

 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
LangGraph คืออะไร ?
LangGraph คือ framework และ runtime ระดับ low level (Low-level orchestration framework) ที่ออกแบบมาเพื่อใช้สร้าง จัดการ และปรับใช้เอเจนต์ (Agents) ที่ต้องทำงานต่อเนื่องเป็นเวลานานและมีการบันทึกสถานะการทำงาน (Long-running, stateful agents)
รูปแบบการทำงานหลักของ LangGraph จะจำลอง workflow ของเอเจนต์ออกมาในรูปแบบของ Graphs โดยประกอบด้วยองค์ประกอบหลัก 3 ส่วน ได้แก่:
- State: โครงสร้างข้อมูลส่วนกลางที่ใช้แชร์สถานะการทำงานปัจจุบันของ application
- Nodes: function ที่บรรจุ logic การทำงานของเอเจนต์ ทำหน้าที่รับ State เข้ามาประมวลผลและส่ง State ที่อัปเดตแล้วกลับไป
- Edges: function ที่ใช้กำหนดเส้นทางว่า Node ถัดไปที่จะถูกเรียกใช้งานคืออะไร โดยอาจเป็นเส้นทางแบบตายตัวหรือมีเงื่อนไข (Conditional branches) ก็ได้ กล่าวสั้นๆ คือ Nodes มีหน้าที่ทำงาน ส่วน Edges มีหน้าที่บอกว่าต้องทำอะไรต่อไป
จุดเด่นของ LangGraph คือการมุ่งเน้นไปที่โครงสร้างพื้นฐานเบื้องหลังที่สำคัญ เช่น
- การทำงานที่ทนทานต่อความล้มเหลวและสามารถทำต่อจากจุดเดิมได้ (Durable execution)
- การตอบสนองผลลัพธ์แบบ realtime (Streaming)
- การให้มนุษย์เข้ามาตรวจสอบหรือแทรกแซงการตัดสินใจได้ (Human-in-the-loop)
- หรือการมีระบบหน่วยความจำทั้งระยะสั้นและระยะยาว
ความแตกต่างระหว่าง LangGraph และ LangChain
แม้ว่า LangGraph จะถูกสร้างขึ้นโดยผู้สร้าง LangChain และสามารถทำงานร่วมกันได้ แต่ทั้งสองมีจุดประสงค์และระดับการใช้งานที่แตกต่างกันดังนี้:
- ระดับความลึกของการควบคุม (Level of Abstraction):
- LangGraph จะมีความเป็น Low-level มากกว่า โดยเน้นไปที่การจัดระเบียบ workflow (Orchestration) และจะไม่ได้ทำสถาปัตยกรรมสำเร็จรูปหรือ Prompt ซ่อนไว้เบื้องหลัง (Not abstract prompts or architecture) ทำให้ผู้พัฒนาสามารถควบคุมการตัดสินใจและการไหลของข้อมูลในระบบได้อย่างอิสระ
- LangChain จะเป็นเครื่องมือระดับ High-level ที่มีสถาปัตยกรรมสำเร็จรูปสำหรับเอเจนต์ (Prebuilt architectures) ที่เหมาะกับการทำงานร่วมกับ LLM และการใช้เครื่องมือ (Tool-calling loops) ทั่วไป
- การเริ่มต้นใช้งาน: หากเพิ่งเริ่มต้นสร้างเอเจนต์หรือต้องการใช้ Abstraction ระดับสูงเพื่อความรวดเร็ว ขอแนะนำให้ใช้สถาปัตยกรรมสำเร็จรูปของ LangChain แต่หากต้องการสร้างระบบที่มีความซับซ้อนสูงและต้องการควบคุมทุกขั้นตอนอย่างละเอียด LangGraph จะเป็นตัวเลือกที่ตอบโจทย์มากกว่า
- แปลไทยเป็นไทยง่ายๆอีกทีว่า “ถ้า LangChain ตอบโจทย์อยู่แล้ว ก็ไม่มีเหตุผลอะไรที่ต้องมาแตะ LangGraph”
- LangGraph มักจะมากับโจทย์ที่ต้องการความเป็น deterministic มากขึ้น
- ความอิสระของ framework : เราสามารถใช้งาน LangGraph เป็นโครงสร้างพื้นฐานหลักสำหรับ application ได้โดย ไม่จำเป็นต้องใช้ component ของ LangChain ร่วมด้วยเลยก็ได้
- ซึ่งเดี๋ยวเราจะได้เห็นผ่านหัวข้อนี้เช่นกัน ว่ามุมมองของการสร้าง Agent แบบฉบับ LangGraph จะมีวิธีประยุกต์ใช้หลายแบบ ที่หลายๆเคสก็อาจจะไม่จำเป็นต้องใช้ร่วมกับ LLM ก็ได้
องค์ประกอบหลักของ LangGraph
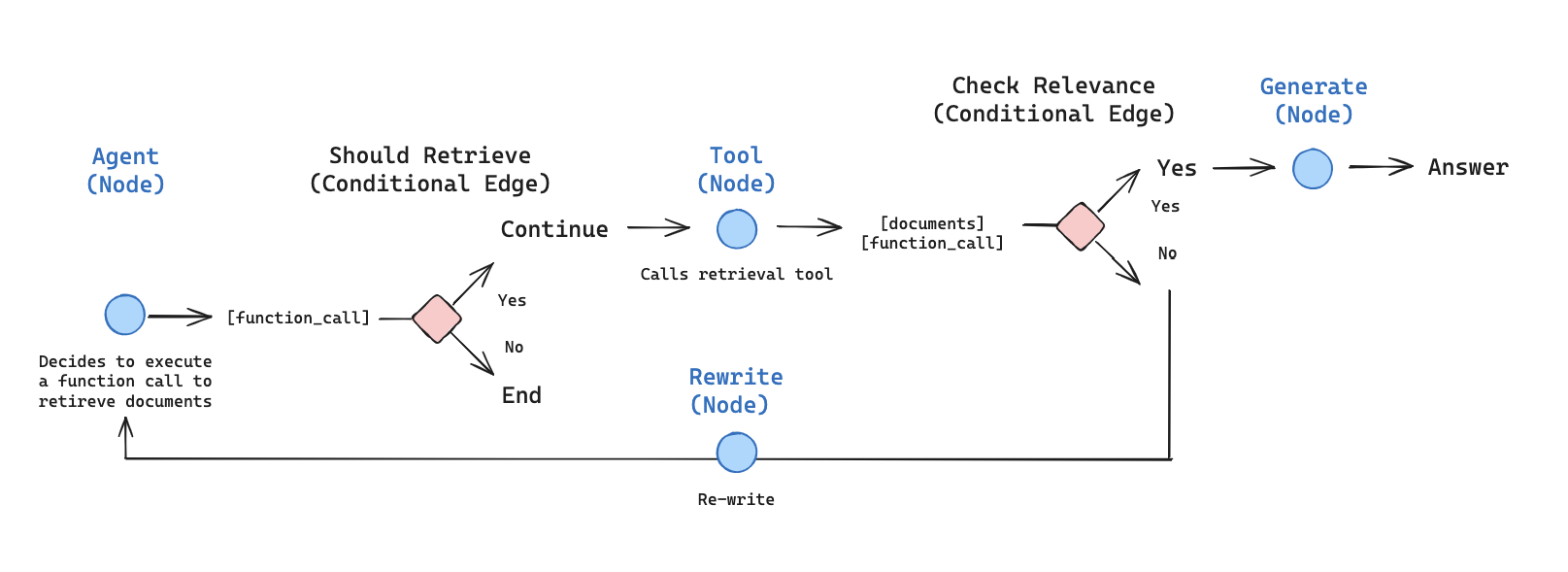 ref: https://docs.langchain.com/oss/python/langgraph/agentic-rag
ref: https://docs.langchain.com/oss/python/langgraph/agentic-rag
องค์ประกอบพื้นฐานที่ควรจะต้องรู้จักก่อนสำหรับคนที่เริ่มต้น LangGraph ควรจะต้องเข้าใจ 4 คำนี้ให้ขึ้นใจก่อน (ซึ่งเดี๋ยวเราจะเล่นผ่านตัวอย่างที่ 1-2 กัน)
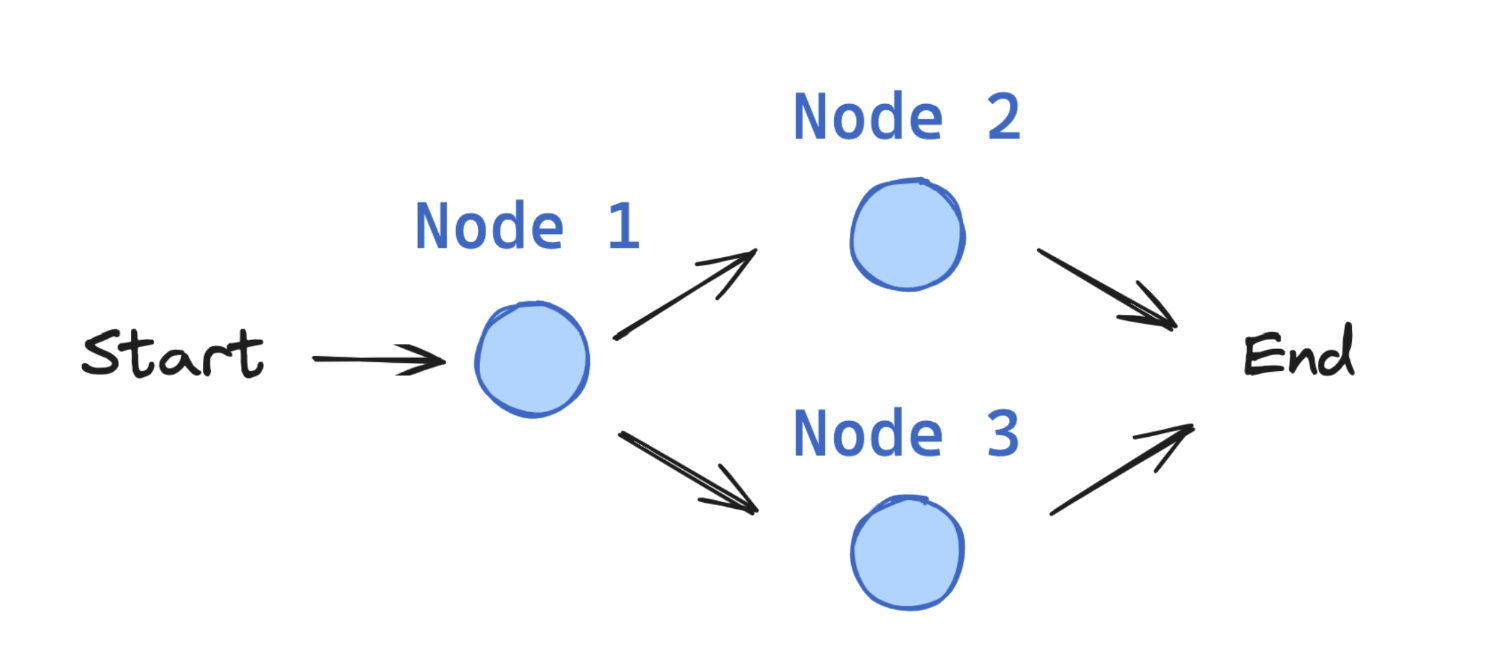 ref:
ref: 1. State (สถานะของกราฟ) เป็นโครงสร้างข้อมูลส่วนกลางที่ใช้แสดงข้อมูลปัจจุบันทั้งหมดของ application State จะประกอบไปด้วย Schema ของกราฟที่จะถูกใช้เป็นข้อมูลนำเข้าและส่งออกให้กับทุก Nodes และ Edges นอกจากนี้ภายใน State มักจะมีการทำงานร่วมกับ Reducers ซึ่งเป็นฟังก์ชันที่คอยกำหนดรูปแบบว่าข้อมูลใหม่ที่โหนดส่งมาจะถูกนำไปอัปเดตลงใน State อย่างไร (เช่น การนำข้อความใหม่ไปต่อท้ายรายการเดิม) โดยหากเราไม่ได้ระบุ Reducer ไว้ ระบบจะให้ข้อมูลใหม่เขียนทับ (Override) ข้อมูลเดิมโดยอัตโนมัติ
2. Nodes (โหนดประมวลผล) เป็นฟังก์ชันภาษา Python (รองรับทั้งแบบ Synchronous และ Asynchronous) ที่ทำหน้าที่บรรจุ logic การทำงานของเอเจนต์ หน้าที่หลักของโหนดคือการดึงข้อมูลจาก State ปัจจุบันมาประมวลผล และส่งผลลัพธ์การทำงานกลับไปเพื่ออัปเดต State ทั้งนี้ในระบบยังมีโหนดพิเศษอีก 2 ตัว คือ START node ที่เป็นตัวแทนของการส่งข้อมูลจากผู้ใช้งานเข้าสู่กราฟ และ END node ที่ทำหน้าที่เป็นจุดสิ้นสุดการทำงาน
