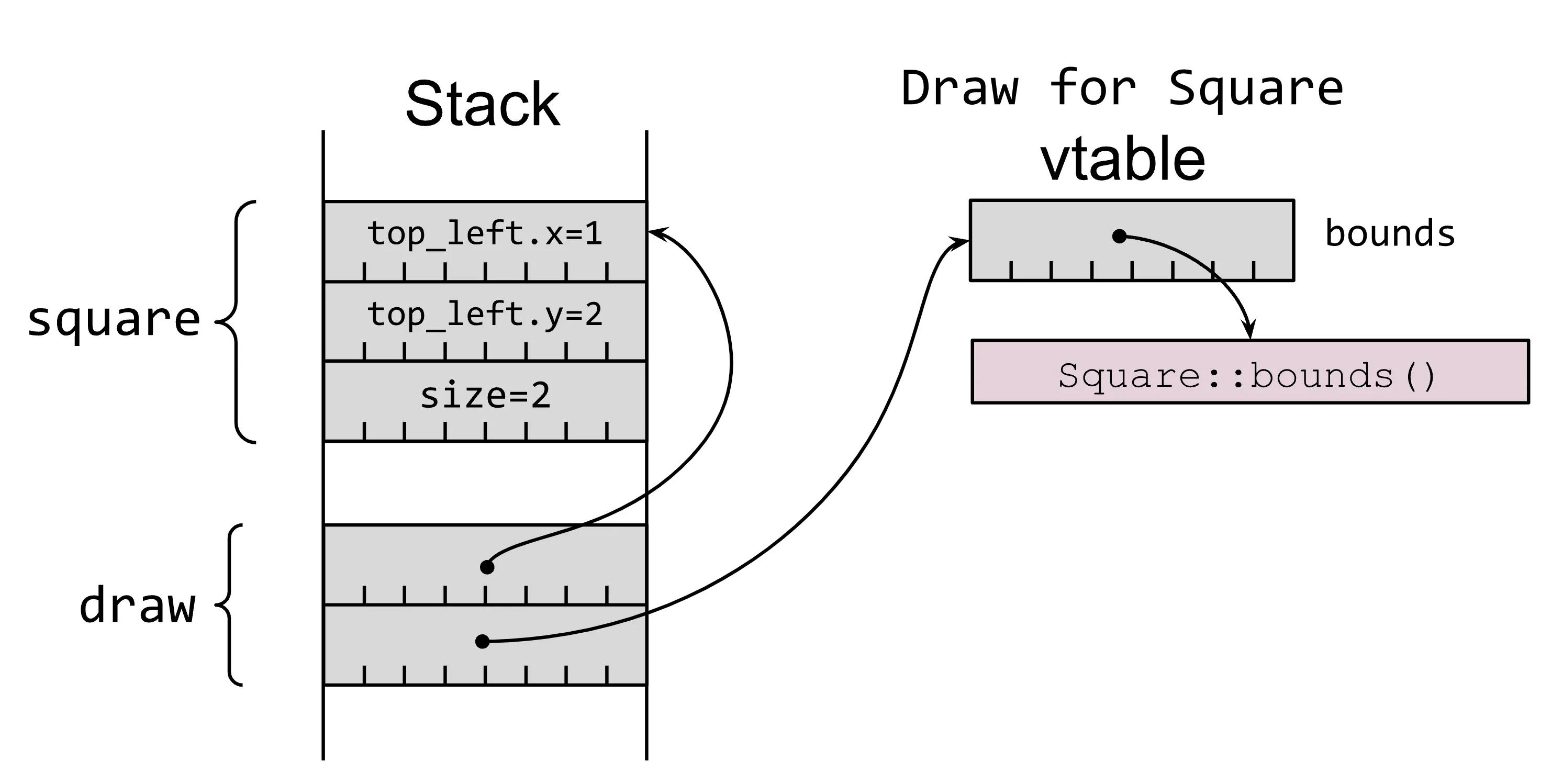
จากภาพนี้แสดงการทำงานของ Dynamic Dispatch และ vtable ใน Rust โดย
- โครงสร้าง
squareมีข้อมูล เช่นtop_left.x,top_left.y, และsizeที่ถูกจัดเก็บในหน่วยความจำ - เมื่อเรียกใช้ function
drawผ่านdyn Traitระบบจะใช้ vtable (Virtual Table) ซึ่งเป็นตารางที่เก็บรายการ function ที่ประเภทSquareได้ implement ไว้ เช่นSquare::bounds()ในเวลา runtime - ระบบจะค้นหาและเรียก function ที่เหมาะสมจาก vtable โดยอ้างอิงจากข้อมูลของประเภทจริง (
Square) ช่วยให้สามารถเรียก function ที่แตกต่างกันได้แม้จะผ่าน Trait เดียวกัน
เพิ่มเติมตัวอย่างการใช้งานแบบ code เต็ม เช่น code นี้
trait Greet { fn say_hello(&self);}
struct Robot;struct Human;
impl Greet for Robot { fn say_hello(&self) { println!("Greetings, human! I am a robot."); }}
impl Greet for Human { fn say_hello(&self) { println!("Hello! I'm a human."); }}
fn greet(greeter: &dyn Greet) { greeter.say_hello();}
fn main() { let robot = Robot; let human = Human;
greet(&robot); // Output: Greetings, human! I am a robot. greet(&human); // Output: Hello! I'm a human.}&dyn Greetคือ Trait Object ที่รองรับ Dynamic Dispatch- function
greetสามารถรับค่าประเภทใดก็ได้ที่ implement TraitGreet - ในเวลา runtime ระบบจะเรียก function ที่ตรงกับประเภทจริงของค่าที่ส่งมาได้ (
RobotหรือHuman)
ประโยชน์ของการใช้ Dynamic Dispatch
- Polymorphism: Dynamic Dispatch ช่วยให้สามารถจัดการกับหลายประเภทข้อมูลที่ implement Trait เดียวกันได้ โดยไม่ต้องทราบประเภทจริงในเวลา compile เช่น การสร้าง Trait Object (
dyn Trait) ช่วยให้ function เดียวรองรับหลายประเภทได้ เช่นdrawสามารถใช้กับทั้งCircleและSquare - Binary Size: Dynamic Dispatch ไม่ต้องสร้าง code หลายชุดผ่านกระบวนการ Monomorphization เหมือน Static Dispatch ทำให้ขนาดไฟล์ binary เล็กลง โดยเฉพาะเมื่อมีการใช้งานประเภทที่หลากหลาย
- Dynamic: ในโครงสร้างข้อมูลที่เก็บวัตถุหลายประเภท เช่น
Vec<Box<dyn Trait>>เราสามารถเก็บประเภทที่แตกต่างกันซึ่ง implement Trait เดียวกันได้ โดยไม่ต้องใช้ Generic หรือระบุขนาดที่แน่นอนล่วงหน้า
trait Shape { fn draw(&self);}
struct Circle;struct Square;
impl Shape for Circle { fn draw(&self) { println!("Drawing a circle."); }}
impl Shape for Square { fn draw(&self) { println!("Drawing a square."); }}
fn main() { let shapes: Vec<Box<dyn Shape>> = vec![Box::new(Circle), Box::new(Square)]; for shape in shapes { shape.draw(); // ใช้ Dynamic Dispatch เรียก function ของแต่ละประเภท }}ข้อควรระวังในการใช้ Dynamic Dispatch
- Overhead ที่เพิ่มขึ้น: Dynamic Dispatch มีค่า Overhead เพิ่มจากการค้นหาและเรียก function ผ่าน vtable
- Trait Object (
dyn Trait) ไม่รองรับการใช้งานร่วมกับ Generic หรือ Associated Types
Standard library
นอกเหนือจากการสร้าง Trait ทั่วไปแล้ว Rust ยังมี Standard Library ที่ช่วยในเรื่อง Trait Bound ได้ โดยมี Trait สำเร็จรูปที่ใช้กันอย่างแพร่หลาย เช่น Copy, Clone, Debug, PartialEq, Ord, และ Hash ซึ่งช่วยในการกำหนดพฤติกรรมพื้นฐานสำหรับประเภทต่าง ๆ และสามารถใช้ Trait Bound เหล่านี้ร่วมกับ Generic เพื่อเพิ่มความปลอดภัยและความยืดหยุ่นของ code
ตัวอย่างการใช้ Trait Bound จาก Standard Library ที่มักจะเจอได้บ่อยๆ
- ใช้
Debugเพื่อพิมพ์ค่า โดยใช้ TraitDebugใช้สำหรับแสดงค่าของประเภทในรูปแบบ Debug (ผ่าน{:?})
fn print_debug<T: std::fmt::Debug>(value: T) { println!("{:?}", value);}
fn main() { print_debug(42); // Output: 42 print_debug("Hello, Rust!"); // Output: "Hello, Rust!"}- ใช้
Cloneเพื่อทำสำเนา โดยใช้ TraitCloneช่วยให้สามารถสร้างสำเนาของค่าที่มีประเภทT
fn duplicate<T: Clone>(value: T) -> (T, T) { (value.clone(), value)}
fn main() { let text = String::from("Rust"); let (a, b) = duplicate(text.clone()); println!("{} and {}", a, b); // Output: Rust and Rust}- ใช้
PartialEqเพื่อเปรียบเทียบค่า โดย TraitPartialEqใช้ในการเปรียบเทียบความเท่า (==) ระหว่างสองค่าที่มีประเภทเดียวกัน
fn are_equal<T: PartialEq>(a: T, b: T) -> bool { a == b}
fn main() { println!("{}", are_equal(5, 5)); // Output: true println!("{}", are_equal("Rust", "Go")); // Output: false}- ใช้
Ordเพื่อเรียงลำดับ โดย TraitOrdช่วยจัดการการเรียงลำดับค่าต่าง ๆ เช่น การเปรียบเทียบด้วย<หรือ>
fn compare_values<T: Ord>(a: T, b: T) -> &str { if a < b { "a is less than b" } else if a > b { "a is greater than b" } else { "a is equal to b" }}
fn main() { println!("{}", compare_values(5, 10)); // Output: a is less than b println!("{}", compare_values(20, 10)); // Output: a is greater than b}- ใช้
Hashเพื่อสร้างค่า Hash โดย TraitHashใช้ในการสร้างค่า Hash สำหรับประเภทที่กำหนด
use std::collections::HashSet;use std::hash::Hash;
fn unique_items<T: Eq + Hash>(items: Vec<T>) -> HashSet<T> { items.into_iter().collect()}
fn main() { let numbers = vec![1, 2, 2, 3, 4, 4]; let unique_numbers = unique_items(numbers); println!("{:?}", unique_numbers); // Output: {1, 2, 3, 4}}- ใช้
Addเพื่อกำหนดว่าTต้อง implement TraitAddและผลลัพธ์ของการบวก (Output) ต้องเป็นประเภทเดียวกันกับT
use std::ops::Add;
fn add<T: Add<Output = T>>(a: T, b: T) -> T { a + b}
fn main() { let int_sum = add(5, 10); // บวกจำนวนเต็ม let float_sum = add(5.5, 10.5); // บวกทศนิยม println!("Integer sum: {}", int_sum); println!("Float sum: {}", float_sum);}ข้อดีของการใช้ Standard library กับ Trait
- Code Reusability: Standard Library มี Trait ที่เตรียมไว้แล้ว เช่น
Clone,Copy,Debug,PartialEq, และOrdซึ่งครอบคลุมพฤติกรรมพื้นฐานที่พบได้บ่อย การใช้ Trait เหล่านี้ช่วยลดความจำเป็นในการสร้าง Trait ใหม่ที่ทำหน้าที่เหมือนกันได้ - Type Safety: Standard Library Trait ช่วยให้มั่นใจได้ว่าประเภทข้อมูลที่ใช้ต้องรองรับพฤติกรรมที่ต้องการ เช่น การเปรียบเทียบ (
PartialEq) หรือการเรียงลำดับ (Ord) โดย compiler จะตรวจสอบเงื่อนไขเหล่านี้ในเวลา compile ได้ - Flexibility: Trait ใน Standard Library เช่น
Add,Mul, และIteratorช่วยให้ function หรือโครงสร้างข้อมูลทำงานได้กับประเภทที่หลากหลายโดยใช้ Trait Bound ได้ - ใช้ร่วมกับตัวอื่นๆใช้ Standard library ได้: โครงสร้างข้อมูลและ function ใน Standard Library เช่น
Vec,HashMap, และIteratorออกแบบมาเพื่อทำงานร่วมกับ Trait เหล่านี้โดยตรง ทำให้การพัฒนา software ง่ายขึ้น เช่น การใช้ TraitIteratorในการประมวลผลข้อมูล ดัง code ด้านล่างนี้
fn sum_values<T: std::iter::Sum>(values: Vec<T>) -> T { values.into_iter().sum()}Smart Pointer
https://doc.rust-lang.org/book/ch15-00-smart-pointers.html
ก่อนที่เราจะพูดถึง Smart Pointer กัน ขอเล่าเรื่อง Pointer ที่เป็นรากฐานสำคัญของ low level programming กันก่อน
Pointer คือ ตัวแปรที่เก็บที่อยู่หน่วยความจำ (Memory Address) ของตัวแปรหรือข้อมูลอื่นในโปรแกรม โดย Pointer ใช้ในการอ้างอิงข้อมูลที่อยู่ในตำแหน่งความจำต่างๆ ซึ่งช่วยให้การทำงานใน low level programming สะดวกและมีประสิทธิภาพมากขึ้น
โดย Pointer จะมีบทความสำคัญคือ
- การจัดการหน่วยความจำแบบ dynamic (Dynamic Memory Management)
- การส่งค่าผ่าน Reference (Pass by Reference)
- การทำงานกับโครงสร้างข้อมูล เช่น Array, Linked List, Tree
- การเข้าถึงฮาร์ดแวร์ใน low level
โดย หากมองไปที่ภาษา C++ ที่เป็น low level programming ที่ developer มักใช้กันเมื่อต้องทำงานร่วมกับ hardware เราก็จะเจอประเด็นของ Pointer ว่า
- C++ ใช้ Pointer แบบดั้งเดิม (
int* ptr) ที่สามารถชี้ไปยังตำแหน่งหน่วยความจำใดก็ได้ - developer ต้องจัดการหน่วยความจำเอง เช่น การจอง (
new) และการคืนหน่วยความจำ (delete) - ไม่มีระบบป้องกันความผิดพลาด เช่น Null Pointer Dereference (การเข้าถึง Pointer ที่ชี้ไปยังตำแหน่ง null) อาจทำให้เกิดข้อผิดพลาดร้ายแรงขึ้นได้ (Segmentation Fault)
- ทีนี้เพื่อป้องกันปัญหาเรื่องนี้ C++ ก็เลยได้มี library Smart Pointer เตรียมไว้ให้ โดยมีการเพิ่ม
std::shared_ptrและstd::unique_ptrเพื่อช่วยจัดการหน่วยความจำอัตโนมัติเอาไว้เช่นกัน แต่ยังคงต้องระมัดระวังการใช้งานร่วมกันใน code ที่ไม่ได้ใช้ Smart pointer ด้วยเช่นกัน
ทีนี้ มองมาที่ Rust บ้าง