3. Edges (เส้นทางการเชื่อมต่อ) เป็นฟังก์ชันที่ใช้กำหนดเส้นทาง logic และทำการตัดสินใจว่าหลังจากโหนดปัจจุบันทำงานเสร็จแล้ว กราฟควรจะเคลื่อนที่ไปทำงานที่โหนดใดต่อไป หรือควรจะหยุดการทำงาน หากจะให้อธิบายหลักการทำงานร่วมกันอย่างง่ายที่สุดก็คือ Nodes มีหน้าที่ทำงาน ส่วน Edges มีหน้าที่บอกว่าต้องทำอะไรต่อไป รูปแบบของ Edges มีหลายประเภท ได้แก่ Normal Edges (เชื่อมต่อไปโหนดถัดไปแบบตายตัว), Conditional Edges (เรียกใช้ฟังก์ชันเงื่อนไขเพื่อหาโหนดถัดไป), ตลอดจน Entry Point และ Conditional Entry Point ที่กำหนดจุดเริ่มต้นการรันของกราฟ
4. Persistence หรือ Checkpointer (ระบบบันทึกสถานะ) LangGraph มีระบบช่วยบันทึกสถานะของกราฟออกมาเป็น Checkpoints แยกตามรหัส Thread เพื่อเก็บประวัติในแต่ละขั้นการทำงาน (Super-step) องค์ประกอบส่วนนี้สำคัญมากเพราะเป็นตัวขับเคลื่อน feature เช่น ระบบความจำระหว่างการสนทนา (Memory), การหยุดเพื่อรอการตรวจสอบจากมนุษย์ (Human-in-the-loop), การย้อนประวัติกลับไปแก้เส้นทาง (Time travel), ตลอดจนช่วยให้ระบบสามารถกลับมาทำต่อได้หากเกิดข้อผิดพลาดระหว่างทาง (Fault-tolerance)
เพื่อให้เกิดความเข้าใจที่มากขึ้น เราจะค่อยๆเล่าแต่ละส่วนไปพร้อมกับตัวอย่างแต่ละ Example กัน
Example 1 - Get Start
ref: https://docs.langchain.com/oss/python/langgraph/quickstart
เริ่มต้น เราจะลองมาสร้าง Agent ง่ายๆนั่นคือ Agent สำหรับสร้างมุกตลกกัน แต่เพื่อให้ทุกคนเข้าใจองค์ประกอบของ State - Node - Edge เราจะเอาส่วน LLM ออกไปก่อนให้เหมือนเป็น function ทั่วไป
เริ่มต้น เราจะสร้าง file ชื่อ agent.py ขึ้นมาโดยประกอบด้วย
- State สำหรับเก็บสถานะของข้อมูลขณะกำลังเดินทาง โดยเราจะเก็บทั้งหมด 2 ข้อมูลไว้คือ
topicคือ หัวข้อของมุกตลก และjokeมุกตลกที่เราจะส่งต่อสุดท้ายออกมา
from typing import TypedDictfrom langgraph.graph import StateGraph, START, END
# 1. กำหนด State (หน่วยความจำส่วนกลาง)class State(TypedDict): topic: str joke: str
# 2. สร้าง Node (ฟังก์ชันการทำงานของเอเจนต์)def generate_joke(state: State): topic = state["topic"] # ในการใช้งานจริงตรงนี้จะเป็นการเรียกใช้ LLM new_joke = f"ทำไม {topic} ถึงไปโรงเรียน? เพราะอยากมีความรู้ไงล่ะ!" return {"joke": new_joke}
# 3. สร้าง StateGraph และประกอบร่าง (Wire it together)builder = StateGraph(State)
# เพิ่ม Node ลงไปในกราฟbuilder.add_node("generate_joke", generate_joke)
# กำหนดเส้นทางเดินของกราฟbuilder.add_edge(START, "generate_joke")builder.add_edge("generate_joke", END)
# 4. Compile เพื่อให้กราฟพร้อมใช้งานgraph = builder.compile()อธิบายจาก code
- การกำหนด State (
class State(TypedDict)) ส่วนนี้คือการสร้าง โครงสร้างข้อมูลส่วนกลาง (Shared data structure) ที่ทุก Node ในกราฟจะใช้อ่านและเขียนข้อมูลร่วมกัน โดยใน code ได้กำหนด Schema ด้วยTypedDictว่า application จะจดจำตัวแปร 2 ตัว คือtopic(หัวข้อ) และjoke(มุกตลก) - การสร้าง Node (
def generate_joke(state: State)) นี่คือ function ภาษา Python ที่ทำหน้าที่เป็น Node ประมวลผลหรือคนทำงาน- การอ่านข้อมูล: โหนดนี้รับเอา
stateปัจจุบันเข้ามาเพื่อดึงข้อมูลstate["topic"]ไปประมวลผล - การอัปเดตข้อมูล: เมื่อโหนดทำงานเสร็จ (ในที่นี้คือสร้างข้อความมุกตลก) โหนดจะไม่ได้คืนค่า State กลับไปทั้งหมด แต่จะ ส่งคืนเฉพาะข้อมูลอัปเดต (State Update) ในรูปแบบของ Dictionary คือ
{"joke": new_joke}เพื่อนำข้อความตลกประโยคใหม่ไปอัปเดตใน State
- การอ่านข้อมูล: โหนดนี้รับเอา
- การสร้าง StateGraph และประกอบร่างด้วย Edge
- StateGraph(State): เป็นการเริ่มต้นสร้างกราฟ โดยนำโครงสร้าง
Stateที่ตั้งไว้ในข้อ 1 มาเป็นแกนหลัก - add_node: นำ function ที่เราสร้างในข้อ 2 มา register เข้าไปในระบบโดยตั้งชื่อให้มันว่า
"generate_joke" - add_edge: ส่วนนี้คือการสร้าง Normal Edges (เส้นทางการเชื่อมต่อแบบตายตัว) เพื่อบอกว่ากราฟควรทำงานในลำดับแบบไหน โดย:
add_edge(START, "generate_joke"): กำหนดให้จุดเริ่มต้นการทำงาน (STARTซึ่งเป็น Node พิเศษสำหรับรับข้อมูล input จากผู้ใช้งาน) วิ่งตรงไปหาโหนด"generate_joke"เป็นอันดับแรกadd_edge("generate_joke", END): กำหนดว่าเมื่อโหนด"generate_joke"ทำงานของตัวเองเสร็จ ให้ส่งต่อเส้นทางไปที่ENDซึ่งเป็นโหนดพิเศษสำหรับใช้เป็นจุดสิ้นสุดการทำงานของโปรแกรม
- StateGraph(State): เป็นการเริ่มต้นสร้างกราฟ โดยนำโครงสร้าง
- Compile เพื่อให้กราฟพร้อมใช้งาน (
builder.compile()) นี่เป็นขั้นตอนสุดท้ายที่จำเป้นต้องทำ โดยระบบจะนำ State, Node และ Edge ทั้งหมดมาประกอบกันและตรวจสอบความถูกต้องของโครงสร้างพื้นฐาน (เช่น มีโหนดไหนที่เชื่อมต่อไม่สมบูรณ์หรือไม่) หลังจากขั้นตอนนี้ กราฟของคุณจะพร้อมรับข้อมูลเข้าสู่โหนดSTARTและประมวลผลตามเส้นทางที่วางไว้ครับ
โดยพื้นฐานเริ่มต้น concept ของการสร้าง agent LangGraph จะต้องมี 4 ขั้นตอนนี้เสมอเพื่อประกอบให้กลายเป็นกราฟสำหรับการทำงานใน Agent ขึ้นมาได้
สำหรับทดลองผลลัพธ์ผ่าน terminal สามารถทำได้ผ่าน command python agent.py (ท่าเดียวกับ LangChain ที่เคยทำในหัวข้อก่อนหน้านี้)