- Rust ไม่มี Pointer แบบดั้งเดิม แต่ใช้แนวคิด Ownership, Borrowing, และ Lifetimes เพื่อควบคุมหน่วยความจำแทน
- Rust มีการป้องกันข้อผิดพลาด เช่น Null Pointer หรือ Dangling Pointer (Pointer ที่อ้างอิงหน่วยความจำที่ถูกคืนไปแล้ว) เอาไว้ในระดับ compiler ของ Rust เองแล้วเรียบร้อย โดย design ภาษาจะไม่อนุญาตให้ code ที่ไม่ปลอดภัยทำงานได้
- รวมถึง Rust เองก็มี Smart Pointer เช่น
Box,Rc, และRefCellสำหรับการจัดการหน่วยความจำด้วยเช่นกัน (ซึ่งจะเป็นประเด็นที่เราจะเขียนถึงต่อ) - แต่ทั้งนี้ Rust เองก็ยังมี Raw Pointer (
const Tและmut T) ซึ่งคล้าย Pointer แบบดั้งเดิมใน C++ แต่ควรต้องใช้งานในส่วน code ที่ไม่ปลอดภัย (unsafeblock) มากกว่า
ทีนี้เมื่อเราลองเทียบ 2 ภาษาอย่าง C++ กับ Rust ดู เราจะค้นพบว่า สิ่งหนึ่ง 2 ภาษานี้มีเหมือนกัน นั่นคือ Smart pointer คำถามก็เลยเกิดขึ้นมาว่า “ถ้างั้น Smart Pointer คืออะไร และทำไมต้องมีเพิ่มเข้ามาทั้งๆที่เราจัดการหน่วยความจำเองก็ได้”
Smart Pointer คืออะไร
Smart Pointer คือโครงสร้างข้อมูลที่ทำหน้าที่เหมือน Pointer ทั่วไป (เก็บที่อยู่ของหน่วยความจำ) แต่มีคุณสมบัติเพิ่มเติมที่ช่วยจัดการหน่วยความจำอัตโนมัติ เช่น การคืนหน่วยความจำเมื่อไม่ใช้งาน (Automatic Memory Management) โดยใช้เทคนิคอย่าง Reference Counting หรือ RAII (Resource Acquisition Is Initialization) ทำให้ code มีความปลอดภัยและลดโอกาสเกิดข้อผิดพลาด เช่น Memory Leak หรือ Dangling Pointer ที่จะเกิดขึ้นได้
แม้ว่าเราจะจัดการหน่วยความจำเองได้ แต่การจัดการหน่วยความจำด้วยตนเองมักมีความเสี่ยงและข้อผิดพลาดที่อาจเกิดขึ้นได้บ่อย เช่น
- Memory Leak: หากลืมคืนหน่วยความจำที่จองไว้ จะทำให้เกิด Memory Leak ส่งผลให้หน่วยความจำไม่เพียงพอเมื่อโปรแกรมทำงานไปนานๆ
- Dangling Pointer: Pointer ที่ชี้ไปยังหน่วยความจำที่ถูกคืนแล้ว หากใช้งาน Pointer นั้นอีกจะเกิดข้อผิดพลาดร้ายแรง เช่น Segmentation Fault
- Null Pointer Dereference: การเข้าถึง Pointer ที่เป็น
nullจะทำให้โปรแกรม crash ได้
ซึ่งอย่างที่เราเห็น เพื่อตัดปัญหาการจัดการ Memory ด้วย pointer ใน Rust จึงตัดสินใจไม่มี Pointer แบบดั้งเดิม แต่เลือกให้ทุกอย่างจัดการผ่าน Smart Pointer แทน
แต่การเลือกใช้งาน Smart Pointer ใน Rust ไม่ได้หมายความว่าเราสูญเสียความยืดหยุ่นในการจัดการ Memory ไปนะครับ แต่กลับทำให้โปรแกรมมีความปลอดภัยมากขึ้นในเชิงหน่วยความจำ ด้วยระบบ Ownership และ Borrowing ที่ทำงานควบคู่กัน
Smart Pointer ใน Rust ช่วยให้เราจัดการหน่วยความจำได้อย่างมีประสิทธิภาพ โดยไม่ต้องกังวลเรื่องปัญหาเช่น Null Pointer หรือ Dangling Pointer ที่พบในภาษาดั้งเดิม ทั้งยังรองรับการใช้งาน Raw Pointer สำหรับกรณีที่ต้องการประสิทธิภาพสูงสุด ทำให้ Rust กลายเป็นภาษาที่สมดุลระหว่างความยืดหยุ่นและความปลอดภัยของโปรแกรมได้อย่างลงตัวอีกหนึ่งภาษาเช่นกัน
ทีนี้ ถึงจุดนี้หลายคนก็อาจจะสงสัยเพิ่มเติมว่า “ถ้าอย่างนั้น use case อะไรบ้างที่ควรใช้ Smart Pointer ในการทำ Software” เพื่อให้เกิดความเข้าใจที่ถ่องแท้ขึ้น เราต้องอธิบาย Memory ในการเก็บข้อมูลกันว่าจริงๆแล้วข้อมูลถูกจัดเก็บใน memory อย่างไร
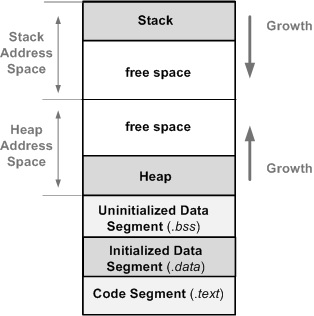
Ref: https://open4tech.com/memory-layout-embedded-c-programs/
โดยทั่วไปแล้ว หน่วยความจำของโปรแกรมจะถูกแบ่งออกเป็นหลายส่วนที่มีหน้าที่แตกต่างกัน ได้แก่ Stack, Heap, Data Segment และ Code Segment ซึ่งแต่ละส่วนมีบทบาทเฉพาะตัวในการจัดเก็บข้อมูลที่จำเป็นสำหรับการทำงานของโปรแกรม
- Stack เป็นพื้นที่สำหรับเก็บตัวแปรแบบ local และข้อมูลที่เกี่ยวข้องกับ function เช่น parameter และตัวแปรที่ประกาศใน function โดยมีการเรียกใช้งานแบบ LIFO (Last In, First Out) ซึ่งมีความเร็วสูงในการจัดการ แต่มีขนาดจำกัด
- Heap ใช้สำหรับเก็บข้อมูลแบบ dynamic memory allocation ซึ่ง developer สามารถจัดสรรและคืนค่าหน่วยความจำใน runtime ได้ มีความยืดหยุ่นสูงแต่ต้องระวังการจัดการหน่วยความจำไม่ให้เกิดปัญหา เช่น memory leak
- Data Segment แบ่งออกเป็นส่วนของข้อมูลที่ถูกกำหนดค่าไว้ล่วงหน้า (Initialized Data) และข้อมูลที่ยังไม่ได้กำหนดค่า (Uninitialized Data หรือ BSS Segment) ใช้เก็บตัวแปร global และ static
- Code Segment (หรือ Text Segment) ใช้สำหรับเก็บคำสั่งที่โปรแกรมต้องดำเนินการ เป็นส่วนที่ไม่สามารถเขียนทับได้ใน runtime เพื่อความปลอดภัย
เท่ากับว่า ในเคสของการเขียน code ทั่วไป ข้อมูลตัวแปรทั้งหมดที่เราใช้ จะถูกเก็บอยู่ใน Stack เอาไว้ ในกรณีของการเขียน code ทั่วไปใน Rust ข้อมูลตัวแปรส่วนใหญ่ที่มีขนาดคงที่และทราบขนาดในเวลา compile time จะถูกเก็บไว้ใน Stack เนื่องจาก Stack มีความเร็วในการเข้าถึงสูงและจัดการง่ายผ่านรูปแบบ LIFO
ตัวอย่าง เช่น code นี้
fn main() { let x = 5; // ตัวแปรชนิด integer ถูกเก็บใน Stack let y = "Hello, Rust!"; // ตัวแปรชนิด &str (String slice) ถูกเก็บใน Stack println!("x = {}, y = {}", x, y);} // เมื่อออกจาก scope = x, y ก็จะโดนนำออกจาก stack ไปในตัวอย่างนี้
xเป็นตัวแปรชนิด integer (i32โดยค่าเริ่มต้น) ซึ่ง Rust จะเก็บค่าของมันไว้ใน Stackyเป็น string slice (&str) ซึ่ง pointer และ metadata (length) ของ string จะถูกเก็บใน Stack แต่ข้อมูลตัว string จริง ๆ (“Hello, Rust!”) จะเก็บไว้ในส่วนอื่น เช่น.rodata(read-only data segment)
อย่างไรก็ตาม ตัวแปรที่เก็บบน Stack จะถูกจัดการโดยอัตโนมัติผ่านระบบ ownership และ scope ของ Rust โดยสำหรับ Rust ระบบจะจัดการหน่วยความจำของ Stack ให้โดยอัตโนมัติ ตัวแปรจะถูกสร้างและลบออกจาก Stack เมื่อออกนอก scope โดยไม่ต้องเขียน code เพื่อจัดการเอง ทำให้การจัดการหน่วยความจำมีความปลอดภัยและลดโอกาสเกิดปัญหาหน่วยความจำ เช่น dangling pointers หรือ memory corruption ไว้ได้
ทีนี้แล้ว Heap ละ จะโดนเก็บไว้ในเคสไหน
ใน Rust ข้อมูลจะถูกจัดเก็บใน Heap เมื่อเราต้องการการจัดสรรหน่วยความจำแบบ dynamic หรือเมื่อข้อมูลมีขนาด “ไม่สามารถทราบได้ในเวลา compile time” การจัดเก็บใน Heap มีความยืดหยุ่น แต่การเข้าถึงจะช้ากว่า Stack เนื่องจากต้องอาศัย pointer เพื่อเข้าถึงข้อมูล
ตัวอย่างการใช้ Heap ใน Rust
fn main() { let heap_value = Box::new(42); // ตัวเลข 42 ถูกจัดเก็บใน Heap println!("Heap value = {}", heap_value);
let vec = vec![1, 2, 3, 4, 5]; // ข้อมูลใน Vec ถูกเก็บใน Heap println!("Vector values = {:?}", vec);}จาก code
- **
Box::new(42)**ใช้Box<T>ซึ่งเป็น Smart Pointer สำหรับการจัดเก็บข้อมูล42บน Heap โดย pointer จะเก็บไว้บน Stack เพื่อชี้ไปยังตำแหน่งใน Heap ที่เก็บค่าจริง vec![1, 2, 3, 4, 5]เมื่อสร้างVec<T>(vector) Rust จะจัดเก็บ metadata เช่น ความยาวและ pointer บน Stack แต่เนื้อหาของ vector (เช่น ตัวเลข1-5) จะถูกจัดเก็บบน Heap
ดังนั้นจากเรื่อง memory ทั้ง 2 เรื่องนี้
- เราจะใช้ Stack เมื่อข้อมูลของเรามีขนาดคงที่ (fixed size) และทราบขนาดได้ในเวลา compile time เช่นตัวแปรพื้นฐาน (primitive types) หรือ references โดย Stack เหมาะสำหรับการเก็บข้อมูลชั่วคราวที่มี lifetime สั้นและต้องการความเร็วสูงในการเข้าถึง รวมถึงข้อมูลที่สามารถลบออกได้โดยอัตโนมัติเมื่อออกนอก scope
- เราจะใช้ Heap เมื่อข้อมูลของเรามีขนาดไม่แน่นอนหรือใหญ่เกินกว่าจะเก็บใน Stack เช่นการสร้างโครงสร้างข้อมูลที่ต้องการ dynamic memory allocation เช่น vectors หรือ
Box<T>ซึ่งช่วยให้เราสามารถจัดการหน่วยความจำได้อย่างยืดหยุ่นและรองรับการใช้งานในระยะยาว โดยต้องอาศัย pointer และระบบ ownership ของ Rust เพื่อควบคุมการเข้าถึงและการจัดการหน่วยความจำอย่างปลอดภัย
ทีนี้เรากลับมาสู่ Smart Pointer บ้าง แล้ว Smart pointer เกี่ยวข้องอย่างไรกับเรื่อง Stack และ Heap
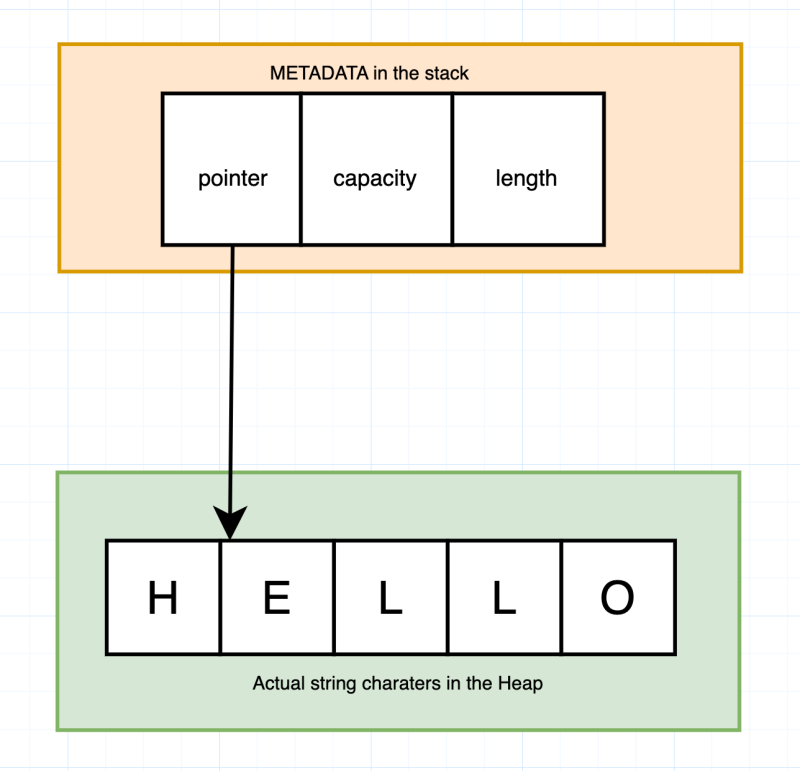
Ref: https://ezesunday.com/blog/choosing-between-str-and-string-in-rust/
Smart Pointer ใน Rust มีความเกี่ยวข้องกับ Stack และ Heap ในการจัดการหน่วยความจำ โดยทำหน้าที่เป็นตัวกลางที่ช่วยจัดการการอ้างอิงและการปลดปล่อยหน่วยความจำอย่างปลอดภัย โดยจะใช้ทั้งหน่วยความจำส่วน Stack และ Heap ทั้งคู่
- ใช้ Stack ทำอะไร ?
- Pointer และ Metadata บน Stack: Smart Pointer เช่น
Box<T>หรือRc<T>จะเก็บ pointer และ metadata ที่เกี่ยวข้อง (เช่น reference count สำหรับRc<T>) ไว้บน Stack เพื่อชี้ไปยังข้อมูลจริงที่อยู่ใน Heap - การจัดการ Lifetime: ระบบ Smart Pointer ใช้ scope ของ Stack เพื่อควบคุมการสร้างและการทำลายข้อมูลใน Heap ตัวอย่างเช่น เมื่อ Smart Pointer ออกจาก scope Rust จะเรียก drop เพื่อคืนค่าหน่วยความจำใน Heap
- Pointer และ Metadata บน Stack: Smart Pointer เช่น
- ใช้ Heap ทำอะไร ?
- การจัดเก็บข้อมูลจริงใน Heap: Smart Pointer จะจัดเก็บข้อมูลจริงใน Heap เมื่อข้อมูลมีขนาดไม่แน่นอนหรือไม่สามารถเก็บใน Stack ได้ เช่น
Box<T>ใช้เก็บข้อมูลใน Heap โดยตรง และRc<T>หรือArc<T>ช่วยให้แชร์ข้อมูลใน Heap ได้ระหว่างหลายส่วนของโปรแกรม - Dynamic Memory Management: Smart Pointer ช่วยจัดการหน่วยความจำใน Heap เช่น การเพิ่มหรือลด reference count (
Rc<T>และArc<T>), การเข้าถึงข้อมูลแบบ mutable (RefCell<T>), และการประมวลผล concurrent (Mutex<T>)
- การจัดเก็บข้อมูลจริงใน Heap: Smart Pointer จะจัดเก็บข้อมูลจริงใน Heap เมื่อข้อมูลมีขนาดไม่แน่นอนหรือไม่สามารถเก็บใน Stack ได้ เช่น
ดังนั้น ถ้าเราจะสรุปภายใน 1 ประโยคคือ Smart Pointer คือตัวที่ทำหน้าที่จัดการการเชื่อมโยงระหว่าง Stack (สำหรับ metadata และ pointer) และ Heap (สำหรับข้อมูลจริง)
โดยสิ่งนี้ยังคง concept ของ Ownership ไว้ได้ แม้จะ dynamic ที่ runtime เพราะ Smart Pointer ใน Rust ถูกออกแบบมาให้ปฏิบัติตามระบบ Ownership ผ่านการควบคุมหน่วยความจำด้วยวิธีที่ปลอดภัย เช่น
- การเป็นเจ้าของข้อมูลใน Heap โดยสมบูรณ์ (เช่น
Box<T>) - การแบ่งปัน ownership อย่างชัดเจนผ่าน reference counting (เช่น
Rc<T>และArc<T>) - การจัดการการเปลี่ยนแปลงข้อมูลแบบ interior mutability (เช่น
RefCell<T>หรือMutex<T>)
โดย Smart Pointer จะรับประกันว่าเมื่อเจ้าของสุดท้ายของข้อมูลออกนอก scope “หน่วยความจำจะถูกคืนค่าให้ระบบโดยอัตโนมัติ” ซึ่งช่วยรักษาความปลอดภัยและหลีกเลี่ยงปัญหาหน่วยความจำ เช่น dangling pointer หรือ memory leak แม้การจัดสรรหน่วยความจำจะเกิดขึ้นแบบ dynamic ใน runtime ขึ้นมาก็ตาม
เพื่อให้เราเห็นภาพมากขึ้น เราจะมาทำความรู้จัก Smart Pointer ตัวเด่นทั้ง 3 ตัวก่อนคือ Box<T>, Rc<T>, RefCell<T> ตามที่เรายกตัวอย่างไปกัน
Box
Box<T> คือ smart pointer ที่ใช้สำหรับจัดการหน่วยความจำใน heap โดยเฉพาะในกรณีที่ต้องการเก็บข้อมูลที่ขนาดไม่แน่นอนหรืออ้างถึงข้อมูลที่ต้องการอายุการใช้งานยาวขึ้น แต่ยังคงปลอดภัยในการใช้งานในระบบของ Rust ที่มี ownership และ borrowing เป็นพื้นฐาน
คุณสมบัติเด่นๆของ Box<T>
Boxเป็น immutable โดยค่าเริ่มต้น แต่สามารถเปลี่ยนเป็น mutable ได้ถ้าต้องการ- เมื่อ
Boxถูก drop หน่วยความจำที่จัดสรรไว้บน heap จะถูกคืนค่าโดยอัตโนมัติ
โดย Box<T> จะช่วยในการ
- จัดการหน่วยความจำบน heap
- ทำงานร่วมกับชนิดข้อมูลที่มีขนาดไม่ทราบล่วงหน้า เช่น recursive types
ตัวอย่างการใช้งาน
fn main() { let x = Box::new(10); // จัดเก็บค่า 10 บน heap println!("ค่าใน Box คือ: {}", x);}- ในตัวอย่างนี้ ค่า
10ถูกจัดเก็บไว้บน heap และxเป็นตัวชี้ (smart pointer) ไปยังตำแหน่งนั้น
หรือตัวอย่างกับการใช้กับ Recursive Type
enum List { Node(i32, Box<List>), Nil,}
use List::{Node, Nil};
fn main() { let list = Node(1, Box::new(Node(2, Box::new(Node(3, Box::new(Nil))))));
print_list(&list);}
fn print_list(list: &List) { match list { Node(value, next) => { print!("{} -> ", value); print_list(next); } Nil => println!("Nil"), }}ในตัวอย่างนี้
Boxช่วยให้สามารถกำหนด recursive type (List) ได้โดยไม่ก่อให้เกิดปัญหาในเรื่องขนาดที่ไม่สิ้นสุดระหว่าง compile-time ได้- โดย
Boxจะช่วยลดภาระของระบบหน่วยความจำโดยใช้ heap แทน stack
อีกตัวอย่าง ที่จะเปลี่ยน Box เป็น mutable
fn main() { let mut x = Box::new(10); // สร้าง Box แบบ mutable
println!("ค่าเริ่มต้นใน Box: {}", x);
// เปลี่ยนค่าภายใน Box *x = 20; // ใช้ dereference (*) เพื่อแก้ไขค่าภายใน Box
println!("ค่าที่เปลี่ยนใน Box: {}", x);}- ใช้ตัวดำเนินการ dereference (*) เพื่อเข้าถึงค่าภายใน
Box<T>และเปลี่ยนเป็นค่าที่ต้องการ หลังจากเปลี่ยนค่าBox<T>จะเก็บค่าที่อัปเดตใหม่เข้าไป
แต่ๆ การใช้ Box<T> แบบ mutable เพื่อเปลี่ยนค่าภายในเป็นสิ่งที่ ไม่ใช่เรื่องที่ทำบ่อย ใน Rust เนื่องจากมี concept อื่นที่สามารถแก้ไขแบบ mutable ได้ และ concept ตรงไปตรงมามากกว่า (เช่น Vec<T> หรือ RefCell<T>)
Rc
Rc<T> คือ reference-counted smart pointer ที่ช่วยให้สามารถแชร์ ownership ของค่าบน heap ระหว่างตัวแปรหลายตัวได้ โดยจะนับจำนวน reference ที่ชี้ไปยังค่าดังกล่าว และเมื่อไม่มี reference ใดเหลืออยู่ ระบบจะปลดปล่อยหน่วยความจำบน heap โดยอัตโนมัติ
โดยคุณสมบัติเด่นๆของ Rc<T> คือ
- ใช้สำหรับสถานการณ์ที่ต้องแชร์ข้อมูลเดียวกันระหว่างหลายตัวแปรใน thread เดียว
- ทำงานในลักษณะ immutable shared ownership (ค่าภายใน
Rc<T>เปลี่ยนแปลงไม่ได้โดยตรง)
ตัวอย่างการใช้งาน แชร์ค่าระหว่างหลายตัวแปร
use std::rc::Rc;
fn main() { let value = Rc::new(10); // สร้าง Rc ที่เก็บค่าบน heap let a = Rc::clone(&value); // เพิ่ม reference ไปยังค่าใน Rc let b = Rc::clone(&value); // เพิ่ม reference อีกตัว
println!("ค่าใน a: {}", a); println!("ค่าใน b: {}", b); println!("Reference count: {}", Rc::strong_count(&value)); // แสดงจำนวน reference}ผลลัพธ์
ค่าใน a: 10ค่าใน b: 10Reference count: 3จาก code
valueถูกแชร์ระหว่างตัวแปรaและb- ใช้
Rc::cloneเพื่อเพิ่ม reference count โดยไม่สร้าง copy ใหม่ - จำนวน reference (
Rc::strong_count) แสดงว่าvalueถูกแชร์ 3 ตัว (รวมvalue,a, และb)
หรือ อีกตัวอย่าง ใช้ Rc<T> กับโครงสร้างข้อมูลที่เป็น Graph
use std::rc::Rc;
struct Node { value: i32, next: Option<Rc<Node>>,}
fn main() { let node1 = Rc::new(Node { value: 1, next: None }); let node2 = Rc::new(Node { value: 2, next: Some(Rc::clone(&node1)) }); let node3 = Rc::new(Node { value: 3, next: Some(Rc::clone(&node2)) });
println!("ค่าใน node3: {}", node3.value); if let Some(ref next) = node3.next { println!("ค่าใน node2: {}", next.value); } if let Some(ref next) = node3.next.as_ref().unwrap().next { println!("ค่าใน node1: {}", next.value); }}ก็จะเป็นอีก concept หนึ่งที่ใช้สำหรับ share ownership ระหว่างกันได้ (จากแต่เดิมตามระบบ ownership ที่จะ strict ให้มี owner เพียงแค่ทีละ 1 เท่านั้น)
คำถามคือ “เมื่อไหร่ควรใช้ Rc<T> ?”
- เมื่อมีข้อมูลที่ต้องการแชร์แบบ immutable ระหว่างหลายส่วนของโปรแกรม
- เมื่อไม่สามารถใช้
Box<T>หรือVec<T>ได้เพราะต้องการแชร์ ownership
ทีนี้หลายคนก็อาจจะสงสัย concept RC มันเหมือนกับเวลาเราอ้างอิงไปยัง Address ของ pointer เลย (ที่สามารถ Borrow มากกว่า 1 ตัวได้จากเรื่อง Ownership) แล้ว concept RC ดีกว่าการ Borrow ปกติอย่างไร ?
เหตุผลที่ Rc ดีกว่าการ Borrow ปกติก็คือ มันช่วยให้เราสามารถแชร์ ownership ของค่าเดียวกันได้อย่างปลอดภัยและยืดหยุ่นยิ่งขึ้น ในขณะที่ Borrow ปกติใช้ระบบ lifetime constraints ที่บังคับให้ reference ต้องมีอายุการใช้งานไม่เกิน owner ตัวต้นทาง ซึ่งอาจทำให้การแชร์ข้อมูลระหว่างหลายส่วนของโปรแกรมซับซ้อนหรือเป็นไปไม่ได้ในบางกรณี
แต่ Rc ใช้ระบบ reference counting ในการจัดการอายุการใช้งานของค่า โดยที่เราสามารถ clone ตัว Rc เพื่อสร้างการอ้างอิงใหม่ได้โดยไม่ต้องกังวลเรื่อง lifetime ของ owner ตัวเดิม อีกทั้ง Rc จะปลดปล่อยหน่วยความจำให้โดยอัตโนมัติเมื่อไม่มี reference ใดเหลืออยู่ ซึ่งช่วยลดความยุ่งยากในการจัดการหน่วยความจำด้วยตัวเอง ทำให้เหมาะกับสถานการณ์ที่ต้องการแชร์ข้อมูล immutable ระหว่างหลายส่วนของโปรแกรมอย่างปลอดภัยและมีประสิทธิภาพมากขึ้น
พูดง่ายๆ ก็คือ ค่าใน Rc จะยังคงมีชีวิตอยู่บน heap ตราบใดที่ยังมี reference (หรือ owner) ที่ชี้ไปยังมันอยู่ เมื่อ reference สุดท้ายถูก drop (หรือ “ตาย”) หน่วยความจำที่จัดเก็บค่านั้นจะถูกปลดปล่อยทันทีโดยอัตโนมัติ ระบบนี้ทำให้ Rc เป็นตัวเลือกที่ดีในสถานการณ์ที่เราต้องการแชร์ข้อมูลเดียวกันระหว่างหลายจุดในโปรแกรม โดยไม่ต้องกังวลว่าค่านั้นจะถูกลบก่อนที่ทุก reference จะเลิกใช้งานไปพร้อมกัน นั่นแหละข้อดีของ reference counting
รวมถึงสิ่งที่ต้องระวังในการใช้ Rc<T>
- ไม่เหมาะกับ multi-threading: หากต้องแชร์ข้อมูลระหว่าง thread ให้ใช้
Arc<T>(Atomic Reference Counted) (เดี๋ยวเราจะอธิบายในหัวข้อ thread อีกที) - Circular reference: ระวังการสร้างวงจรอ้างอิง (circular reference) ที่จะทำให้หน่วยความจำไม่ถูกปลดปล่อย เช่น กรณี Graph หรือ Tree ที่มีการอ้างกลับไปมา ควรใช้
Weak<T>ร่วมด้วยเพื่อลดปัญหานี้
RefCell
RefCell<T> เป็น smart pointer ที่ช่วยให้สามารถทำ interior mutability ได้ หรือพูดง่ายๆ คือ ช่วยให้เราสามารถเปลี่ยนแปลงค่าภายในได้ แม้ว่า RefCell<T> จะอยู่ในบริบทที่เป็น immutable ก็ตาม ทั้งนี้ การเปลี่ยนแปลงค่าดังกล่าวจะถูกตรวจสอบใน runtime ไม่ใช่ compile-time (เหมือน Box<T> หรือ Rc<T>)
คุณสมบัติเด่นของ RefCell<T>
- Interior Mutability: สามารถเปลี่ยนค่าภายใน
RefCell<T>ได้ แม้ตัวแปรนั้นจะเป็น immutable - Borrow Checking ใน Runtime: ระบบจะตรวจสอบกฎ borrow ที่ runtime โดย
- เราสามารถ borrow ค่าแบบ immutable (
borrow()) ได้หลายครั้ง - แต่สามารถ borrow ค่าแบบ mutable (
borrow_mut()) ได้เพียงครั้งเดียว
- เราสามารถ borrow ค่าแบบ immutable (
- เหมาะกับโครงสร้างข้อมูลที่ต้องการแชร์หรือเปลี่ยนค่าในสถานการณ์ที่ปกติไม่ได้รับอนุญาต เช่น
Rc<RefCell<T>>
ตัวอย่างการใช้งานอย่างง่าย
use std::cell::RefCell;
fn main() { let data = RefCell::new(5); // สร้าง RefCell ที่เก็บค่า 5
// Borrow ค่าแบบ immutable println!("ค่าเริ่มต้น: {}", *data.borrow());
// Borrow ค่าแบบ mutable และเปลี่ยนค่า *data.borrow_mut() = 10;
// แสดงค่าหลังเปลี่ยน println!("ค่าหลังเปลี่ยน: {}", *data.borrow());}ผลลัพธ์
ค่าเริ่มต้น: 5ค่าหลังเปลี่ยน: 10ต่อมา ดูตัวอย่างการใช้งานร่วมกับ Rc<T> บ้าง สำหรับแชร์ค่าที่เปลี่ยนแปลงได้
use std::rc::Rc;use std::cell::RefCell;
fn main() { let shared_data = Rc::new(RefCell::new(10)); // สร้าง Rc + RefCell
let data_clone1 = Rc::clone(&shared_data); // Clone reference ที่ 1 let data_clone2 = Rc::clone(&shared_data); // Clone reference ที่ 2
// เปลี่ยนค่าผ่าน clone แรก *data_clone1.borrow_mut() += 5;
// อ่านค่าผ่าน clone ที่สอง println!("ค่าปัจจุบัน: {}", *data_clone1.borrow()); println!("ค่าปัจจุบัน: {}", *data_clone2.borrow());}ผลลัพธ์
ค่าปัจจุบัน: 15ค่าปัจจุบัน: 15สังเกตว่า
- RefCell ถูกสร้างขึ้นมาเสร็จแล้วถูกห่อด้วย Rc เพื่อทำการส่งต่อ reference ไปให้กับตัวอื่นๆ
- เมื่อตัวใดตัวหนึ่งมีการ
borrow_mut()ไปเปลี่ยนค่า ตัวที่ reference อยู่ทั้งหมดก็จะโดนเปลี่ยนตาม
คำถามเช่นเดิม “เมื่อไหร่ควรใช้ RefCell<T> ?”