- โดย concept การเรียกนั้น จะมีความคล้ายๆกับท่า LangChain คือใช้คำสั่ง
.invoke()ในการเรียก แต่จะเปลี่ยนจากการส่ง prompt หรือ text เข้าไป จะเป็นการส่ง State เริ่มต้นของข้อมูลเข้าไป (ซึ่งถ้าเราจะทำเป็นส่ง prompt เข้าไป มันก็คือการทำให้ prompt กลายเป็น State หนึ่งของ LangGraph)
if __name__ == "__main__": print("--- เริ่มการทำงานของ LangGraph ---")
# กำหนด Input เริ่มต้น initial_state = {"topic": "สุนัข"} print(f"Input ที่ส่งเข้าไป: {initial_state}")
# สั่งให้กราฟประมวลผลด้วยคำสั่ง .invoke() result = graph.invoke(initial_state)
# แสดงผลลัพธ์สุดท้าย print("\n--- ผลลัพธ์ที่ได้ ---") print(f"หัวข้อ: {result['topic']}") print(f"มุกตลก: {result['joke']}")Result
--- เริ่มการทำงานของ LangGraph ---Input ที่ส่งเข้าไป: {'topic': 'สุนัข'}
--- ผลลัพธ์ที่ได้ ---หัวข้อ: สุนัขมุกตลก: ทำไม สุนัข ถึงไปโรงเรียน? เพราะอยากมีความรู้ไงล่ะ!ทีนี้ด้วยความที่ concept ของ LangGraph นั้น เป็นการสร้างกราฟที่มีการ define ผ่าน code อยู่แล้ว ดังนั้น มันจึงสามารถแสดงผลหน้าตากราฟออกมาให้ดูได้เช่นกัน
โดยเราสามารถลองให้ print graph ออกมาได้ผ่าน format mermaid ด้วยวิธีตามด้านล่างนี้
- ฉบับ python = ต้องเขียน file ภาพออกมา เนื่องจากไม่สามารถแสดงภาพโดยตรงบน terminal ได้
# 1. ดึงข้อมูลรูปภาพ PNG จากกราฟpng_data = graph.get_graph().draw_mermaid_png()
# 2. บันทึกลงไฟล์ชื่อ graph.png ในโฟลเดอร์ปัจจุบันwith open("graph.png", "wb") as f: f.write(png_data)- ฉบับ Jupyter notebook = support การแสดงภาพโดยตรง ดังนั้น สามารถใช้คำสั่ง
displayของIPython.displayในการแสดงผลออกมาได้เลย
from IPython.display import Image, display
# แสดงรูปภาพโครงสร้างกราฟdisplay(Image(graph.get_graph().draw_mermaid_png()))หน้าตาที่ได้ก็จะประมาณนี้
ลองผ่าน LangSmith
ทีนี้เพื่อให้การพัฒนา LangGraph สามารถทำได้ง่ายขึ้น ฝั่งผู้พัฒนาเองก็ได้สร้างเครื่องมือที่อำนวยความสะดวกในการใช้งานร่วมกับกราฟของ LangGraph อีกเครื่องมือหนึ่งนั่นก็คือ LangSmith ขึ้นมา
 ref: https://docs.langchain.com/oss/python/langgraph/studio
ref: https://docs.langchain.com/oss/python/langgraph/studio
LangSmith คือ Platform ที่ออกแบบมาเพื่อใช้ติดตาม (Tracing), Debugging, ประเมินผล (Evaluation) และดูแลการทำงานของ application ที่ขับเคลื่อนด้วย LLM และเอเจนต์ โดยทำงานควบคู่กับ framework อย่าง LangChain และ LangGraph ได้
การใช้งาน LangSmith จะช่วยทำให้การพัฒนา LangGraph ง่ายขึ้นในหลายมิติ ตั้งแต่
- การมองเห็นภาพรวมและการติดตามสถานะแบบละเอียด (Visualization & Tracing) LangSmith ให้การมองเห็นเชิงลึกในพฤติกรรมที่ซับซ้อนของเอเจนต์ ทำให้เราสามารถติดตามเส้นทางการประมวลผลของกราฟ (Execution paths) ดูการเปลี่ยนแปลงของ State ตลอดจนเห็นข้อมูลทุกอย่างที่เกิดขึ้นในแต่ละขั้น เช่น promtp ที่ส่งไปยังโมเดล, การเรียกใช้เครื่องมือ (Tool calls), และผลลัพธ์ที่ได้มา
- การดีบักและทดสอบผ่านหน้า UI (LangSmith Studio) LangSmith มีเครื่องมือชื่อ Studio ซึ่งเป็นหน้าต่าง UI แบบภาพ (Visual interface) ให้คุณเชื่อมต่อกับเอเจนต์ที่รันอยู่บนเครื่อง Local ของคุณได้ ช่วยให้คุณสามารถ:
- ทดลองป้อนข้อมูล (Inputs) และดูการโต้ตอบแบบเรียลไทม์ได้โดยไม่ต้องเขียนโค้ดเพิ่ม หรือทำ Deployment
- เมื่อเกิดข้อผิดพลาดขึ้น (Exceptions) Studio จะจับภาพและแสดงสถานะ (State) ณ วินาทีนั้น ทำให้เข้าใจได้ทันทีว่าเกิดปัญหาขึ้นจากอะไร
- มีระบบ Hot-reloading หากคุณแก้ไขพรอมต์หรือโค้ดในโปรเจกต์ Studio จะอัปเดตผลลัพธ์ให้ทันที และคุณยังสามารถสั่งรันการสนทนาซ้ำจากจุดใดก็ได้เพื่อทดสอบสิ่งที่แก้ไขไป
- การควบคุมจุดหยุดการทำงาน (Breakpoints / Interrupts) ในขั้นตอนการทดสอบกราฟ คุณสามารถใช้ LangSmith Studio เพื่อกำหนดจุดหยุด (Static interrupts) จากหน้า UI ได้เลย ทำให้คุณสามารถค่อยๆ รันการทำงานของกราฟไปทีละโหนด (Step through) และตรวจสอบข้อมูล State ในทุกๆ ขั้นตอนการประมวลผลได้อย่างละเอียด
- การทดสอบและประเมินผลอย่างเป็นระบบ (Evaluation) คุณสามารถนำข้อมูล Trace ที่ LangSmith บันทึกไว้ มาใช้สร้างชุดข้อมูลทดสอบ เพื่อทำการตรวจสอบและปรับปรุงประสิทธิภาพแอปพลิเคชัน LangGraph ของคุณได้อย่างต่อเนื่องและแม่นยำ
- การนำแอปพลิเคชันขึ้นสู่ระบบจริง (Production-ready Deployment) นอกจากฝั่งการพัฒนาแล้ว ยังมี LangSmith Deployment ซึ่งเป็นโครงสร้างพื้นฐานที่ถูกออกแบบมาเพื่อรองรับการ Deploy เอเจนต์ของ LangGraph ที่ทำงานแบบมี State และรันต่อเนื่องเป็นเวลานาน (Long-running) โดยเฉพาะ ช่วยให้การนำระบบขึ้น Production เป็นเรื่องง่ายและเชื่อถือได้มากขึ้น
ซึ่งจากประสบการณ์ส่วนตัวที่ทำมา และประสบการณ์ที่เห็นคนพัฒนา อย่าง LangSmith Studio นี่แทบจะเป็นเครื่องมือที่เรียกว่าใช้งานกันเป็นประจำเลย เพราะมัน debug สะดวกกว่าการ run ใน python ปกติมาก (จะให้ feel เหมือนพัฒนา application ทั่วไปเลย)