- เมื่อเราต้องการเปลี่ยนค่าภายในโครงสร้างข้อมูลที่ immutable
- เมื่อใช้งานร่วมกับ smart pointer อื่นๆ เช่น
Rc<T>เพื่อแชร์ข้อมูลที่ต้องการเปลี่ยนแปลง - เมื่อต้องการหลีกเลี่ยงข้อจำกัดของ borrow checker ที่ compile-time แต่ยังต้องการความปลอดภัยใน runtime
ข้อควรระวัง
- Borrow Mutations ใน Runtime: หากมีการ borrow mutable พร้อมกับ borrow immutable ในเวลาเดียวกัน จะเกิด panic ใน runtime
- ค่า Overhead ใน Runtime: การตรวจสอบ borrow เกิดขึ้นใน runtime ซึ่งอาจมี overhead ในบางกรณี
- ไม่เหมาะกับ multi-threading: หากต้องการแชร์ใน multi-thread ให้ใช้
Mutex<T>หรือRwLock<T>แทน (เดี๋ยวอธิบายในเรื่อง Thread เพิ่มเติม)
Weak
Weak<T> ใน Rust เป็น smart pointer ที่ใช้งานร่วมกับ Rc<T> เพื่อป้องกันปัญหา วงจรอ้างอิง (cyclic reference) ซึ่งอาจทำให้หน่วยความจำไม่ถูกปลดปล่อย (memory leak) โดย Weak<T> จะสร้าง reference ไปยังค่าใน Rc<T> โดยไม่เพิ่ม reference count (strong count) ของค่าใน Rc<T> นั่นเอง
คุณสมบัติเด่นๆของ Weak<T>
- ไม่มี Strong Ownership:
Weak<T>ไม่ได้เป็น owner ของค่า แต่สามารถอ้างอิงถึงค่าในRc<T>ได้ - ไม่เพิ่ม Strong Count: การใช้
Weak<T>ไม่เพิ่มจำนวน reference count ของRc<T>ช่วยป้องกันปัญหา cyclic reference - Upgrade: สามารถอัปเกรด
Weak<T>เป็นRc<T>ด้วยวิธี.upgrade()เพื่อใช้งานค่าที่ชี้ไป หากค่าถูกปลดปล่อยไปแล้ว.upgrade()จะคืนค่าNone
ตัวอย่าง เคสที่เราไม่ได้ใช้ Weak ของกรณีที่มี linked list ชี้ไปยัง next และ prev
use std::rc::Rc;use std::cell::RefCell;
struct Node { value: i32, next: Option<Rc<RefCell<Node>>>, prev: Option<Rc<RefCell<Node>>>,}
fn main() { let node1 = Rc::new(RefCell::new(Node { value: 1, next: None, prev: None })); let node2 = Rc::new(RefCell::new(Node { value: 2, next: None, prev: None }));
// สร้าง reference cycle: node1 -> node2 -> node1 node1.borrow_mut().next = Some(Rc::clone(&node2)); node2.borrow_mut().prev = Some(Rc::clone(&node1));
// Node ทั้งสองตัวไม่มีทางถูก drop เพราะ reference count ไม่เคยลดลงเป็น 0 println!("Node1 strong count: {}", Rc::strong_count(&node1)); // 2 println!("Node2 strong count: {}", Rc::strong_count(&node2)); // 2}ปัญหาของ code นี้คือ
node1และnode2อ้างอิงซึ่งกันและกัน ทำให้ reference count ของทั้งสองตัวไม่ลดลงถึง 0 = ทำให้เกิดปัญหา Memory Leak ได้- ก็จะส่งผลทำให้แม้ว่าจะออกจาก
main()หน่วยความจำของnode1และnode2จะยังคงถูกครอบครอง เนื่องจาก reference count ยังไม่เป็น 0 จึงทำให้ไม่เกิดการ free memory เกิดขึ้น
วิธีแก้ปัญหาด้วย Weak<T>
use std::rc::{Rc, Weak};use std::cell::RefCell;
struct Node { value: i32, next: Option<Rc<RefCell<Node>>>, prev: Option<Weak<RefCell<Node>>>,}
fn main() { let node1 = Rc::new(RefCell::new(Node { value: 1, next: None, prev: None })); let node2 = Rc::new(RefCell::new(Node { value: 2, next: None, prev: None }));
// สร้างความสัมพันธ์ระหว่าง node: node1 -> node2 node1.borrow_mut().next = Some(Rc::clone(&node2)); node2.borrow_mut().prev = Some(Rc::downgrade(&node1));
// ตรวจสอบ reference count println!("Node1 strong count: {}", Rc::strong_count(&node1)); // 1 println!("Node2 strong count: {}", Rc::strong_count(&node2)); // 2 println!("Node1 weak count: {}", Rc::weak_count(&node1)); // 1}Note
- เปลี่ยน type ของ prev เป็น
Option<Weak<RefCell<Node>>> - ใช้
Rc::downgrade()แทนRc::clone()เมื่อต้องการสร้าง weak reference
ตัวอย่างเพิ่มเติมเรื่องคำสั่ง upgrade()
use std::rc::{Rc, Weak};use std::cell::RefCell;
struct Node { value: i32, parent: RefCell<Weak<Node>>, // Weak reference ไปยัง Node แม่ children: RefCell<Vec<Rc<Node>>>, // Strong reference ไปยัง Node ลูก}
fn main() { let parent = Rc::new(Node { value: 1, parent: RefCell::new(Weak::new()), // ไม่มี Node แม่ children: RefCell::new(Vec::new()), });
let child = Rc::new(Node { value: 2, parent: RefCell::new(Rc::downgrade(&parent)), // Weak reference ไปยัง Node แม่ children: RefCell::new(Vec::new()), });
parent.children.borrow_mut().push(Rc::clone(&child)); // เพิ่ม Node ลูกเข้าไปใน Node แม่
// แสดงค่าของ Node แม่และ Node ลูก println!("Parent value: {}", parent.value); println!( "Child value: {}, Parent of child: {:?}", child.value, child.parent.borrow().upgrade().map(|p| p.value) // อัปเกรด Weak เป็น Rc );}ผลลัพธ์
Parent value: 1Child value: 2, Parent of child: Some(1)ในตัวอย่างนี้
parentใช้Weak<T>สำหรับอ้างอิง Node แม่ในchildเพื่อหลีกเลี่ยงวงจรอ้างอิง- การใช้
.upgrade()กับWeak<T>จะคืนค่าSome(Rc<Node>)หาก Node แม่ยังมีชีวิตอยู่ และNoneหากถูก drop ไปแล้ว
ข้อดีของ Weak<T>
- ป้องกันปัญหา cyclic reference ที่อาจเกิดกับ
Rc<T> - ลด overhead ในการจัดการ reference count
ข้อควรระวัง
- การใช้
.upgrade()กับWeak<T>ที่อ้างถึงค่าที่ถูก drop แล้วจะคืนค่าNone - ใช้เฉพาะในสถานการณ์ที่ต้องการอ้างอิงชั่วคราวหรือหลีกเลี่ยง cyclic reference
โดยปกติ Weak<T> จะเหมาะสำหรับโครงสร้างข้อมูลแบบกราฟหรือ tree ที่มีความสัมพันธ์ซับซ้อน เช่น parent-child และช่วยให้การจัดการหน่วยความจำปลอดภัยยิ่งขึ้นได้
Lifetime
Lifetime คือแนวคิดที่ใช้สำหรับจัดการอายุการใช้งานของข้อมูล (หรือ reference) เพื่อให้มั่นใจว่า reference ที่ใช้งานใน code จะ ปลอดภัย และไม่มีการอ้างถึงข้อมูลที่หมดอายุ (dangling reference) โดย Rust ใช้ borrow checker เพื่อตรวจสอบและบังคับใช้นโยบายเกี่ยวกับ Lifetime ระหว่างการ compile
คำถามคือ “ทำไม Rust ต้องมี Lifetime?” อย่างที่เราทราบกันว่า ใน Rust การจัดการหน่วยความจำนั้น ปราศจาก garbage collector และขึ้นอยู่กับ ownership และ borrowing
- Borrowing: เราสามารถยืม reference แบบ immutable หรือ mutable ได้
- หาก reference หนึ่งชี้ไปยังข้อมูลที่ถูกปลดปล่อย (dropped) จะเกิดข้อผิดพลาด เช่น dangling reference ขึ้นมาได้
Lifetime จึงถูกใช้เพื่อบอกว่า reference ใดสามารถใช้งานได้ในช่วงเวลาไหน และ Rust จะตรวจสอบว่า reference มีอายุการใช้งานที่สอดคล้องกับข้อมูลที่มันชี้ไปหรือไม่ออกมาได้
ตัวอย่างง่ายๆเช่น
fn main() { let x = 10; let r = &x; // r ยืม reference ของ x
println!("ค่า r: {}", r); // r ใช้ได้ตราบใดที่ x ยังมีชีวิต} // x และ r หมดอายุพร้อมกัน- ในระบบ Lifetime ของ Rust ก็จะส่งผลทำให้ x, r หมดอายุพร้อมกันได้
Custom Lifetime
Custom Lifetime เป็น concept ที่สำคัญในการจัดการหน่วยความจำและการอ้างอิงข้อมูล โดยมีวัตถุประสงค์หลักเพื่อให้ compiler ตรวจสอบความปลอดภัยของการใช้งานการอ้างอิง (references) ใน code
Rust ใช้ lifetime เพื่อประกันว่าการอ้างอิงจะไม่ชี้ไปยังข้อมูลที่ถูกทำลายไปแล้ว รวมถึง ช่วยป้องกันปัญหาการเข้าถึงหน่วยความจำที่ไม่ถูกต้อง (memory safety) ด้วยเช่นกัน
ตัวอย่าง code
// function ที่ใช้ Custom Lifetimefn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y }}
fn main() { // ตัวแปรสตริง let string1 = String::from("short"); let string2 = String::from("longer string");
// เรียกใช้ function longest let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is: {}", result);
// ตัวอย่างการใช้ Custom Lifetime กับตัวแปรที่มีอายุการใช้งานต่างกัน let string3 = String::from("hello"); { let string4 = String::from("world"); let longest_string = longest(string3.as_str(), string4.as_str()); println!("Longest string in inner scope: {}", longest_string); }}Note
- จาก code นี้ใช้ lifetime parameter
'aเพื่อบอก compiler ว่าการอ้างอิงทั้งสองมีอายุการใช้งานเท่ากัน - คืนค่าเป็น reference ที่มี lifetime เดียวกับ input
เพื่อความเข้าใจที่เพิ่มขึ้น เราจะมาทำความรู้จักกับ 'a กัน
'a เป็น Lifetime Parameter ที่มีความสำคัญ โดยเป็นสัญลักษณ์ที่ใช้ระบุอายุการใช้งานของการอ้างอิง (reference) เพื่อใช้บอก compiler ว่าการอ้างอิงนั้นๆ จะมีชีวิตอยู่นานเท่าไหร่ โดยสามารถใช้ได้กับทั้ง Function, Return values, Struct, Trait
- จริงๆแล้ว สามารถตั้งชื่ออื่นได้ แต่โดยทั่วไปจะนิยมใช้ตัวอักษรอังกฤษพิมพ์เล็กเรียงไปเลย เช่นใช้
'a,'b,'c - รวมถึง สามารถใช้มากกว่าหนึ่ง lifetime parameter ได้ ในกรณีที่ lifetime ของ parameter อาจจะไม่เท่ากัน
ดังเช่นตัวอย่างนี้
// function ที่ใช้สอง lifetime parameterfn longest_and_first<'a, 'b>(x: &'a str, y: &'b str) -> &'a str { println!("Second string: {}", y); x // คืนค่าเป็น reference จาก x เท่านั้น}
// Struct ที่มีหลาย lifetime parameterstruct Excerpt<'a, 'b> { part1: &'a str, part2: &'b str, length: usize}
fn main() { let string1 = String::from("Hello"); let string2 = String::from("World");
// เรียกใช้ function ที่มีสอง lifetime parameter let result = longest_and_first(&string1, &string2); println!("Longest: {}", result);
// สร้าง struct ที่มีสอง lifetime parameter let excerpt = Excerpt { part1: &string1, part2: &string2, length: string1.len() + string2.len() };
println!("Part1: {}, Part2: {}", excerpt.part1, excerpt.part2);}Note
- function
longest_and_firstมี 2 lifetime parameter: ‘a และ ‘b - Struct
Excerptมี 2 lifetime parameter เช่นกัน
การมี lifetime parameter สองอันมีประโยชน์อย่างมากในสถานการณ์ที่ต้องจัดการกับการอ้างอิงที่มีอายุการใช้งานแตกต่างกันหรือต้องการควบคุมการเข้าถึงข้อมูล เช่น
- การจัดการความสัมพันธ์ระหว่างข้อมูลในระบบฐานข้อมูล ที่ซึ่งคุณต้องเก็บการอ้างอิงระหว่าง record หลักและ record ย่อยที่มีวงจรชีวิตไม่เหมือนกัน
- ในการสร้างโครงสร้างข้อมูลที่ซับซ้อน เช่น linked list หรือ tree การใช้พารามิเตอร์ lifetime สองตัวช่วยให้เราจัดการความสัมพันธ์ระหว่างโหนดต่างๆ ได้อย่างมีประสิทธิภาพมากขึ้นได้
Lifetime elision rules
ที่นี่บางคนก็อาจจะสงสัยเล็กน้อย “แล้วถ้าไม่กำหนด lifetime parameter เลยใน code compiler จะจัดการเรื่องนี้อย่างไร ?”