โดยสิ่งที่จะต้องมีเพื่อให้สามารถ run LangSmith Studio ได้ step แรกคือลง langgraph-cli ด้วย command
pip install -U "langgraph-cli[inmem]"จากนั้นเพิ่ม langgraph.json เข้าไป
{ "dependencies": ["."], "graphs": { "my_joke_agent": "./agent.py:graph" }, "env": ".env"}langgraph.json คือ Configuration file ในรูปแบบ JSON ที่ใช้สำหรับกำหนดโครงสร้างและส่วนประกอบต่างๆ ของ application LangGraph
ไฟล์นี้เปรียบเสมือนแผนผังที่บอกให้ระบบรู้ว่า application ของเราประกอบด้วยอะไรบ้าง ซึ่งจำเป็นอย่างมากใน 2 กรณีหลัก คือ:
- การทดสอบและพัฒนาผ่าน LangGraph CLI / Studio: หากเราต้องการรันเซิร์ฟเวอร์ (Agent Server) บนเครื่อง Local เพื่อทดสอบเอเจนต์ของคุณบน LangSmith Studio ตัว LangGraph CLI จะต้องใช้ไฟล์
langgraph.jsonเป็นตัวนำทางเพื่อค้นหาตำแหน่งของเอเจนต์และจัดการ library ที่เกี่ยวข้อง - การนำระบบขึ้นใช้งานจริง (Deployment): เมื่อคุณต้องการ Deploy application ผ่านบริการ Cloud ของ LangSmith Deployment จะบังคับให้ต้องมีไฟล์นี้ เพื่อให้รู้ว่าต้องเตรียมสภาพแวดล้อม โหลดกราฟ และติดตั้ง Dependencies อะไรบ้างสำหรับการรัน application
ภายในไฟล์ langgraph.json มักจะประกอบด้วยการตั้งค่าหลักๆ คือ
graphs: ใช้ระบุชื่อและเส้นทาง (Path) ไปยังไฟล์ code ของกราฟ (เช่น Compiled graph หรือฟังก์ชันที่ใช้สร้างกราฟ) เพื่อบอกให้ระบบรู้ว่ามีกราฟใดบ้างที่พร้อมให้เรียกใช้งานในโปรเจกต์นี้dependencies: ใช้ระบุตำแหน่งของไฟล์ที่เก็บรายชื่อแพ็กเกจที่ต้องติดตั้ง (เช่นrequirements.txtหรือpyproject.toml) ตลอดจนสามารถใช้คำสั่งเพิ่มเติมเพื่อระบุการติดตั้งไบนารีในระดับระบบ (System libraries) ได้ด้วยenv: ใช้สำหรับอ้างอิงและกำหนดค่าตัวแปรสภาพแวดล้อม (Environment variables) สำหรับแอปพลิเคชันที่รันอยู่บน Local (แต่สำหรับการใช้งานบน Production จริง มักจะไปกำหนดค่า Environment ผ่านระบบ Deployment แทน)
เพิ่ม .env ไปเพื่อปิดใช้งาน feature Tracing ก่อน
LANGSMITH_TRACING=false- ถ้าดูตามเอกสาร จะแนะนำให้เพิ่ม
LANGSMITH_API_KEYลงในไฟล์.envเมื่อใช้งาน LangSmith Studio ด้วยเหตุผลหลักคือ การมี API Key จะทำให้ Studio สามารถบันทึกและแสดงผลการทำงานของเอเจนต์ได้อย่างละเอียดครบถ้วน เช่น การดูพรอมต์ที่ถูกส่งไปยังโมเดล, ค่าพารามิเตอร์ของเครื่องมือ (Tool arguments), ผลลัพธ์ที่ส่งกลับมา, ข้อยกเว้นที่เกิดข้อผิดพลาด (Exceptions) ตลอดจนเมตริกเชิงลึกอย่างจำนวน Token และความหน่วงเวลา (Latency) ที่เกิดขึ้นในแต่ละขั้นตอนได้ (ไว้ตัวนี้เราจะมาลง detail กันเพิ่มอีกทีในอนาคต) - เพื่อให้สามารถ run local กันได้ก่อน โดยไม่ต้องมากังวลเรื่อง Key กัน เราจะให้เพิ่ม
LANGSMITH_TRACING=falseไปก่อนเพื่อปิดใช้ feature นี้
จากนั้นเมื่อเพิ่มทุกอย่างเรียบร้อย ทำการ run langsmith studio ด้วย command
langgraph devผลลัพธ์จากการ run ก็จะขึ้นมาว่า ทำการ publish API ออกไปแล้วเรียบร้อยที่ http://127.0.0.1:2024 เพียงเท่านี้ ตัว LangSmith Studio ก็จะสามารถเปิดโดยการ proxy เข้ามายัง base url นี้บน local ของเราได้
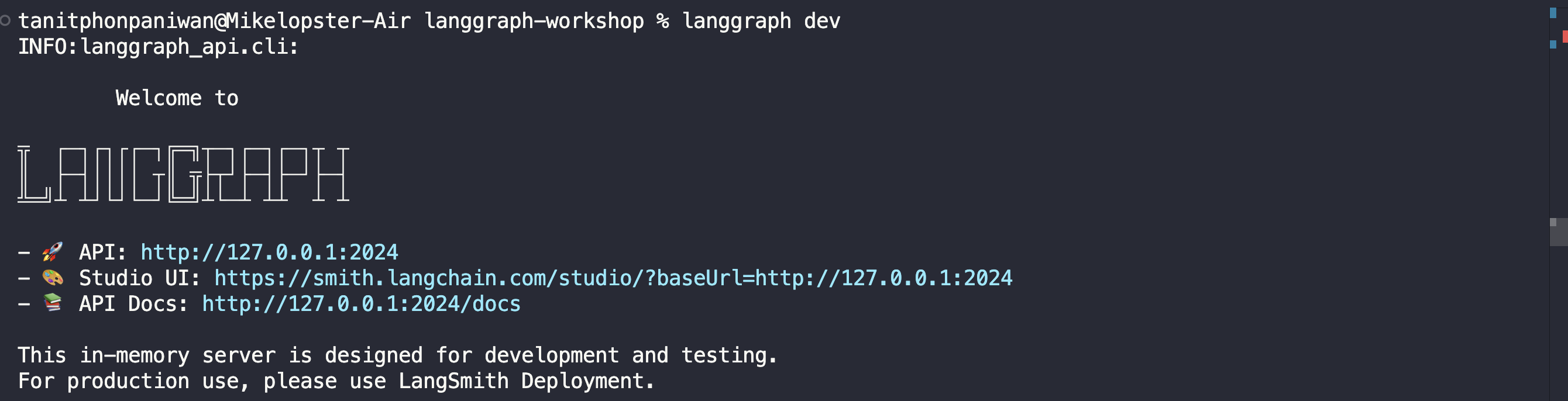 เมื่อเปิด url ตาม Studio UI (ซึ่งจริงๆ ถ้าตอน run คำสั่ง มันจะ auto เปิดขึ้นมาเลย) ก็จะเจอหน้าตาแบบนี้
เมื่อเปิด url ตาม Studio UI (ซึ่งจริงๆ ถ้าตอน run คำสั่ง มันจะ auto เปิดขึ้นมาเลย) ก็จะเจอหน้าตาแบบนี้
โดยก่อน สามารถทดลอง submit ได้เลยผ่าน LangSmith Studio แต่ต้องสมัครสมาชิกของ LangSmith Studio ก่อนนะ
- LangSmith สามารถสมัครได้ฟรีก่อน สำหรับการ development
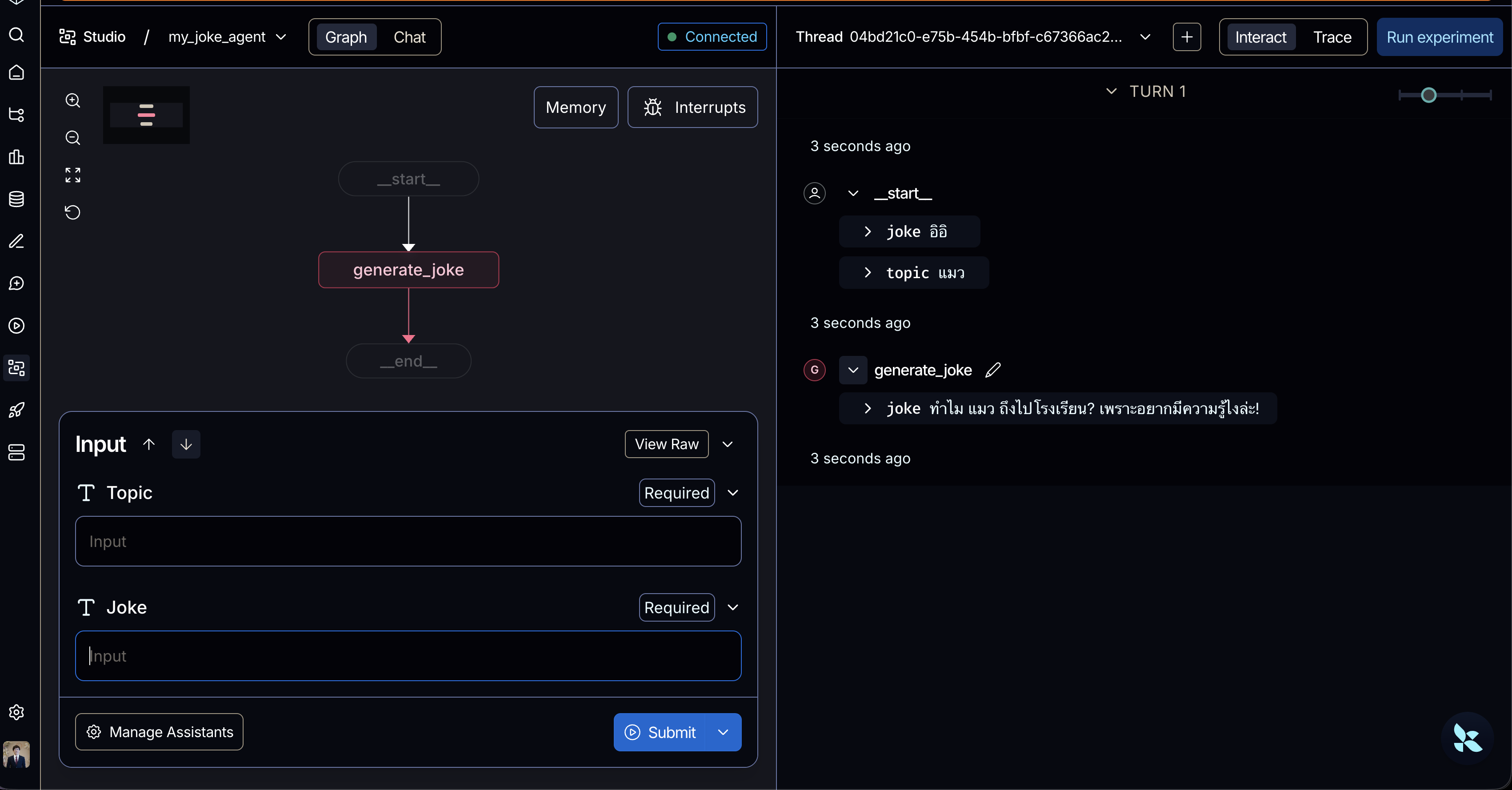 ซึ่งหน้าจอ UI ตรงตำแหน่ง input นี้ก็จะเปรียบเสมือนการทดแทนคำสั่ง
ซึ่งหน้าจอ UI ตรงตำแหน่ง input นี้ก็จะเปรียบเสมือนการทดแทนคำสั่ง .invoke()ที่เราเรียกกันใน function python เมื่อกี้ และ ด้านขวาเราก็จะเห็น step การทำงานเลยว่า มันเข้า node ไหนและทำงานยังไงบ้างออกมาได้
เพิ่ม LLM เข้ามา
อ่ะ ทีนี้เราจะลองเพิ่ม LLM เข้ามาบ้าง จากหัวข้อก่อนหน้าของ LangChain ผมได้ทำการเล่นคู่กับ Gemini LLM ไป ดังนั้น
- หากผมจะเปลี่ยนจากแต่เดิม
generate_jokeเป็นการ fixed code ให้กลายเป็นการ generate ผ่าน LLM โดยการส่งเป็น prompt เข้าไปใน llm ผ่านคำสั่งmodel.invoke(prompt)= ซึ่งมันก็คือท่าเดียวกับ LangChain นั่นเอง - แต่รอบนี้ ท่านี้ก็จะเป็นส่วนหนึ่งของการทำงานใน Node ที่เราจะต้องคืนผลลัพธ์ออกมาผ่าน State Graph แทน
ตาม code ด้านล่างนี้
from dotenv import load_dotenvfrom typing import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langchain_google_genai import ChatGoogleGenerativeAI # 1. นำเข้าโมเดล Gemini
load_dotenv()