ใน Rust หากเราไม่กำหนด lifetime parameter เองใน code คอมไพเลอร์ Rust จะพยายามใช้สิ่งที่เรียกว่า lifetime elision rules เพื่ออนุมาน lifetimes ให้เราโดยอัตโนมัติ กฎเหล่านี้เป็นชุดของ heuristic ที่ค่อนข้างง่าย ซึ่งครอบคลุมกรณีการใช้งานทั่วไปส่วนใหญ่ ทำให้เราเขียน code ได้กระชับยิ่งขึ้น โดยไม่ต้องระบุ lifetimes อย่างชัดเจนทุกครั้ง
กฎ lifetime elision มีดังนี้
- Each parameter that is a reference gets its own lifetime parameter = parameter แต่ละตัวที่เป็น reference จะได้รับ lifetime parameter ของตัวเอง
- If there is exactly one input lifetime parameter, that lifetime is assigned to all output lifetime parameters = ถ้ามี input lifetime parameter เพียงตัวเดียว lifetime นั้นจะถูกกำหนดให้กับ output lifetime parameter ทั้งหมด
- If there are multiple input lifetime parameters, but one of them is
&selfor&mut self, the lifetime ofselfis assigned to all output lifetime parameters = ถ้ามี input lifetime parameter หลายตัว แต่มีหนึ่งในนั้นคือ&selfหรือ&mut selflifetime ของselfจะถูกกำหนดให้กับ output lifetime parameter ทั้งหมด
เรามาลองดูแต่ละตัวอย่างเพิ่มเติมกัน
ตัวอย่าง 1: function ที่มี reference เพียงตัวเดียว
fn print_string(s: &str) { println!("{}", s);}ในตัวอย่างนี้ เราไม่ได้กำหนด lifetime parameter ใดๆ แต่ compiler จะอนุมานให้เราโดยอัตโนมัติ ตามกฎข้อ 1
s: &strกลายเป็นs: &'a strโดยที่'aเป็น lifetime ใหม่ที่คอมไพเลอร์สร้างขึ้น
ตัวอย่าง 2: function ที่รับ reference สองตัวและคืนค่า reference
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y }}ในตัวอย่างนี้ เราได้กำหนด lifetime parameter 'a อย่างชัดเจน เนื่องจากเราต้องการบอก compiler ว่า lifetime ของ input (x และ y) และ output ต้องสัมพันธ์กัน (output ต้องมีชีวิตอยู่ตราบเท่า input ตัวใดตัวหนึ่ง) ถ้าเราไม่กำหนด compilerจะไม่สามารถรู้ได้ว่าจะเลือก lifetime ใด
เช่น ถ้าเราพยายามเขียนแบบนี้โดยไม่ใส่ lifetime
fn longest(x: &str, y: &str) -> &str { // error[E0106]: missing lifetime specifier // ...}compiler จะแจ้ง error E0106: missing lifetime specifier เพราะไม่สามารถอนุมาน lifetime ได้ เนื่องจากมี input lifetime มากกว่าหนึ่งตัว และไม่มี self
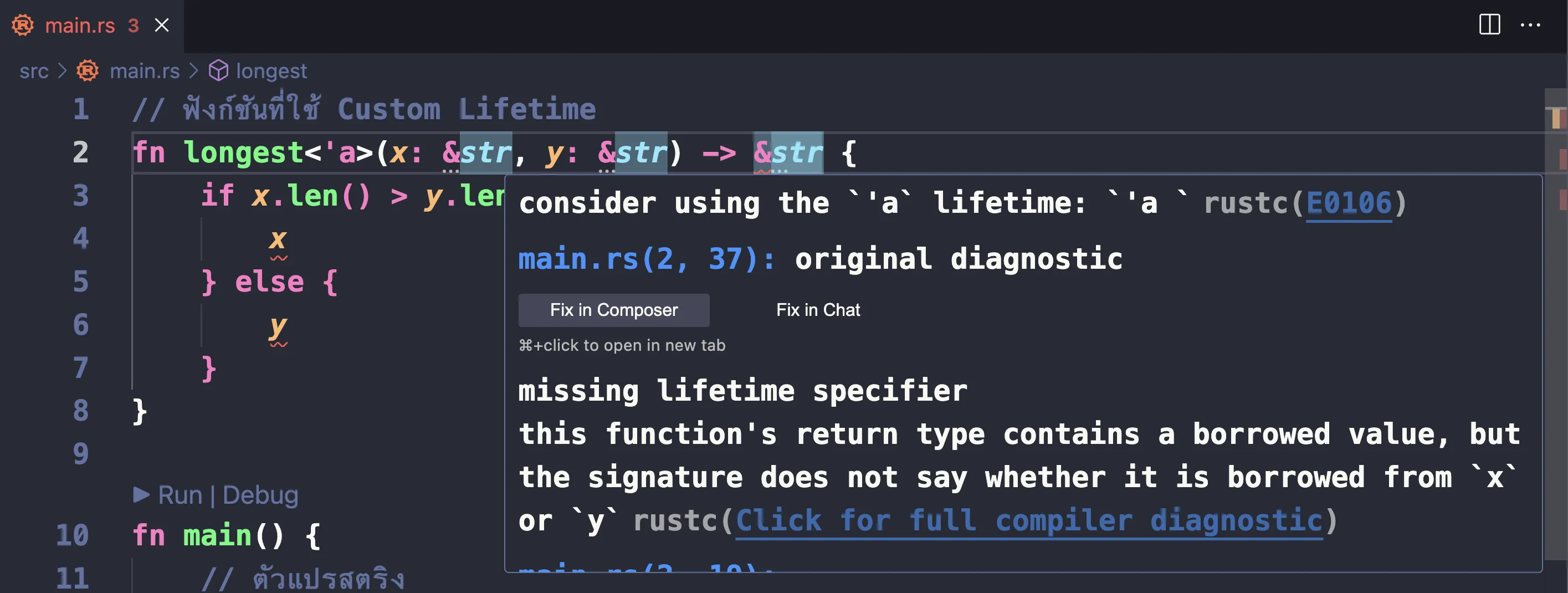
ตัวอย่าง 3: Method ที่มี self
struct ImportantExcerpt<'a>(&'a str);
impl<'a> ImportantExcerpt<'a> { fn level(&self, announcement: &str) -> &str { // lifetime elided // ... }}ตามกฎข้อ 3 compiler จะอนุมาน lifetime ของ output เป็น lifetime ของ self นั่นคือ 'a ดังนั้นจริงๆ แล้ว method นี้มีความหมายเหมือนกับ code ชุดด้านล่างนี้
fn level<'a>(&'a self, announcement: &str) -> &'a str { // ...}ดังนั้น กฎ lifetime elision ช่วยลด boilerplate และทำให้ code อ่านง่ายขึ้นในกรณีส่วนใหญ่ แต่อย่างไรก็ตาม เมื่อกฎเหล่านี้ไม่เพียงพอ เช่น เมื่อมีความสัมพันธ์ที่ซับซ้อนระหว่าง lifetimes ของ input และ output เราจำเป็นต้องกำหนด lifetime parameter อย่างชัดเจน เพื่อให้ compiler เข้าใจความตั้งใจของเราและตรวจสอบความถูกต้องของ code ได้ (ซึ่งเอาจริงๆ compiler ก็จะบังคับให้เราเติมให้ครบอยู่ดี ตาม error ที่เราเห็นด้านบน)
Static Lifetime
นอกจากนี้ ยังมีเรื่อง Static Lifetime ที่เป็น lifetime ที่พิเศษที่สุด หมายถึง ข้อมูลนั้นมีชีวิตอยู่ “ตลอดระยะเวลา” ของโปรแกรม หรือตั้งแต่โปรแกรมเริ่มต้นจนกระทั่งสิ้นสุดลง
เราสามารถระบุ static lifetime ได้โดยใช้ 'static เช่น &'static str หรือ &'static i32 การอ้างอิงที่มี static lifetime นั้นรับประกันได้ว่าจะสามารถเข้าถึงได้ตลอดเวลา ทำให้มั่นใจได้ว่าไม่มีปัญหา dangling pointer หรือการเข้าถึงหน่วยความจำที่ถูก deallocate ไปแล้ว
จุดเด่นๆของ Static Lifetime
- มีชีวิตอยู่ตลอดโปรแกรม: ข้อมูลที่มี static lifetime จะถูกเก็บไว้ในส่วนของข้อมูลของโปรแกรม (data segment) ซึ่งจะโหลดเข้าสู่หน่วยความจำเมื่อโปรแกรมเริ่มต้น และจะคงอยู่จนกระทั่งโปรแกรมสิ้นสุด
- ใช้กับ string literals: string literals ใน Rust เช่น
"Hello, world!"มี static lifetime โดยอัตโนมัติ นั่นเป็นเพราะว่า string literals ถูกเก็บไว้ในส่วนของข้อมูลของโปรแกรม - ใช้กับ global constants: ค่าคงที่ global ที่ประกาศด้วย
staticจะมี static lifetime เช่นกัน - ใช้กับข้อมูลที่ถูก embed ใน binary: ข้อมูลที่ถูก compile เข้าไปใน binary ของโปรแกรม เช่น รูปภาพหรือข้อมูล configuration บางอย่าง มักจะมี static lifetime ไปด้วยเลย
ตัวอย่าง code
// String literal มี static lifetime โดยอัตโนมัติlet s: &'static str = "Hello, world!";
// การประกาศค่าคงที่แบบ staticstatic GLOBAL_CONSTANT: i32 = 10;
fn main() { println!("{}", s); println!("{}", GLOBAL_CONSTANT);
// ตัวอย่างการใช้ static lifetime กับ closure (ต้องระวัง) let static_closure = || { println!("This is a static closure"); }; static_closure();}เมื่อไหร่ที่ควรใช้ Static Lifetime
- String literals: ใช้กับ string literals ได้โดยตรง
- ค่าคงที่ global: ใช้กับค่าคงที่ที่ต้องการให้เข้าถึงได้จากทุกส่วนของโปรแกรม
- ข้อมูลที่ embed ใน binary: ใช้กับข้อมูลที่ถูกฝังอยู่ในโปรแกรม เช่น ข้อมูล configuration หรือ asset ต่างๆ
แต่ก็จะมีจุดที่ควรระวังคือ
- การใช้งานมากเกินไปอาจทำให้เกิด memory leak: เนื่องจากข้อมูลที่มี static lifetime จะไม่ถูก deallocate จนกว่าโปรแกรมจะสิ้นสุด การใช้งาน static lifetime กับข้อมูลที่ไม่จำเป็นต้องมีชีวิตอยู่ตลอดโปรแกรม อาจทำให้เกิด memory leak ได้
- ไม่สามารถใช้กับข้อมูลที่สร้างขึ้นแบบ runtime ได้: ข้อมูลที่ถูกสร้างขึ้นในขณะ runtime เช่น ข้อมูลที่อ่านจากไฟล์ หรือข้อมูลที่ได้รับจากผู้ใช้ ไม่สามารถมี static lifetime ได้โดยตรง เพราะ static lifetime หมายถึงข้อมูลที่ถูกกำหนดไว้ตั้งแต่ compile time
- การใช้
&'staticกับข้อมูลที่ไม่ static ต้องใช้Box::leak(ควรหลีกเลี่ยง): ถ้าต้องการบังคับให้ข้อมูลที่ไม่ static มี static lifetime จะต้องใช้Box::leakซึ่งจะทำให้หน่วยความจำของข้อมูลนั้นรั่วไหล (leak) และไม่ควรใช้วิธีนี้หากไม่จำเป็นจริงๆ เช่น
let s = "Hello".to_string();let leaked_string: &'static str = Box::leak(s.into_boxed_str()); // หลีกเลี่ยงถ้าไม่จำเป็นStatic lifetime ควรใช้อย่างระมัดระวังและเฉพาะเมื่อจำเป็นจริงๆ เท่านั้น โดยทั่วไปแล้ว ควรหลีกเลี่ยงการใช้ static lifetime กับข้อมูลที่ถูกสร้างขึ้นในขณะ runtime หรือข้อมูลที่มีอายุการใช้งานจำกัด เพราะอาจนำไปสู่ปัญหา memory leak ได้ การใช้งานที่เหมาะสมคือเมื่อต้องการข้อมูลที่คงอยู่ตลอดระยะเวลาของโปรแกรม เช่น string literals, global constants, ข้อมูล configuration ที่ฝังอยู่ใน binary หรือข้อมูลที่จำเป็นต้องเข้าถึงจากทุกส่วนของโปรแกรม หากไม่แน่ใจว่าข้อมูลจำเป็นต้องมีชีวิตอยู่นานขนาดนั้นหรือไม่ ควรพิจารณา lifetimes อื่นๆ หรือ ownership system ของ Rust เพื่อจัดการหน่วยความจำอย่างมีประสิทธิภาพมากกว่า การพยายามบังคับให้ข้อมูลมี static lifetime ด้วย Box::leak ควรเป็นทางเลือกสุดท้ายและควรหลีกเลี่ยงหากทำได้ เนื่องจากวิธีนี้จะทำให้เกิด memory leak อย่างแน่นอน
Concurrency
https://doc.rust-lang.org/book/ch16-00-concurrency.html
Concurrency หมายถึงความสามารถในการเขียนโปรแกรมที่สามารถดำเนินงานหลายส่วนได้ในเวลาเดียวกัน ซึ่ง Rust ให้ความสำคัญกับ ความปลอดภัย และ ประสิทธิภาพ ผ่านระบบ ownership, type system, และ compile-time checks เพื่อป้องกันปัญหาที่มักเกิดขึ้นในโปรแกรม concurrent เช่น data races, deadlocks, และ dangling pointers โดยไม่ต้องพึ่งพา garbage collector
Ref: https://unicminds.com/program-vs-process-vs-thread/
โดย Rust มีเครื่องมือหลายอย่างสำหรับการจัดการ concurrency ให้ปลอดภัยได้ ตั้งแต่
- Threads: Rust ใช้ OS threads เพื่อรันงานหลายอย่างพร้อมกัน โดยการสร้าง threads ใน Rust ผ่านการใช้
std::thread::spawn(และ Ownership ของข้อมูลก็ยังคงถูกควบคุมอย่างเข้มงวดเพื่อป้องกันปัญหาด้าน memory safety ด้วยเช่นกัน) - Message Passing: Rust สนับสนุนแนวคิด message passing โดยใช้ channels (
std::sync::mpsc) เพื่อส่งข้อความระหว่าง threads ได้ - Shared State (Mutex & Arc): การแชร์ state ระหว่าง threads อย่างปลอดภัยผ่าน
Mutex<T>(เพื่อป้องกันการแก้ไขข้อมูลพร้อมกัน) หรือArc<T>(สำหรับแชร์ ownership ของข้อมูลระหว่าง threads แบบ immutable)
ซึ่งนอกเหนือจาก concurrency แบบ threads แบบดั้งเดิม Rust ยังรองรับ asynchronous programming อีกด้วย
Asynchronous Programming คือการเขียนโปรแกรมที่ช่วยให้การดำเนินงานบางส่วนของโปรแกรมสามารถ รอ หรือ พักการทำงาน (await) โดยไม่ต้องบล็อกการทำงานของส่วนอื่น ๆ ของโปรแกรม เพื่อใช้ทรัพยากรของระบบให้มีประสิทธิภาพสูงสุด โดยเฉพาะในงานที่เกี่ยวข้องกับ I/O เช่น การอ่านเขียนไฟล์, การส่งรับข้อมูลจากเครือข่าย หรือการทำงานแบบ concurrent
โดย Rust รองรับ asynchronous programming ผ่าน async/await syntax และ future-based system ที่ช่วยให้การจัดการ concurrency แบบ non-blocking ง่ายขึ้นด้วยเช่นกัน (เดี๋ยวเราจะกลับมาอธิบายเพิ่มเติมใน asynchronous อีกที)
ซึ่งนั่นเท่ากับว่า Rust support การเขียนโปรแกรม concurrency ทั้งในรูปแบบ Thread และ Asynchronous ที่ถือว่าครอบคลุม และยืดหยุ่นต่อการใช้งานในหลากหลายบริบทด้วยเช่นกัน เราจะค่อยๆมาเรียนรู้ผ่านแต่ละคำสั่งในการจัดการ Concurrency กัน
การสร้าง Thread เบื้องต้น
การสร้าง Thread สามารถทำได้ด้วย function std::thread::spawn ซึ่งเป็นวิธีพื้นฐานสำหรับการทำงานแบบ concurrent โดยแต่ละ thread จะทำงานแยกจาก thread หลัก (main thread)
code ตัวอย่าง
use std::thread;
fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("Thread: {}", i); } });
for i in 1..5 { println!("Main: {}", i); }
handle.join().unwrap(); // รอให้ thread ทำงานเสร็จก่อนโปรแกรมจบ}ผลลัพธ์
Main: 1Main: 2Main: 3Main: 4Thread: 1Thread: 2Thread: 3Thread: 4Thread: 5Thread: 6Thread: 7Thread: 8Thread: 9Note
- ใช้ function
thread::spawnเพื่อสร้าง thread ใหม่ โดย code ภายในthread::spawnจะถูกเรียกใน thread ใหม่ขึ้นมา
ขออธิบายบรรทัด handle.join().unwrap() เพิ่ม
handle.join().unwrap() เป็นคำสั่งที่ใช้ในภาษา Rust กับ thread เพื่อรอให้ thread นั้นทำงานเสร็จสิ้น และรับค่าที่ thread ส่งกลับมา โดย
- เมื่อเราสร้าง thread ด้วย
thread::spawn()function นี้จะส่งกลับค่าJoinHandleซึ่งเรามักจะเก็บไว้ในตัวแปร เช่นhandleตัวJoinHandleนี้เป็นตัวแทนของ thread ที่สร้างขึ้น และใช้สำหรับจัดการ thread นั้น เช่น รอให้มันเสร็จสิ้น - method
join()บนJoinHandleมีหน้าที่หลักคือรอให้ thread ที่เกี่ยวข้องทำงานเสร็จสิ้น เมื่อเรียกhandle.join()thread ปัจจุบัน (thread ที่เรียกjoin()) จะหยุดรอจนกว่า thread ที่handleอ้างถึงจะทำงานเสร็จสิ้น - สุดท้าย
join()ส่งกลับค่าResult<T, E>ซึ่งTคือค่าที่ thread ส่งกลับ (ถ้ามี) และEคือ error ที่อาจเกิดขึ้นระหว่างการ join (เช่น thread panic)unwrap()เป็นวิธีในการจัดการกับResult - ส่วน
unwrap()นั้นสามารถใช้งานเพื่อแกะค่าResultออกมาได้ แต่ควรใช้ด้วยความระมัดระวัง เพราะถ้า thread panic โปรแกรมจะหยุดทำงานทันที
ใน production code ควรใช้การจัดการ error ที่ดีกว่า เช่น การใช้ match ลักษณะนี้ (โดย handle จากตัว Result ที่คืนมา)
use std::thread;
fn main() { let handle = thread::spawn(|| { // code ที่ thread จะทำ println!("Hello from spawned thread!"); "This is the result from the thread" // ค่าที่ส่งกลับจาก thread });
let result = handle.join().unwrap(); // รอให้ thread เสร็จสิ้น และรับค่าที่ส่งกลับ println!("Thread finished with result: {}", result);
let handle_panic = thread::spawn(|| { panic!("Something went wrong"); });
let result_panic = handle_panic.join();
match result_panic { Ok(_) => println!("Thread finished successfully"), Err(e) => println!("Thread panicked: {:?}", e), }}คำถามต่อมา “แล้วถ้าจะส่งค่าตัวแปรจากภายนอกไปใช้ใน Thread ละทำได้อย่างไร” = คำตอบคือ ต้องทำการย้าย ownership ผ่าน move closure เข้าไปนั่นเอง
move closure คือ closure ที่ ย้าย ownership ของตัวแปรที่มัน capture มายังตัวมันเอง แทนที่จะ ยืม การใช้งาน move closure มีประโยชน์อย่างมากเมื่อคุณต้องการส่ง closure ไปยัง thread อื่น เพราะ thread อื่นนั้นมี stack และ lifetime ที่แยกจาก thread ปัจจุบัน การย้าย ownership จึงเป็นการรับประกันว่าข้อมูลที่ closure ต้องการใช้งานนั้นยังคงมีอยู่และ valid ใน thread ใหม่
คำถามคือ “ทำไมต้อง move closure เมื่อส่งไปยัง Thread?”
โดยทั่วไปแล้ว closure ใน Rust จะ ยืม ค่าจาก scope ที่มันถูกสร้างขึ้นมา ซึ่งหมายความว่า closure จะเก็บการอ้างอิง (reference) ไปยังตัวแปรเหล่านั้น ปัญหาคือเมื่อเราส่ง closure ไปยัง thread อื่น thread นั้นอาจมีอายุการใช้งานที่แตกต่างจาก thread ปัจจุบัน ตัวแปรที่ closure ยืมมาอาจถูก drop ไปแล้วใน thread เดิม ทำให้เกิด dangling reference ใน thread ใหม่
move closure แก้ปัญหานี้โดยการ ย้าย ownership ของตัวแปรที่ capture มายังตัว closure เอง ทำให้ closure เป็นเจ้าของข้อมูลนั้นโดยสมบูรณ์ ไม่มีการอ้างอิงใดๆ ที่อาจกลายเป็น dangling reference อีกต่อไป
เช่น code ตัวอย่างนี้ เป็นการส่ง move closure ไปยัง thread ทำได้ง่ายๆ โดยใช้ std::thread::spawn
use std::thread;
fn main() { let name = String::from("Rust");
thread::spawn(move || { println!("Hello, {} from a thread!", name); }).join().unwrap();
// println!("Name: {}", name); // error: value borrowed here after move}ในตัวอย่างนี้ name ถูกย้ายไปยัง closure ที่ถูกส่งไปยัง thread ใหม่ ด้วย move || ทำให้ thread ใหม่เป็นเจ้าของ name และสามารถใช้งานได้โดยไม่มีปัญหาได้
Smart pointer กับ Thread
ใน Rust Smart pointer ที่ใช้ใน context ของ thread จะมีลักษณะพิเศษคือต้องรองรับการใช้งานร่วมกัน (shared ownership) และจัดการการเข้าถึงข้อมูลพร้อมกัน (concurrent access) อย่างปลอดภัย ซึ่งแตกต่างจาก smart pointer ทั่วไปที่เน้นการจัดการ ownership แบบเดี่ยว (single ownership) หรือการยืม (borrowing) เท่านั้น
Smart pointer หลักๆ ที่ใช้กับ Thread ใน Rust ได้แก่
Arc(Atomic Reference Counter) อนุญาตให้มี ownership ของข้อมูลTร่วมกันได้หลาย owner โดยใช้ atomic reference counting ในการติดตามจำนวน owner ที่ยังคงใช้งานข้อมูลอยู่ เมื่อ reference count กลายเป็น 0 ข้อมูลก็จะถูก deallocate โดยอัตโนมัติ (ใช้สำหรับเคส read only)Mutex(Mutual Exclusion) ให้การเข้าถึงข้อมูลTแบบ exclusive โดยอนุญาตให้ thread เพียง thread เดียวเข้าถึงข้อมูลได้ในเวลาใดเวลาหนึ่ง เพื่อป้องกัน data race (ใช้สำหรับเคสที่มีการแก้ข้อมูลหลาย thread และมักใช้ร่วมกับArc<T>)RwLock(Read-Write Lock) อนุญาตให้มี read access พร้อมกันได้หลาย thread แต่จำกัด write access ให้มีเพียง thread เดียวในเวลาใดเวลาหนึ่ง เหมาะสำหรับกรณีที่ read operation มีมากกว่า write operation เพื่อเพิ่มประสิทธิภาพ (มักใช้ร่วมกับArc<T>)
คำถามคือ Smart Pointer เหล่านี้ แตกต่างกับ Smart Pointer ในชุดก่อนหน้าอย่างไร คำตอบของเรื่องนี้คือ trait Send กับ Sync ซึ่งเป็น trait สำคัญใน Rust ที่เกี่ยวข้องกับการเขียนโปรแกรมแบบ concurrent หรือการทำงานแบบ multi-threaded
trait Send บ่งบอกว่า type ใด type หนึ่งนั้น ปลอดภัยที่จะส่ง ไปยัง thread อื่นได้ นั่นหมายความว่า ownership ของข้อมูลนั้นสามารถโอนย้ายจาก thread หนึ่ง ไปยังอีก thread หนึ่งได้อย่างปลอดภัย โดยไม่ก่อให้เกิด data race หรือปัญหาอื่นๆ ที่เกี่ยวกับการเข้าถึงข้อมูลพร้อมๆ กันจากหลาย threads
ส่วน trait Sync บ่งบอกว่า type ใด type หนึ่งนั้น ปลอดภัยที่จะแชร์ reference แบบ immutable ระหว่างหลาย threads นั่นหมายความว่า หลายๆ threads สามารถเข้าถึงข้อมูลพร้อมๆ กันได้ โดยที่ไม่มีการเปลี่ยนแปลงข้อมูล (immutable access)
ถ้าสรุปแบบสั้นๆคือ
Sendเกี่ยวข้องกับการ โอนย้าย ownership ระหว่าง threadsSyncเกี่ยวข้องกับการ แชร์ immutable reference ระหว่าง threads
เช่นตัวอย่างจาก Smart Pointer แบบเปรียบเทียบกัน
Arc<T>implement ทั้งSendและSyncทำให้สามารถแชร์ข้อมูลระหว่าง threads ได้อย่างปลอดภัย โดยมีการจัดการ reference count แบบ atomic เพื่อป้องกัน data raceRc<T>ไม่ implementSendและSyncทำให้ไม่สามารถแชร์ระหว่าง threads ได้อย่างปลอดภัย เนื่องจากใช้ reference count แบบ non-atomic ซึ่งอาจเกิด data race ได้ล
เราจะลองดูตัวอย่าง Smart Pointer ของแต่ละตัวที่ implement ในเรื่อง thread กัน
Arc
Arc<T> หรือ Atomic Reference Counting เป็น smart pointer ใน Rust ที่ช่วยให้เราจัดการ ownership ของข้อมูล T ร่วมกันในหลาย threads ได้อย่างปลอดภัย หลักการทำงานของ Arc<T> คือการนับจำนวนการอ้างอิง (reference count) ไปยังข้อมูล เมื่อการอ้างอิงสุดท้ายหมดไป ข้อมูลก็จะถูก deallocate โดยอัตโนมัติ ทำให้ป้องกันปัญหา memory leak และ dangling pointer ในสภาพแวดล้อมแบบ concurrent ได้
ทีนี้ถ้าเราอ่านดู คุณสมบัติมันก็จะเหมือนๆกับ Rc<T> เลย คำถามคือ “มันมีความแตกต่างระหว่าง Rc<T> และ Arc<T> กันอย่างไรละ**”**
Rc<T>(Reference Counting) ก็เป็น smart pointer ที่ใช้จัดการ ownership ร่วมกันเช่นกัน แต่Rc<T>ไม่ปลอดภัย ในการใช้งานกับหลาย threads เพราะการเพิ่ม/ลด reference count ไม่ใช่ atomic ซึ่งอาจเกิด data race ได้หากมีหลาย threads แก้ไขค่า reference count พร้อมกันได้Arc<T>แก้ปัญหานี้โดยใช้ atomic operations ในการจัดการ reference count ทำให้การเพิ่ม/ลดค่าเป็นไปอย่างปลอดภัยในสภาพแวดล้อมแบบ concurrent ได้
อธิบายเพิ่มเติม เรื่อง Atomic operations นะครับ
Atomic operations คือการดำเนินการกับข้อมูลที่รับประกันว่าจะทำงานเสร็จสมบูรณ์ใน “ขั้นตอนเดียว” โดยไม่มีการถูกขัดจังหวะโดยการดำเนินการอื่นใด ไม่ว่าจะเป็นจาก thread อื่น หรือ interrupt ใดๆก็ตาม ในบริบทของ multithreading การดำเนินการแบบ atomic มีความสำคัญอย่างยิ่งในการป้องกัน data races และรักษาความสอดคล้องของข้อมูลเอาไว้ได้
โดยปัญหา Data race นั้นเกิดขึ้นเมื่อ thread สอง thread หรือมากกว่าเข้าถึงและแก้ไขข้อมูลเดียวกันพร้อมกัน โดยที่อย่างน้อยหนึ่งในการเข้าถึงนั้นเป็นการแก้ไข การดำเนินการแบบ atomic ช่วยป้องกัน data races โดยรับประกันว่าการเข้าถึงและแก้ไขข้อมูลจะเป็นไปอย่าง exclusive คือ thread ใด thread หนึ่งจะเข้าถึงข้อมูลได้เพียง thread เดียวในเวลาใดเวลาหนึ่งได้
เรามาดูตัวอย่างของ Arc<T> กัน
use std::sync::Arc;use std::thread;
fn main() { let counter = Arc::new(0); // สร้าง Arc<i32> โดยมีค่าเริ่มต้นเป็น 0
let mut handles = vec![];
for _ in 0..10 { let counter = Arc::clone(&counter); // clone() เพิ่มตัวนับอ้างอิง
let handle = thread::spawn(move || { // ทำงานกับ counter (อ่านค่า) println!("Counter: {}", counter); }); handles.push(handle); }
for handle in handles { handle.join().unwrap(); }
println!("Final Counter: {}", counter); // ค่า counter ยังคงเป็น 0 เนื่องจากไม่มีการแก้ไขค่า}ในตัวอย่างนี้ Arc::clone(&counter) จะสร้าง Arc<T> ใหม่ที่ชี้ไปยังข้อมูลเดียวกันและเพิ่มตัวนับอ้างอิง เมื่อ Thread ทำงานเสร็จและ Arc<T> ใน Thread นั้นหมด scope ตัวนับอ้างอิงจะลดลง
Arc<T> เป็นเครื่องมือสำคัญในการจัดการข้อมูลที่แชร์ใน Rust โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมแบบ multithread ช่วยให้เขียน code concurrent ที่ปลอดภัยและมีประสิทธิภาพได้ง่ายขึ้น
Mutex
Mutex<T> (Mutual Exclusion) ใน Rust คือเครื่องมือสำหรับการจัดการการเข้าถึงข้อมูลร่วมกันระหว่างหลาย Thread อย่างปลอดภัย เพื่อป้องกันปัญหา Data Race ซึ่งเกิดขึ้นเมื่อหลาย Thread พยายามเข้าถึงและแก้ไขข้อมูลเดียวกันพร้อมกัน
Mutex<T> ทำงานโดยใช้หลักการของ “lock” กล่าวคือ ก่อนที่ Thread ใด Thread หนึ่งจะสามารถเข้าถึงข้อมูลภายใน Mutex<T> ได้ Thread นั้นจะต้องทำการ “lock” mutex ก่อน ถ้ามี Thread อื่นถือ lock อยู่ Thread ที่พยายาม lock จะต้องรอจนกว่า lock จะถูกปล่อย (unlock) หลังจากใช้งานข้อมูลเสร็จ Thread จะต้องทำการ “unlock” mutex เพื่อให้ Thread อื่นสามารถเข้าถึงข้อมูลได้
เรามาดูตัวอย่าง code กัน
use std::sync::{Arc, Mutex};use std::thread;
fn main() { let counter = Arc::new(Mutex::new(0)); // ใช้ Arc เพื่อแชร์ Mutex ระหว่าง Thread
let mut handles = vec![];
for _ in 0..10 { let counter = Arc::clone(&counter); // clone Arc เพิ่มตัวนับอ้างอิง
let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); // ล็อค Mutex *num += 1; // เพิ่มค่า }); handles.push(handle); }
for handle in handles { handle.join().unwrap(); // รอให้ Thread เสร็จสิ้น }
println!("Result: {}", *counter.lock().unwrap()); // แสดงผลลัพธ์}จาก code นี้
- เราใช้
Arc<Mutex<i32>>เพื่อให้Mutexสามารถแชร์ระหว่าง Thread ต่างๆ ได้ - แต่ละ Thread จะ lock
Mutexด้วยlock().unwrap()ก่อนที่จะเพิ่มค่า counter เข้าไป - เมื่อ Thread เสร็จสิ้น lock จะถูกปล่อยโดยอัตโนมัติ
- เมื่อทุก Thread ทำงานเสร็จ เราจะเห็นว่า counter เพิ่มขึ้น 10 อย่างถูกต้อง
ข้อควรระวังของการใช้ Mutex
- Deadlock: เกิดขึ้นเมื่อ Thread สอง Thread หรือมากกว่ารอ lock ซึ่งกันและกัน ทำให้โปรแกรมหยุดทำงาน ตัวอย่างเช่น Thread A ถือ lock ของ mutex M1 และพยายาม lock mutex M2 ในขณะที่ Thread B ถือ lock ของ mutex M2 และพยายาม lock mutex M1