# กำหนด State (หน่วยความจำส่วนกลาง)class State(TypedDict): topic: str joke: str
# 2. เรียกใช้งานโมเดล Geminimodel = ChatGoogleGenerativeAI(model="gemini-2.5-flash-lite")
# สร้าง Node (ฟังก์ชันการทำงานของเอเจนต์)def (state: State): topic = state["topic"]
# 3. ส่ง Prompt ไปให้ Gemini สร้างมุกตลก response = model.invoke([ {"role": "user", "content": f"ช่วยแต่งมุกตลกเกี่ยวกับ {topic} ให้หน่อย ขอแบบสั้นๆ ฮาๆ"} ])
# 4. แก้ไขตรงนี้: ดึงข้อความด้วย .content return {"joke": response.content}
# สร้าง StateGraph และประกอบร่าง (Wire it together)builder = StateGraph(State)
# เพิ่ม Node ลงไปในกราฟbuilder.add_node("generate_joke", generate_joke)
# กำหนดเส้นทางเดินของกราฟbuilder.add_edge(START, "generate_joke")builder.add_edge("generate_joke", END)
# Compile เพื่อให้กราฟพร้อมใช้งานgraph = builder.compile()ผลลัพธ์ผ่าน LangSmith Studio
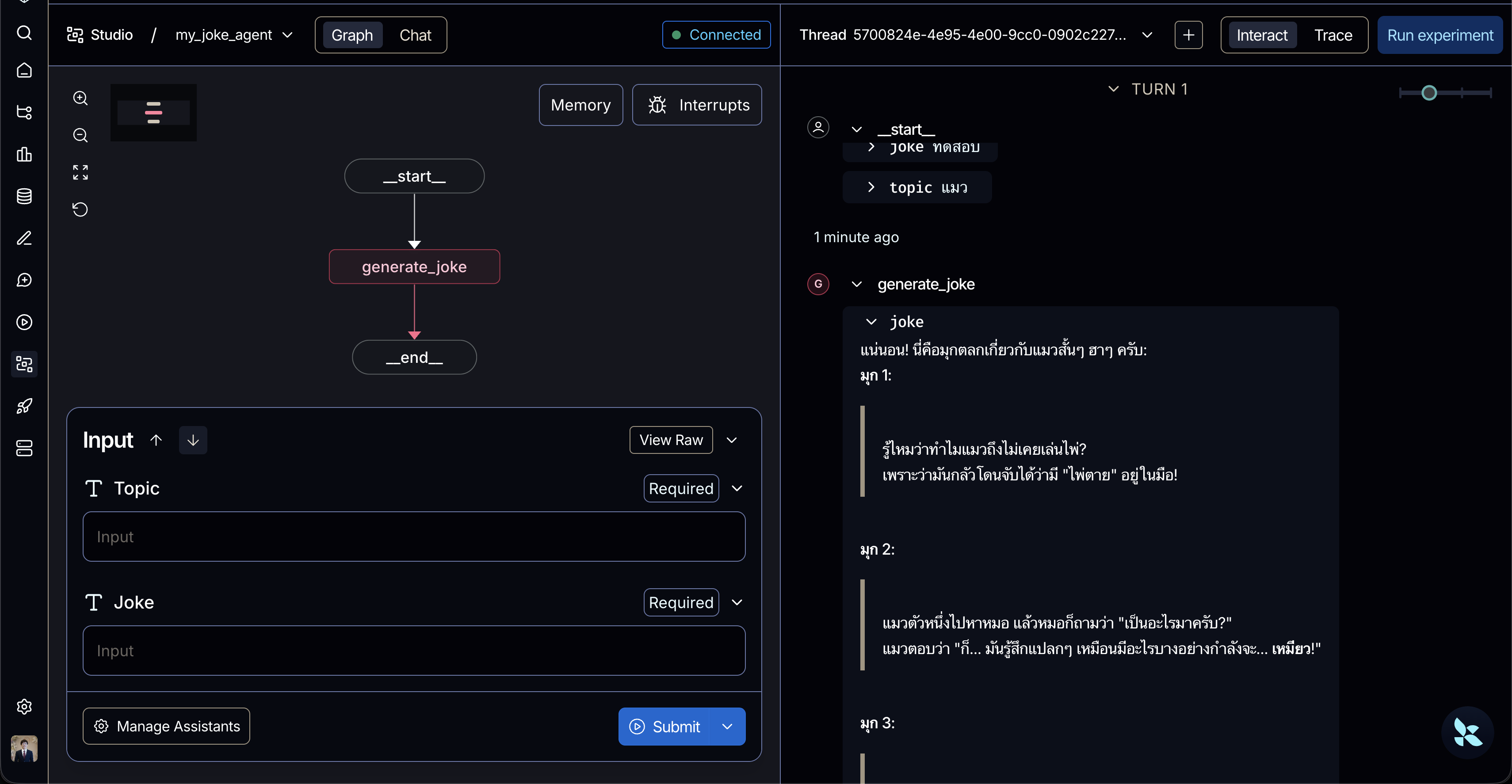
Example 2 - Persistence & checkpoint
ต่อมา มาสู่เรื่อง Persistence และ Checkpoint ซึ่งเป็นกลไกสำคัญใน LangGraph ที่ทำหน้าที่เสมือนระบบ “บันทึกความจำและเซฟความคืบหน้า” ของ application กัน
- Persistence (ระบบบันทึกสถานะ): คือชั้นการทำงาน (Layer) ที่ถูกสร้างมาเพื่อใช้บันทึกสถานะ (State) ของกราฟอย่างเป็นระบบ ระบบนี้มีความสำคัญมากเพราะเป็นตัวขับเคลื่อนฟีเจอร์ระดับสูง เช่น ระบบความจำระหว่างการสนทนา (Memory), การหยุดเพื่อรอการตัดสินใจจากมนุษย์ (Human-in-the-loop), การย้อนเวลากลับไปดูประวัติ (Time travel), ตลอดจนช่วยให้ระบบสามารถทำต่อจากจุดเดิมได้หากเกิดข้อผิดพลาด (Fault-tolerance)
- Checkpoint (จุดบันทึกสถานะ): คือข้อมูล “ภาพถ่ายสถานะ (Snapshot)” ของกราฟที่ถูกบันทึกไว้ ณ จุดเวลาหนึ่งๆ (โดยปกติจะบันทึกทุกครั้งเมื่อจบแต่ละรอบการทำงาน หรือ Super-step)
หัวใจสำคัญมีเพียง 2 ส่วนคือ การใส่ Checkpointer ตอน Compile และ การระบุ thread_id ตอนเรียกใช้งาน (Invoke)
เราจะลองเล่นผ่านตัวอย่างง่ายๆนั่นคือการเก็บ logs ของการพูดคุยกันก่อน
- เราจะทำการสร้าง State สำหรับเก็บ
logsเอาไว้เป็น list เพื่อให้สามารถนำข้อความมาต่อกันได้ - จากนั้นสร้าง Node
add_logสำหรับค่อยๆต่อข้อมูลเข้า Log เรื่อยๆ - สิ่งที่เราจะทำคือ เราจะทำการบันทึกข้อมูล log เอาไว้ต่อกันเรื่อยๆ หากมีการเรียกใน thread เดิมอยู่ ข้อความเดิมจะต้องไม่หายไป
import operatorfrom typing import TypedDict, Annotatedfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.checkpoint.memory import MemorySaver # 1. นำเข้า Checkpointer
# 1. กำหนด State# ใช้ Annotated และ operator.add เพื่อให้ข้อมูลใหม่ "ต่อท้าย" List เดิมเสมอ (ไม่เขียนทับ)class State(TypedDict): logs: Annotated[list[str], operator.add]
# 2. สร้าง Node ง่ายๆdef add_log(state: State): last_item = state["logs"][-1] # ดึงข้อความล่าสุดมาต่อท้ายด้วยคำว่า "รับทราบ:" return {"logs": [f"รับทราบ: {last_item}"]}
# 3. ประกอบร่าง StateGraphbuilder = StateGraph(State)builder.add_node("add_log", add_log)builder.add_edge(START, "add_log")builder.add_edge("add_log", END)
# 4. *** จุดสำคัญ *** สร้าง Checkpointer สำหรับเก็บข้อมูลลง RAMmemory = MemorySaver()
# 5. Compile กราฟพร้อมกับใส่ Checkpointer เข้าไปgraph = builder.compile(checkpointer=memory) # [2]
# ==========================================# ส่วนทดสอบรัน# ==========================================if __name__ == "__main__": # การจะใช้ Checkpointer ได้ ต้องมี config ที่ระบุ thread_id เสมอ [1] # thread_id เปรียบเสมือนรหัสห้องแชท หรือรหัสเซสชันของผู้ใช้ config_user_1 = {"configurable": {"thread_id": "user-1"}}
print("--- ส่งข้อความครั้งที่ 1 (User 1) ---") result1 = graph.invoke({"logs": ["สวัสดีกราฟ"]}, config=config_user_1) print(result1["logs"])
print("\n--- ส่งข้อความครั้งที่ 2 (User 1) ---") # สังเกตว่าเราส่งแค่ "กินข้าวหรือยัง" เข้าไป แต่กราฟจะจำ "สวัสดีกราฟ" ได้ด้วย result2 = graph.invoke({"logs": ["กินข้าวหรือยัง"]}, config=config_user_1) print(result2["logs"])
print("\n--- เปลี่ยน Thread (User 2) ---") # เมื่อเปลี่ยน thread_id กราฟจะถือว่าเป็นเซสชันใหม่ เริ่มต้นความจำใหม่ [1] config_user_2 = {"configurable": {"thread_id": "user-2"}} result3 = graph.invoke({"logs": ["ทักทายจากผู้ใช้คนที่ 2"]}, config=config_user_2) print(result3["logs"])จากตัวอย่าง code นี้ step ที่เราทำเพิ่มมาจากการทำ Agent ปกติคือ
1. การเตรียม Checkpointer และประกอบร่างกราฟ
- ใน code มีการใช้
MemorySaver()ซึ่งเป็น Checkpointer แบบเก็บข้อมูลลงหน่วยความจำหลัก (RAM) ที่เหมาะสำหรับการทดสอบ - การจะเปิดใช้งาน Persistence ทำได้ง่ายๆ เพียงแค่นำ Checkpointer ไปใส่ไว้ในขั้นตอน Compile กราฟ (
graph = builder.compile(checkpointer=memory)) หลังจากบรรทัดนี้ กราฟของคุณจะเริ่มบันทึก Checkpoint ของข้อมูล State โดยอัตโนมัติ