- Poisoning: เกิดขึ้นเมื่อ Thread ที่ถือ lock เกิด panic ข้อมูลภายใน mutex อาจอยู่ในสถานะที่ไม่ถูกต้อง Rust จะ mark mutex ว่า “poisoned” เพื่อเตือนให้ทราบถึงปัญหานี้
Mutex<T> เป็นเครื่องมือสำคัญในการเขียนโปรแกรม concurrent ใน Rust ช่วยให้สามารถแชร์ข้อมูลระหว่าง Thread ได้อย่างปลอดภัยโดยป้องกัน data races อย่างไรก็ตาม ควรระวังเรื่อง deadlock และ poisoning เพื่อให้โปรแกรมทำงานได้อย่างเสถียรและไม่เกิดปัญหา error ตามมาได้
RwLock
RwLock<T> (Read-Write Lock) ใน Rust เป็นเครื่องมือสำหรับการจัดการการเข้าถึงข้อมูลร่วมกันระหว่างหลาย Thread โดยมีกลไกที่ยืดหยุ่นกว่า Mutex<T> ซึ่งอนุญาตให้มีผู้อ่านหลายคนพร้อมกัน แต่จำกัดให้มีผู้เขียนเพียงคนเดียวในแต่ละครั้ง
ความแตกต่างระหว่าง Mutex<T> และ RwLock<T>
Mutex<T>: อนุญาตให้ Thread เพียง Thread เดียวเข้าถึงข้อมูลได้ ไม่ว่าจะเป็นการอ่านหรือการเขียน เหมาะสำหรับกรณีที่มีการเขียนข้อมูลบ่อย หรือต้องการความปลอดภัยสูงสุด แม้กระทั่งการอ่านRwLock<T>: แยกการเข้าถึงออกเป็นสองแบบ:- Read access (การอ่าน): อนุญาตให้หลาย Thread เข้าถึงข้อมูลเพื่ออ่านได้พร้อมกัน
- Write access (การเขียน): อนุญาตให้ Thread เพียง Thread เดียวเข้าถึงข้อมูลเพื่อเขียนได้
RwLock<T>เหมาะสำหรับกรณีที่การอ่านข้อมูลเกิดขึ้นบ่อยกว่าการเขียน ซึ่งช่วยเพิ่มประสิทธิภาพการทำงานแบบ concurrent
RwLock<T> มีหลักการทำงานคล้ายกับ Mutex<T> แต่มีการจัดการที่ซับซ้อนกว่า เพื่อรองรับการอ่านพร้อมกันเพิ่มเติมเข้ามา
- Locking สำหรับการอ่าน (Read Lock): เมื่อ Thread ต้องการอ่านข้อมูล จะต้องขอ “read lock” หากไม่มี Thread ใดถือ “write lock” อยู่ Thread นั้นจะได้รับ “read lock” และสามารถอ่านข้อมูลได้ Thread อื่น ๆ ก็สามารถขอ “read lock” และอ่านข้อมูลพร้อมกันได้
- Locking สำหรับการเขียน (Write Lock): เมื่อ Thread ต้องการเขียนข้อมูล จะต้องขอ “write lock” หากไม่มี Thread ใดถือ “read lock” หรือ “write lock” อยู่ Thread นั้นจะได้รับ “write lock” และสามารถเขียนข้อมูลได้ ในขณะที่ Thread นั้นถือ “write lock” อยู่ Thread อื่น ๆ ไม่สามารถขอทั้ง “read lock” และ “write lock” ได้
ตัวอย่างการใช้งาน
use std::sync::{Arc, RwLock};use std::thread;
fn main() { let data = Arc::new(RwLock::new(0));
let mut handles = vec![];
for i in 0..5 { let data = Arc::clone(&data); let handle = thread::spawn(move || { if i % 2 == 0 { // Thread คู่ทำงานอ่าน let r = data.read().unwrap(); println!("Thread {} Reading: {}", i, *r); } else { // Thread คี่ทำงานเขียน let mut w = data.write().unwrap(); *w += 1; println!("Thread {} Writing: {}", i, *w); } }); handles.push(handle); }
for handle in handles { handle.join().unwrap(); }
println!("Final Value: {}", *data.read().unwrap());}ผลลัพธ์
Thread 2 Reading: 0Thread 0 Reading: 0Thread 1 Writing: 1Thread 3 Writing: 2Thread 4 Reading: 2Final Value: 2จาก code
- เราใช้
Arc<RwLock<i32>>เพื่อแชร์RwLockระหว่าง Thread - Thread ที่เป็นเลขคู่จะทำงานอ่านข้อมูล ในขณะที่ Thread ที่เป็นเลขคี่จะทำงานเขียนข้อมูล (ดังนั้นการเขียนข้อมูลควรจะเกิดขึ้นเพียง 2 ครั้ง)
RwLockช่วยให้การอ่านข้อมูลเกิดขึ้นพร้อมกันได้ โดยไม่เกิดปัญหา และรับประกันว่าการเขียนข้อมูลจะเกิดขึ้นแบบ exclusive
การพิจารณาระหว่าง Mutex<T> และ RwLock<T>
Mutex<T>: อนุญาตให้ Thread เดียวเท่านั้นเข้าถึงข้อมูล ไม่ว่าจะเป็นการอ่านหรือเขียน เหมาะสำหรับกรณีที่มีการเขียนข้อมูลบ่อยRwLock<T>: อนุญาตให้ผู้อ่านหลายรายเข้าถึงข้อมูลพร้อมกัน แต่จำกัดให้มีผู้เขียนเพียงรายเดียว เหมาะสำหรับกรณีที่มีการอ่านข้อมูลบ่อยกว่าการเขียน
สิ่งที่ควรระวังเกี่ยวกับ RwLock<T>
- Deadlock: เช่นเดียวกับ
Mutex<T>ควรระวัง deadlock โดยเฉพาะอย่างยิ่งเมื่อมีการใช้RwLockหลายตัวร่วมกัน - Starvation : ในบางกรณี หากมีผู้อ่านจำนวนมากเข้ามาอย่างต่อเนื่อง อาจทำให้ผู้เขียนไม่ได้รับโอกาสในการเข้าถึงข้อมูลเลย เกิดภาวะ starvation ได้
- Poisoning: ถ้า Thread panic ในขณะที่ถือ write lock
RwLockจะถูก poisoned คล้ายกับMutex
RwLock<T> เป็นเครื่องมือที่มีประโยชน์ในการจัดการการเข้าถึงข้อมูลที่แชร์ โดยเฉพาะอย่างยิ่งในสถานการณ์ที่มีการอ่านข้อมูลบ่อยกว่าการเขียน ช่วยเพิ่มประสิทธิภาพการทำงานของโปรแกรม concurrent แต่ควรพิจารณาข้อควรระวังต่างๆ เช่น deadlock และ starvation เพื่อให้โปรแกรมทำงานได้อย่างถูกต้องและมีประสิทธิภาพ
ส่งข้อมูลระหว่าง Thread
การส่งข้อมูลระหว่าง Thread ใน Rust คือกระบวนการที่ Thread ต่างๆ ในโปรแกรมสามารถแบ่งปันและเข้าถึงข้อมูลร่วมกันได้ ซึ่งมีความสำคัญในการเขียนโปรแกรม Concurrent หรือโปรแกรมที่ทำงานพร้อมกัน เพื่อให้ Thread ต่างๆ สามารถทำงานร่วมกันได้อย่างมีประสิทธิภาพ
ใน Rust มีวิธีการหลายอย่างในการส่งข้อมูลระหว่าง Thread อย่างปลอดภัย โดยเน้นเรื่องการป้องกัน Data Race ซึ่งเป็นปัญหาสำคัญในการเขียนโปรแกรม Concurrent
วิธีการส่งข้อมูลระหว่าง Thread ใน Rust จะมีวิธีการส่งในแต่ละแบบได้ดังนี้
- Move Semantics
- ใน Rust การย้ายความเป็นเจ้าของ (Ownership) ของข้อมูลจาก Thread หนึ่งไปอีก Thread หนึ่งเป็นวิธีที่ง่ายที่สุดในการส่งข้อมูล
- เมื่อข้อมูลถูกย้ายไปที่ Thread ใหม่ Thread เดิมจะไม่สามารถเข้าถึงข้อมูลนั้นได้อีก ป้องกันปัญหา Data Race ได้อย่างมีประสิทธิภาพ
- ใช้
movekeyword เพื่อบังคับการย้าย Ownership เข้าไปยัง Closure ของ Thread
ดัง code ตัวอย่างนี้
use std::thread;
fn main() { let message = String::from("Hello from main thread!");
thread::spawn(move || { println!("{}", message); // Ownership of message is moved to this thread });
// println!("{}", message); // Error: message has been moved}- Shared Memory กับ Mutex
std::sync::Mutex(Mutual Exclusion) ใช้สำหรับป้องกันการเข้าถึงข้อมูลพร้อมกันจากหลาย ThreadMutexจะล็อคข้อมูล ทำให้มีเพียง Thread เดียวที่สามารถเข้าถึงข้อมูลได้ในขณะใดขณะหนึ่ง- ใช้
Arc(Atomically Reference Counted) เพื่อให้สามารถแชร์ Ownership ของMutexระหว่าง Thread หลายตัว
ดัง code ตัวอย่างนี้
use std::sync::{Arc, Mutex};use std::thread;
fn main() { let counter = Arc::new(Mutex::new(0)); // Counter protected by Mutex let mut handles = vec![];
for _ in 0..10 { let counter = Arc::clone(&counter); // Increment the reference count let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); // Lock the mutex to access the data *num += 1; }); handles.push(handle); }
for handle in handles { handle.join().unwrap(); }
println!("Result: {}", *counter.lock().unwrap());}- Channels
ก่อนพูดถึง Channels เราขอพูดถึง MPSC ซึ่งเป็นรูปแบบการส่งที่ใช้ประโยชน์จาก Channels กันก่อน
Multiple Producer, Single Consumer (MPSC) คือ รูปแบบการสื่อสารระหว่าง Thread ที่อนุญาตให้มี Thread Producer หลาย Thread ส่งข้อมูลไปยัง Consumer Thread เพียง Thread เดียว
โดย Rust มีช่องทางการสื่อสารระหว่าง Thread ที่เรียกว่า Channel ซึ่งมี implementation แบบ MPSC ให้ใช้งานใน std::sync::mpsc โดย Channel ประกอบด้วย 2 ส่วนคือ
- Sender: ใช้โดย Producer Thread เพื่อส่งข้อมูลไปยัง Channel
- Receiver: ใช้โดย Consumer Thread เพื่อรับข้อมูลจาก Channel
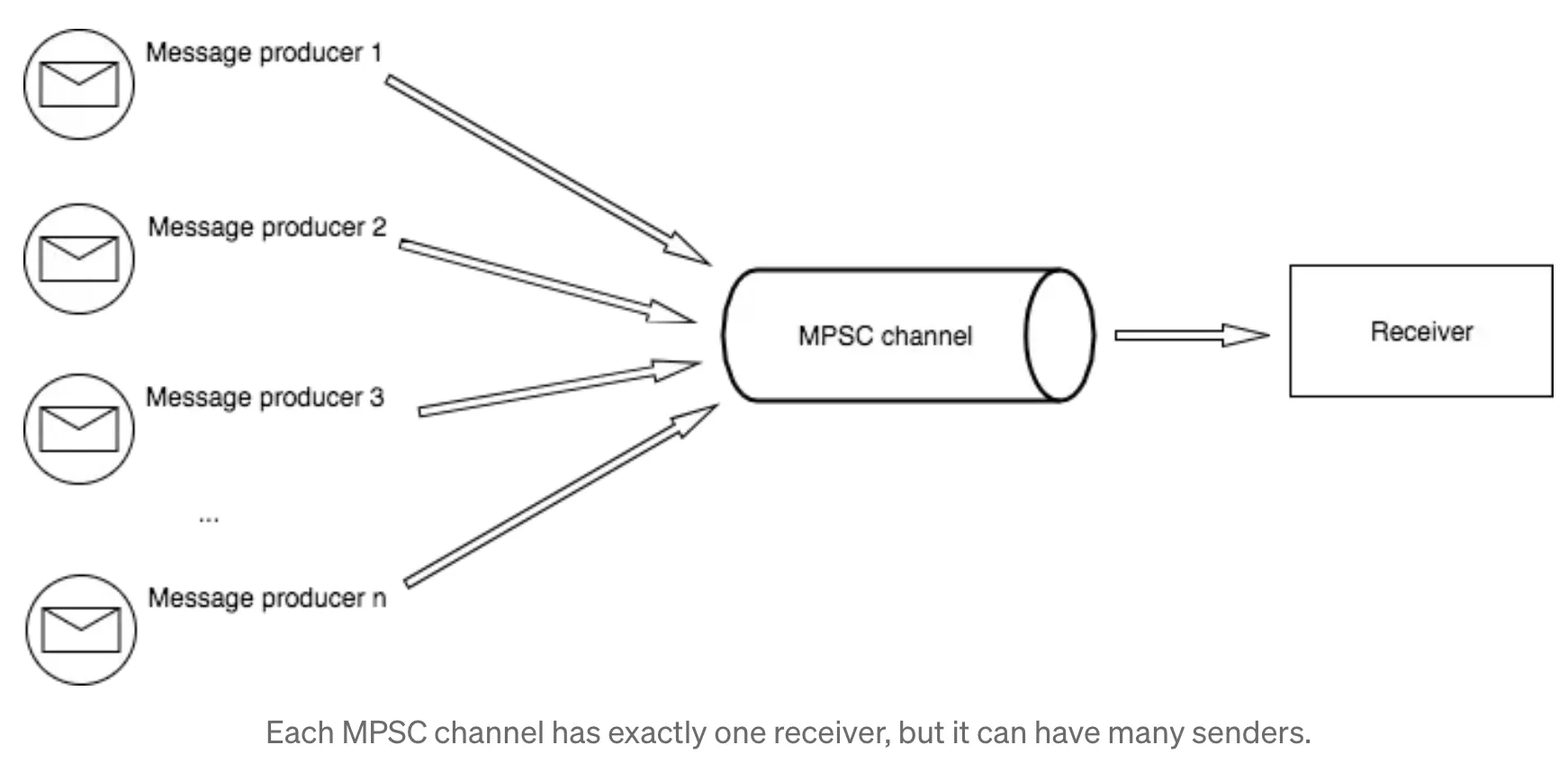
หลักการทำงานคือ Producer หลายรายสามารถสร้าง Sender clone ได้หลายอัน และส่งข้อมูลผ่าน Sender เหล่านั้นไปยัง Receiver ตัวเดียวกัน ซึ่งเป็นของ Consumer Thread เมื่อมีข้อมูลส่งเข้ามา Receiver จะรับข้อมูลตามลำดับที่ส่งเข้ามา (FIFO)
ข้อดีของการใช้ MPSC ใน Rust
- Rust ช่วยให้มั่นใจได้ว่าการส่งและรับข้อมูลผ่าน channel นั้นปลอดภัยต่อ Thread ป้องกัน data race ได้
- รวมถึง Channel จัดการเรื่องของ ownership ของข้อมูลที่ส่ง ทำให้ไม่ต้องกังวลเรื่องการจัดการ memory
ตัวอย่าง code การใช้ MPSC
use std::sync::mpsc;use std::thread;
fn main() { // สร้าง MPSC channel โดยใช้ mpsc::channel() let (tx, rx) = mpsc::channel(); // tx คือ Sender, rx คือ Receiver
let mut handles = vec![];
// สร้าง Thread Producer หลาย Thread for i in 0..3 { let tx = tx.clone(); // clone Sender เพื่อให้แต่ละ Thread มี Sender ของตัวเอง let handle = thread::spawn(move || { let message = format!("Message from producer {}", i); tx.send(message).unwrap(); // ส่งข้อมูลผ่าน Sender println!("Producer {} sent a message", i); }); handles.push(handle); }
// Thread หลักทำหน้าที่เป็น Consumer for _ in 0..3 { // รับข้อมูล 3 ครั้ง (เท่ากับจำนวน Producer) match rx.recv() { // รับข้อมูลจาก Receiver Ok(message) => println!("Consumer received: {}", message), Err(e) => println!("Error receiving message: {}", e), } }