2. หัวใจสำคัญคือ thread_id
- เมื่อคุณสร้างกราฟแบบมี Checkpointer ระบบจะบังคับให้คุณต้องระบุ thread_id ลงใน config เสมอก่อนที่จะสั่งรันกราฟ (Invoke)
thread_idเปรียบเสมือน “รหัส Session” หรือ “รหัสห้องแชท” ที่ Checkpointer ใช้เป็นกุญแจหลัก (Primary key) ในการบันทึกและดึงข้อมูล Checkpoint ขึ้นมาใช้งาน
3. การทำงานของระบบความจำระยะสั้น (Short-term Memory)
- ครั้งที่ 1: เมื่อรันกราฟด้วย
thread_id: "user-1"พร้อมข้อความ “สวัสดีกราฟ” ระบบจะประมวลผล (ผ่านฟังก์ชันadd_log) และเซฟ State ล่าสุดเก็บไว้ใน Checkpoint ที่ผูกกับ user-1 - ครั้งที่ 2: เมื่อรันข้อความ “กินข้าวหรือยัง” ด้วย
thread_id: "user-1"เหมือนเดิม ระบบจะรู้ทันทีว่าต้องไปดึง Checkpoint เก่าของ user-1 มาเป็นตัวตั้งต้น - ผลลัพธ์คือ กราฟจำข้อความเก่าได้ ซึ่งกลไกนี้ทำงานร่วมกับการที่เราใช้
Annotated[list[str], operator.add]ในการประกาศ State เพื่อบอกว่า “ให้เอาข้อมูลใหม่มา ต่อท้าย (Append) ข้อมูลเดิมเสมอ ห้ามเขียนทับ” จึงเกิดเป็นประวัติการสนทนาที่ยาวขึ้นเรื่อยๆ
4. การแยกความจำตามเซสชันของผู้ใช้
- เมื่อถึงส่วน เปลี่ยน Thread (User 2) โค้ดได้ทำการกำหนด
thread_id: "user-2" - เนื่องจากรหัส Thread ไม่ตรงกับของเดิม ระบบ Checkpointer จะถือว่าเป็นเซสชันใหม่ที่ว่างเปล่า และไม่มีประวัติใดๆ ผูกอยู่ ทำให้ข้อความของ “ผู้ใช้คนที่ 2” จะเริ่มต้นความจำใหม่โดยไม่ปะปนกับความจำของ “ผู้ใช้คนที่ 1” ครับ
สำหรับฉบับของ LangSmith Studio เนื่องจากการพูดคุยนั้นมีการแบ่งเป็น Thread อยู่แล้ว นั่นคือตราบเท่าที่เรายังไม่เปลี่ยน Thread ใหม่ State ของ logs ก็จะยังคงสะสมไปเรื่อยๆ โดยสามารถดูได้จากตรง View State ได้
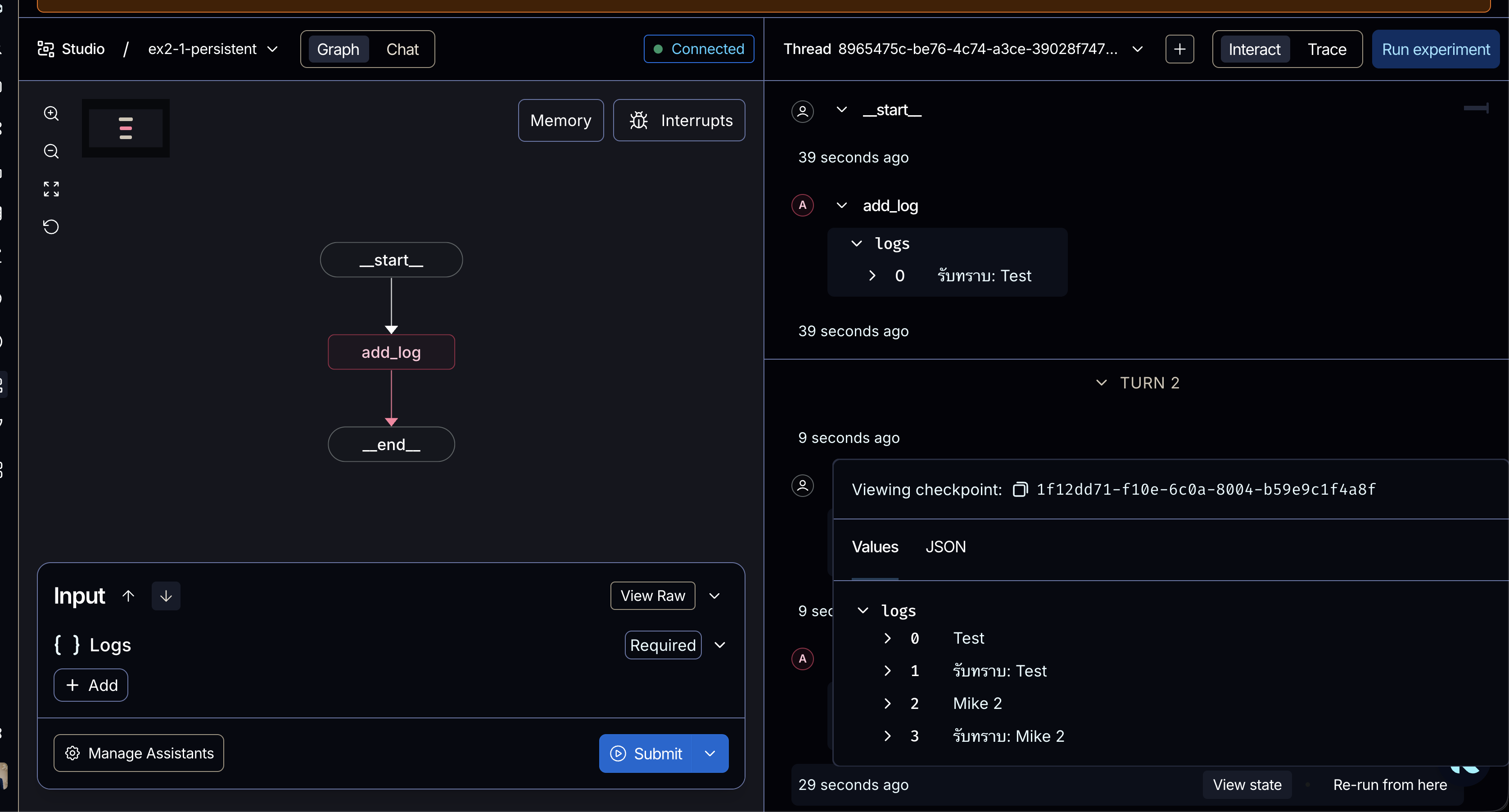 เพิ่มเติมหากรัน LangSmith Studio ด้วย langgraph dev ตัว platform จะทำการจัดการเรื่อง Persistence (Checkpointer) ให้โดยอัตโนมัติอยู่แล้ว
เพิ่มเติมหากรัน LangSmith Studio ด้วย langgraph dev ตัว platform จะทำการจัดการเรื่อง Persistence (Checkpointer) ให้โดยอัตโนมัติอยู่แล้ว
ดังนั้น เราไม่จำเป็นต้องระบุตัวสำหรับเก็บ checkpointer เหมือนเวลาเรา run ผ่าน python แต่สามารถระบุให้เหลือแค่ builder.compile() ตาม code ด้านล่างนี้ได้ ตัว LangSmith Studio ก็จะทำการเก็บข้อมูลเข้า Memory โดยอัตโนมัติเข้าไป
# จากตรง compile graph# checkpointer = MemorySaver()# graph = builder.compile(checkpointer=checkpointer)
# เหลือแค่นี้พอgraph = builder.compile()case - human in the loop confirm
ทีนี้ด้วยความสามารถของ Persistence ที่สามารถจดจำ State ใน Thread นั้นๆได้ = เราสามารถ break ขั้นตอนบางอย่างก่อน เพื่อให้เกิด interupt บางอย่าง ก่อนจะทำขั้นตอนต่อไปได้ โดยข้อมูลใน State ยังไม่หาย
ก็จะสามารถนำมาสู่ตัวอย่างอีกอันหนึ่งซึ่งก็คือการเพิ่ม action “human in the loop” เข้ามา นั่นคือการทำ Approval Workflow
code ตัวอย่างนี้เป็นการจำลองระบบ Approval Workflow ซึ่งแสดงให้เห็นถึงการทำงานร่วมกันระหว่าง **Human-in-the-loop , Persistence และการใช้ Command ภายใน Node เพื่อควบคุมทิศทาง
Agent ด้านล่างนี้เป็น Agent จำลองการรับ Action บางอย่างเข้ามาโดย
- มี State สำหรับรับ Action เข้ามา (เป็น
InputState) โดย state นี้จะโดนส่งต่อไปยังApprovalStateเป็นข้อมูล action พร้อมกับ status เริ่มต้นคือpending - step ต่อมา need action จาก user ที่จะต้อง approve ก่อนว่าจะให้ ผ่าน (ส่งค่า True กลับมา) หรือ ไม่ผ่าน (ส่งค่า False หรืออะไรก็ได้ที่ไม่ใช่ True กลับมา)
- และก็จะสรุปเป็นผลลัพธ์สุดท้ายออกมาว่า action นั้นผ่าน (proceed) หรือไม่ผ่าน (cancel)
from dataclasses import dataclassfrom typing import Optional, Literal, TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.types import Command, interrupt
# 1. กำหนด Input Schema (สิ่งที่จะให้โชว์ในฟอร์มหน้า LangSmith Studio)class InputState(TypedDict): action_details: str
# 2. กำหนด Overall State (สถานะภายในทั้งหมดที่กราฟต้องใช้ทำงานจริง)@dataclassclass ApprovalState: action_details: str # ค่า default ยังคงทำงานเป็น "pending" เหมือนเดิม status: Optional[Literal["pending", "approved", "rejected"]] = "pending"
# 3. สร้าง Node การทำงาน (ดึงข้อมูลผ่าน state.<key> เหมือนเดิมเพราะใช้ dataclass)def approval_node(state: ApprovalState) -> Command[Literal["proceed", "cancel"]]: decision = interrupt({ "question": "Approve this action?", "details": state.action_details, })
if decision is True: return Command(goto="proceed") else: return Command(goto="cancel")
def proceed_node(state: ApprovalState): return {"status": "approved"}
def cancel_node(state: ApprovalState): return {"status": "rejected"}
# 4. ตอนสร้าง StateGraph ให้ระบุ Overall State ควบคู่กับ Input Schema แยกกัน# สังเกตการใส่พารามิเตอร์ input=InputStatebuilder = StateGraph(ApprovalState, input=InputState)
builder.add_node("approval", approval_node)builder.add_node("proceed", proceed_node)builder.add_node("cancel", cancel_node)
builder.add_edge(START, "approval")builder.add_edge("proceed", END)builder.add_edge("cancel", END)
# Compile กราฟcheckpointer = MemorySaver()graph = builder.compile(checkpointer=checkpointer)จาก code
- ใน LangGraph การจะทำ Human-in-the-loop ได้นั้น จำเป็นต้องมีระบบ Persistence (Checkpointer) เสมอ
- เมื่อกราฟทำงานมาถึงโหนด
approval_nodeโค้ดจะเรียกใช้ฟังก์ชันinterrupt(...)สิ่งที่เกิดขึ้นเบื้องหลังคือ กราฟจะหยุดการทำงานทันที และนำสถานะปัจจุบันของกราฟ (ข้อมูลในApprovalState) ไปบันทึกเก็บไว้ในMemorySaver()(Checkpointer) - หลังจากบันทึกสถานะเสร็จ กราฟจะหยุดรอคำตอบจากมนุษย์โดยจะไม่ process ต่อ โดยจะส่งข้อมูล
questionและdetailsออกไปแสดงผลบนหน้า UI (เช่น LangSmith Studio) เพื่อให้มนุษย์ตัดสินใจ - เมื่อมนุษย์ตรวจสอบข้อมูลและส่งคำตอบกลับมา (เช่น อนุมัติ
Trueหรือ ปฏิเสธFalse) คำตอบนั้นจะถูกส่งกลับเข้าไปในกราฟผ่านCommand(resume=...)ระบบจะโหลด Checkpoint เดิมขึ้นมาทำงานต่อ โดยนำคำตอบนั้นไปใส่ไว้ในตัวแปรdecisionและประมวลผลโค้ดบรรทัดถัดไปได้ทันที
เพิ่มเติมสำหรับคำสั่ง Command
Commandคือ Object พิเศษใน LangGraph ที่ใช้สำหรับ ควบคุมทิศทางการทำงานของกราฟ (Control flow) และ การอัปเดตสถานะ (State updates)- ในโค้ดชุดนี้และในการทำงานของ Human-in-the-loop ตัว
Commandมีบทบาทสำคัญใน 2 ส่วน คือ- ใช้เพื่อกำหนดเส้นทางถัดไปจากภายในโหนด: (
goto) ในโหนดapproval_nodeแทนที่เราจะต้องไปเขียนเงื่อนไขการแยกเส้นทาง (Conditional Edges) ให้วุ่นวายตอนประกอบกราฟ เราสามารถใช้return Command(goto="proceed")หรือCommand(goto="cancel")เพื่อสั่งให้กราฟกระโดดไปยังโหนดที่ต้องการได้โดยตรงจากภายในฟังก์ชันเลย - ใช้เพื่อส่งค่ากลับเข้าไปในกราฟเมื่อต้องการทำต่อ: (
resume) แม้ในโค้ดจะไม่ได้แสดงส่วนการรัน แต่เวลาที่เราต้องการตอบกลับinterruptเพื่อให้กราฟเดินต่อ เราจะต้องสั่งรันกราฟใหม่โดยผ่านค่าresumeเข้าไปในCommandเช่น: ค่าTrueในCommand(resume=True)จะกลายไปเป็นผลลัพธ์ของฟังก์ชันinterrupt()และถูกเก็บลงในตัวแปรdecisionในที่สุด
- ใช้เพื่อกำหนดเส้นทางถัดไปจากภายในโหนด: (
รวมถึงใน code นี้เรามีการเพิ่มเติมอีก 1 เรื่องคือการประยุกต์ใช้หลาย state ร่วมกัน จาก builder = StateGraph(ApprovalState, input=InputState) โดย
- ApprovalState (Internal / Overall State): คือโครงสร้างข้อมูลส่วนกลางที่ใช้ “ภายใน” ของกราฟทั้งหมด เป็นสถานะที่โหนดต่างๆ ภายในกราฟใช้เพื่ออ่านและเขียนข้อมูลหากันระหว่างที่กราฟกำลังทำงาน
- input=InputState (Input Schema): คือการกำหนดโครงสร้างข้อมูล “ฝั่งขาเข้า” ที่กราฟอนุญาตให้ผู้ใช้ส่งเข้ามาตอนเริ่มต้นรันกราฟ ทำหน้าที่เหมือนตัวกรองเพื่อบังคับว่า input ต้องมีโครงสร้างตามนี้เท่านั้น
อย่างเคสนี้ เหตุผลที่ต้องใช้แยกกัน เพราะเราต้องการให้ผู้ใช้ส่งเข้ามาแค่ action_details (ตามที่นิยามใน InputState) แต่เราไม่ต้องการให้ผู้ใช้ตั้งค่า status เองตั้งแต่แรก การแยก State ทำให้ระบบสามารถรับแค่ค่าที่จำเป็น แล้วนำไปรวมเข้ากับ Internal State (ApprovalState) ที่มีระบบจัดการค่าเริ่มต้น (default) ของ status เป็น “pending” ไว้ให้แล้วเบื้องหลัง
ซึ่งจริงๆ LangGraph นั้น support การใส่ State ไว้ทั้งหมด 3 แบบคือ Internal State, Input Schema และเพิ่ม Output Schema เข้าไปได้ เช่นแบบด้านล่างนี้ก็ได้เช่นกัน
builder = StateGraph(OverallState, input=InputState, output=OutputState)มาลองทดสอบผลลัพธ์ผ่าน command กันก่อน
- ถ้าลองผ่าน command เราต้องเรียก
graph.invoke(Command(resume=True), config=config)ซ้ำอีกรอบในจังหวะที่มีการ interrupt เกิดขึ้น
if __name__ == "__main__": # หมายเหตุ: หากจะรันไฟล์นี้ตรงๆ ผ่าน Terminal ต้องใช้ Checkpointer นะครับ
# กำหนด Thread ID เสมอ config = {"configurable": {"thread_id": "approval-123"}}
print("--- รันครั้งที่ 1: ส่งคำสั่งและหยุดรอการอนุมัติ ---") initial = graph.invoke( # ส่งแค่ action_details ตามที่กำหนดไว้ใน InputState [3] {"action_details": "โอนเงินจำนวน $500"}, config=config, ) # ระบบจะคืนค่าสถานะการหยุดชะงัก (Interrupt) ออกมาให้ดู [4] print(initial["__interrupt__"])
print("\n--- รันครั้งที่ 2: มนุษย์กดอนุมัติ (Resume) ---") # สมมติว่ามนุษย์กดยืนยัน เราจะสั่งรันกราฟอีกครั้งด้วย Command(resume=True) [4, 5] resumed = graph.invoke(Command(resume=True), config=config)