for handle in handles { handle.join().unwrap(); }}- Atomic Types
Atomic Types คือ ประเภทข้อมูลพื้นฐานที่รองรับการทำงานแบบ atomic ซึ่งหมายถึงการดำเนินการกับข้อมูลประเภทนี้จะเกิดขึ้นอย่างสมบูรณ์ในขั้นตอนเดียว โดยไม่มีการแทรกแซงจาก Thread อื่น ๆ ในระหว่างการดำเนินการ ทำให้มั่นใจได้ว่าข้อมูลจะไม่เสียหายจากการเข้าถึงพร้อมกัน (data races) เหมาะสำหรับการใช้งานในสภาพแวดล้อมแบบ Multithread โดยเฉพาะ
std::sync::atomicใช้สำหรับตัวแปร Atomic ที่สามารถเข้าถึงและแก้ไขได้อย่างปลอดภัยจากหลาย Thread โดยไม่ต้องใช้ Lock- เหมาะสำหรับการนับเลข หรือ Flag ที่มีการแก้ไขบ่อยๆ
ดัง code ตัวอย่างนี้
use std::sync::atomic::{AtomicUsize, Ordering};use std::thread;
fn main() { let counter = Arc::new(AtomicUsize::new(0)); let mut handles = vec![];
for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { counter.fetch_add(1, Ordering::SeqCst); }); handles.push(handle); }
for handle in handles { handle.join().unwrap(); }
println!("Result: {}", counter.load(Ordering::SeqCst));}Asynchronous
Asynchronous Programming คือรูปแบบการเขียนโปรแกรมที่ช่วยให้โปรแกรมสามารถทำงานหลายอย่างพร้อมกันได้ โดยไม่ต้องสร้าง Thread ใหม่ทุกครั้ง ซึ่งช่วยเพิ่มประสิทธิภาพและลดการใช้ทรัพยากรของระบบ โดยเฉพาะอย่างยิ่งในงานที่เกี่ยวข้องกับการรอ เช่น การอ่านข้อมูลจากเครือข่าย การอ่านไฟล์ หรือการรับข้อมูลจากผู้ใช้
ความแตกต่างระหว่าง Asynchronous และ Thread
- Thread: สร้าง Thread ใหม่สำหรับแต่ละ Task ทำให้ใช้ทรัพยากรมากขึ้น และมี Overhead ในการสลับ Context ระหว่าง Thread
- Asynchronous: ใช้ Thread เดียว (หรือจำนวนน้อยกว่า) เพื่อจัดการ Task หลายอย่าง โดยสลับการทำงานระหว่าง Task อย่างรวดเร็ว ทำให้ประหยัดทรัพยากรและเพิ่มประสิทธิภาพ
โดยหลักการทำงานของ Asynchronous ใน Rust คือ Rust จะใช้แนวคิดของ Futures และ Async/Await ในการจัดการ Asynchronous Programming
- Future คือ Object ที่แทนผลลัพธ์ของการคำนวณแบบ Asynchronous ซึ่งอาจจะยังไม่เสร็จสิ้นในทันที เมื่อการคำนวณเสร็จสิ้น Future จะให้ผลลัพธ์ออกมา
- Async/Await เป็น Syntax ที่ช่วยให้เขียน code Asynchronous ได้ง่ายขึ้น คล้ายกับการเขียน code Synchronous (ถ้าใครที่คุ้นชินกับ javascript ก็จะทรงเดียวกันเลย)
async: ใช้กับ Function หรือ Block เพื่อระบุว่า code ภายในเป็นแบบ Asynchronousawait: ใช้ภายในasyncFunction เพื่อรอให้ Future เสร็จสิ้น
ตัวอย่างการใช้งาน Asynchronous ใน Rust
use tokio::time::{sleep, Duration};
#[tokio::main]async fn main() { println!("Start");
// เรียกใช้ function asynchronous พร้อมกัน let task1 = async { println!("Task 1 start"); sleep(Duration::from_secs(2)).await; // รอ 2 วินาที println!("Task 1 end"); "Result from Task 1" // คืนค่าจาก Task };
let task2 = async { println!("Task 2 start"); sleep(Duration::from_secs(1)).await; // รอ 1 วินาที println!("Task 2 end"); "Result from Task 2" };
// รอให้ Task ทั้งสองเสร็จสิ้นพร้อมกัน let (result1, result2) = tokio::join!(task1, task2);
println!("{}", result1); println!("{}", result2);
println!("End");}จาก code
- เราใช้
tokio::mainซึ่งเป็น Macro จาก Cratetokioเพื่อกำหนดว่า functionmainเป็นแบบ Asynchronous Runtime asyncblock สร้าง Future ที่แทนการทำงานของแต่ละ Tasksleep(Duration::from_secs(n)).awaitทำให้โปรแกรมรอnวินาทีโดยไม่ Block Threadtokio::join!รอให้ Future หลายตัวเสร็จสิ้นพร้อมกัน- ผลลัพธ์ที่ได้คือ Task 2 จะเสร็จก่อน Task 1 เพราะใช้เวลารอน้อยกว่า แต่โปรแกรมจะไม่ Block และรอ Task 1 ให้เสร็จก่อน Task 2
อธิบายเพิ่มเติมเรื่อง tokio
Tokio (https://docs.rs/tokio/) เป็น Asynchronous Runtime สำหรับภาษา Rust ซึ่งเป็นเครื่องมือสำคัญสำหรับการเขียนโปรแกรมแบบ Asynchronous โดย Tokio ช่วยจัดการการทำงานของ Futures และ Tasks ทำให้โปรแกรมสามารถทำงานหลายอย่างพร้อมกันได้ โดยไม่ต้องสร้าง Thread ใหม่จำนวนมาก โดยหน้าที่หลักๆของ Tokio คือ
- Tokio ทำหน้าที่เป็น Runtime สำหรับการทำงานแบบ Asynchronous ใน Rust ตั้งแต่
- Executor ทำหน้าที่ Run Futures โดยการเรียก Method
pollของ Future วนไปเรื่อยๆ จนกว่า Future จะเสร็จสิ้น - Reactor ทำหน้าที่จัดการ Event ที่มาจากระบบปฏิบัติการ เช่น I/O Event (การอ่านเขียนไฟล์ หรือ Network) และส่ง Event เหล่านี้ไปยัง Executor เพื่อให้ Executor ปลุก Future ที่เกี่ยวข้องให้ทำงานต่อ
- Scheduler จัดการการทำงานของ Task และกระจายงานไปยัง Thread ต่างๆ ใน Thread Pool
- Timer จัดการการหน่วงเวลาและการตั้งเวลา
- Executor ทำหน้าที่ Run Futures โดยการเรียก Method
- รวมถึง Tokio มี Library และ Crate มากมายที่สร้างขึ้นบน Tokio ทำให้สามารถใช้งาน function ต่างๆ ได้ง่ายขึ้น เช่น
reqwest(สำหรับทำ HTTP Request),tokio-postgres(สำหรับเชื่อมต่อกับ PostgreSQL Database) ,tonic(สำหรับ gRPC)
ขยายความเพิ่มอีกเล็กน้อย Asynchronous Runtime ในภาษา Rust นั้นเป็นส่วนขยายของ Runtime หลักของ Rust ซึ่งช่วยเพิ่มเครื่องมือและสภาพแวดล้อมที่จำเป็นสำหรับการทำงานของ code แบบ Asynchronous โดย
- ในขณะที่ runtime หลักของ Rust มุ่งเน้นไปที่การทำงานแบบ Synchronous
- บน Thread เดียว Asynchronous Runtime เช่น Tokio ได้เพิ่มความสามารถในการจัดการ Concurrency และการจัดการ I/O, ตัวจับเวลา และเหตุการณ์แบบ Asynchronous เพิ่มเติมเข้ามา ซึ่งทำได้ผ่านองค์ประกอบต่าง ๆ เช่น Event Loop ที่คอยตรวจจับเหตุการณ์ และ Scheduler ที่จัดการการทำงานของ Tasks แบบ Asynchronous
ส่วน การทำงานร่วมกันระหว่าง runtime ของ Rust และ runtime แบบ Asynchronous เช่น Tokio นั้น ขึ้นอยู่กับการผสานที่เกิดจาก Macro อย่าง #[tokio::main] ซึ่ง Macro เหล่านี้ทำหน้าที่ปรับเปลี่ยน function main ให้สามารถเชื่อมโยงระหว่างการประมวลผลแบบ Synchronous ของ Rust และสภาพแวดล้อมแบบ Asynchronous ที่ runtime ของ Tokio จัดเตรียมไว้ได้
เมื่อโปรแกรมเริ่มทำงาน runtime ของ Tokio จะถูกเริ่มต้นภายใน Runtime หลักของ Rust ซึ่งสิ่งนี้จะช่วยตั้งค่า Event Loop และ Scheduler ของ Tokio ทำให้มันสามารถจัดการ Tasks แบบ Asynchronous ได้อย่างเต็มที่
เมื่อทุกอย่างเรียบร้อย Runtime หลักของ Rust จะยังคงจัดการการทำงานโดยรวมของโปรแกรมต่อไป ในขณะที่ Tokio จะดูแลการทำงานของ Tasks แบบ Asynchronous โดยการสื่อสารผ่านคำสั่ง await วิธีการแบบ Cooperative นี้ช่วยผสานจุดเด่นของ runtime ทั้งสอง ทำให้การพัฒนา code แบบ Asynchronous ใน Rust เป็นไปได้อย่างมีประสิทธิภาพและราบรื่นภายใต้โมเดลการทำงานของ Rust ได้
Summary & More
บทความนี้ได้สำรวจหัวข้อพื้นฐานที่สำคัญในภาษา Rust ตั้งแต่เรื่องของ Collection ประเภทต่างๆ เช่น Vector, String และ Hash Map ซึ่งเป็นโครงสร้างข้อมูลที่ใช้บ่อยในการจัดเก็บและจัดการข้อมูล ต่อมาได้อธิบายเรื่อง Generics ซึ่งเป็นกลไกที่ช่วยให้เขียน code ที่รองรับหลายชนิดข้อมูลได้โดยไม่ต้องเขียน code ซ้ำซ้อน รวมถึง Trait ซึ่งเป็นเหมือน Interface ในภาษาอื่นๆ ที่กำหนดชุดของ function ที่ประเภทต่างๆ สามารถนำมาใช้ได้
รวมถึงได้อธิบายถึง Smart Pointers ซึ่งเป็นโครงสร้างข้อมูลที่ช่วยจัดการหน่วยความจำอัตโนมัติ ทำให้ code มีความปลอดภัยและลดโอกาสเกิดข้อผิดพลาด และ Lifetime ซึ่งเป็นแนวคิดที่ใช้จัดการอายุการใช้งานของข้อมูลเพื่อป้องกัน dangling references และ concurrency ซึ่ง Rust มีเครื่องมือต่างๆ ที่ช่วยในการจัดการ concurrency ได้อย่างปลอดภัยและมีประสิทธิภาพ
ส่วนในเรื่อง concurrency ได้กล่าวถึงการสร้าง Thread การส่งข้อมูลระหว่าง Thread และ asynchronous programming ซึ่งเป็นรูปแบบการเขียนโปรแกรมที่ช่วยให้โปรแกรมทำงานหลายอย่างพร้อมกันได้โดยไม่ต้องสร้าง Thread ใหม่ทุกครั้ง โดยรวมแล้ว บทความนี้ครอบคลุมหัวข้อพื้นฐานที่สำคัญในการเขียนโปรแกรมด้วยภาษา Rust ซึ่งจะช่วยให้ผู้อ่านมีความเข้าใจในหลักการและสามารถนำไปประยุกต์ใช้ในการพัฒนาโปรแกรมได้อย่างมีประสิทธิภาพและปลอดภัย
บทความเพิ่มเติมที่สามารถอ่านได้
- การจัดการ module อ่านเพิ่มเติมจากนี่ได้ (มีโอกาสจะมาเจาะลึกไปพร้อมๆกับ framework สักตัว) https://doc.rust-lang.org/book/ch07-00-managing-growing-projects-with-packages-crates-and-modules.html
- https://medium.com/@be.munin/rust-เจาะลึกหน่วยความจำ-stack-heap-และ-virtual-memory-part-1-93c0cc77874f
- ลองเล่น Stripe payment gateway กันมี Video มี Github
แนะนำ Stripe payment gateway ที่สามารถทำให้เราทำเว็บชำระเงินออกมาได้

- รู้จักกับ React Hook และ Componentมี Video
พาทัวร์ feature ต่างๆของ React กันแบบรวดเร็วกัน สำรวจไปทุกๆ feature พร้อมกัน

- รู้จักกับ Storybook และการทำ Component Specsมี Video
มาลองทำ Component Specs และ Interactive Test ผ่าน Storybook กัน

-