# ระบบจะไปทำงานที่ proceed_node และได้สถานะเป็น approved # (หมายเหตุ: หากใช้ dataclass ในเวอร์ชันใหม่ ผลลัพธ์อาจจะอยู่ในรูปแบบ Object ให้ใช้ resumed.status แทน) try: print(f"สถานะล่าสุด: {resumed['status']}") except TypeError: print(f"สถานะล่าสุด: {resumed.status}")แต่ถ้าลองผ่าน LangSmith Studio นั้นมันจะขึ้นเป็นหน้าจอให้ใส่ข้อมูลเลยว่าจะ approve หรือไม่แบบนี้ขึ้นมาได้เลย
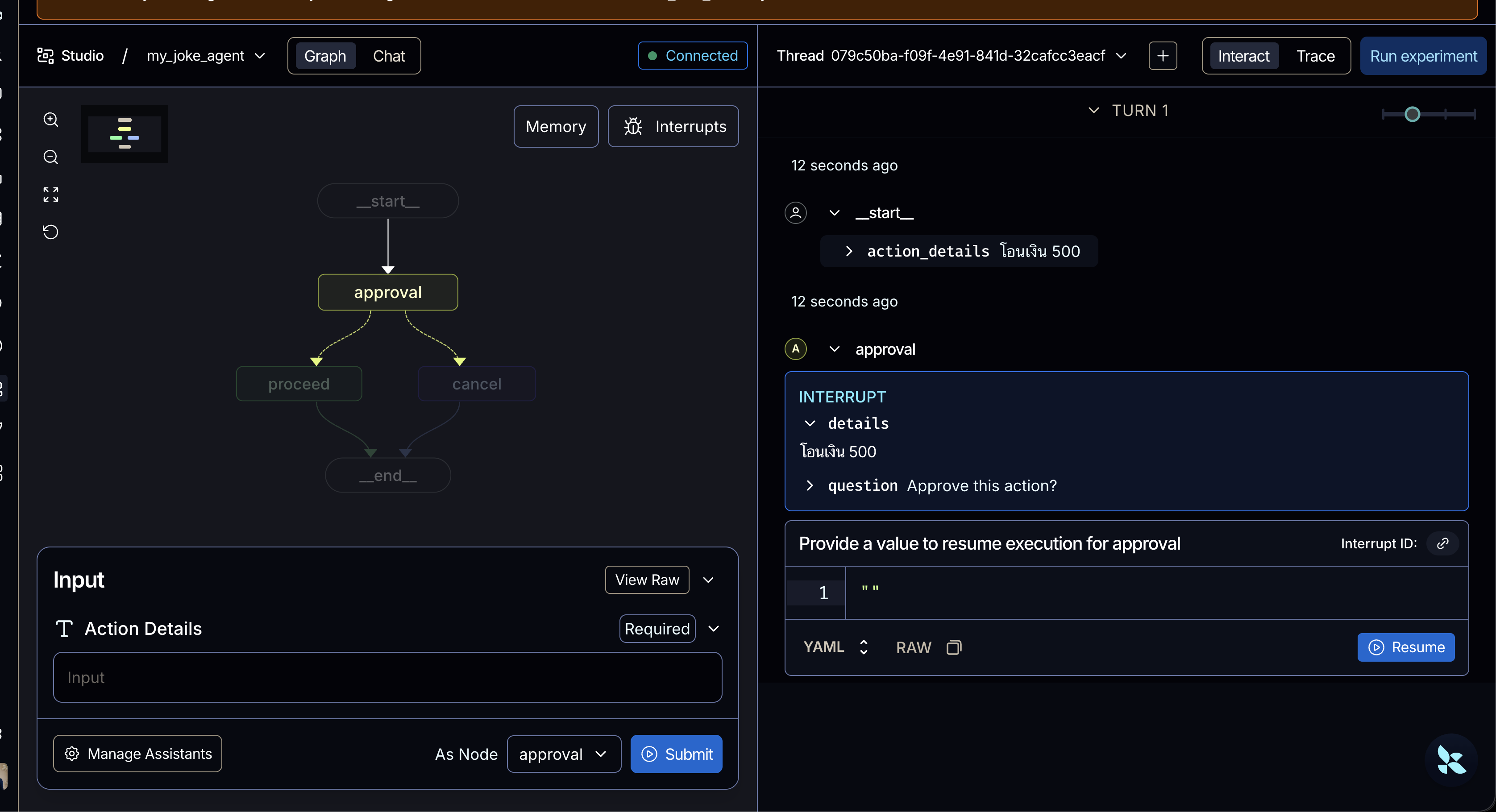
Example 3 - Long term memory
เคสนี้จะเป็น เคส “จำข้อมูลข้าม Thread” (เช่น การเปิดห้องแชทใหม่หรือ Thread ใหม่ แต่ระบบยังจำชื่อเราได้) ใน LangGraph จะเรียกว่าการทำ Long-term memory (ความจำระยะยาว)
โดยปกติแล้ว Checkpointer (MemorySaver) จะจำข้อมูลแยกตาม thread_id (ห้องแชท) แต่ถ้าเราต้องการให้ข้อมูลแชร์ข้ามกันได้ เราจะต้องใช้ Store (เช่น InMemoryStore) เข้ามาช่วยเพื่อบันทึกข้อมูลผูกกับ user_id (ตัวผู้ใช้) แทนครับ
Agent ต่อมาที่เราจะทำคือ เราจะสร้าง Agent สำหรับการจำชื่อผู้ใช้ไว้โดย
- ขั้นแรกหากไม่มีชื่อ > ให้ถามมาก่อนว่า “ชื่ออะไร” เพื่อบันทึกข้อมูลเข้าไป
- หลังจากมีชื่อแล้ว หากลองทักดู แม้จะไม่ส่งชื่อไป ต้องสามารถส่งชื่อเดิมมาได้
Code ก็จะมีหน้าตาประมาณนี้
from typing import TypedDict, Optionalfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.checkpoint.memory import MemorySaverfrom langgraph.store.memory import InMemoryStorefrom langgraph.store.base import BaseStorefrom langchain_core.runnables import RunnableConfig # 1. อิมพอร์ตคลาสนี้เข้ามาเพิ่ม
# 1. กำหนด Stateclass State(TypedDict): input_name: Optional[str] reply: str
# 2. สร้าง Node ที่เข้าถึง Store ได้# แก้ไขจาก config: dict เปลี่ยนเป็น config: RunnableConfigdef chat_node(state: State, config: RunnableConfig, store: BaseStore): # ดึง user_id จาก config ได้ตามปกติ user_id = config["configurable"].get("user_id", "anonymous")
# กำหนด Namespace สำหรับเก็บข้อมูลของ user คนนี้ namespace = (user_id, "memories")
if state.get("input_name"): name = state["input_name"] store.put(namespace, "user_profile", {"name": name}) return {"reply": f"รับทราบครับ บันทึกชื่อคุณ {name} เรียบร้อยแล้ว!"}
memories = store.search(namespace)
if memories: saved_name = memories[-1].value["name"] return {"reply": f"สวัสดีอีกครั้งครับคุณ {saved_name}! เปิดแชทใหม่มีอะไรให้ช่วยไหมครับ?"} else: return {"reply": "สวัสดีครับ! คุณชื่ออะไรหรอครับ?"}
# 3. ประกอบร่าง StateGraphbuilder = StateGraph(State)builder.add_node("chat", chat_node)builder.add_edge(START, "chat")builder.add_edge("chat", END)
# 4. *** จุดสำคัญ *** สร้างทั้ง Checkpointer และ Storecheckpointer = MemorySaver()store = InMemoryStore()
# 5. Compile กราฟพร้อมใส่ checkpointer และ store เข้าไปgraph = builder.compile(checkpointer=checkpointer, store=store)หลักการทำงานและวิธีที่ code นี้ใช้จดจำชื่อข้าม Thread สามารถอธิบายได้เป็น 4 ส่วนสำคัญคือ 1. การติดตั้งและการเข้าถึง Store (Long-term memory)
- ในโค้ดมีการสร้าง
store = InMemoryStore()ขึ้นมาทำงานคู่กับMemorySaver() - เมื่อนำ
storeไปใส่ตอนรวบรวมกราฟgraph = builder.compile(..., store=store)ระบบของ LangGraph จะจัดการ **ส่งต่อ (Inject) object store เข้าไปในทุกๆ โหนดให้โดยอัตโนมัติ ทำให้ฟังก์ชันchat_nodeสามารถประกาศรับพารามิเตอร์store: BaseStoreเพื่อดึงความจำระยะยาวมาใช้งานได้ทันที
2. การใช้ Namespace เพื่อแยกความจำตาม User (ไม่ใช่ Thread)
- แทนที่จะจำข้อมูลตาม
thread_id(ซึ่งถ้าเริ่มแชทใหม่ ข้อมูลจะหาย) โค้ดนี้เปลี่ยนมาดึงค่า user_id จากconfig["configurable"]แทน - จากนั้นนำ
user_idมาสร้างเป็น Namespace (พื้นที่จัดเก็บย่อย) ในรูปแบบ Tuple เช่น("user_123", "memories")ซึ่ง Namespace นี้แหละที่เป็นกุญแจสำคัญที่ทำให้ระบบรู้ว่า “นี่คือลิ้นชักความจำของนาย A” ไม่ว่านาย A จะเปิด Thread ใหม่กี่ครั้งก็ตาม
3. การบันทึกข้อมูลชื่อลงความจำระยะยาว (store.put)
- เมื่อมีข้อมูล
state["input_name"]ส่งเข้ามา โหนดจะใช้คำสั่ง store.put(namespace, “user_profile”, {“name”: name}) - ความหมายคือ สั่งให้ระบบนำข้อมูลดิกชันนารี
{"name": name}ไปเซฟไว้ใน Namespace ของผู้ใช้คนนี้ โดยตั้งชื่อไฟล์/กุญแจอ้างอิงให้มันว่า"user_profile"
4. การดึงข้อมูลชื่อกลับมาใช้แม้เปิด Thread ใหม่ (store.search)
- ในกรณีที่ผู้ใช้เปิด Thread ใหม่ หรือไม่มีข้อมูล
input_nameส่งมา โหนดจะใช้คำสั่ง store.search(namespace) เพื่อค้นหาความจำทั้งหมดที่อยู่ในกล่อง Namespace ของผู้ใช้คนนั้น - ข้อมูลที่ระบบคืนค่ากลับมาจะอยู่ในรูปแบบของ List ที่บรรจุออบเจกต์ความจำไว้ (เรียงจากเก่าไปใหม่) โค้ดจึงดึงข้อมูลล่าสุดด้วย
memories[-1]และเข้าถึงข้อมูลที่ถูกเซฟไว้ผ่านแอตทริบิวต์.value["name"]ทำให้สามารถตอบกลับด้วยการทักทายชื่อผู้ใช้ได้ทันที แม้ว่าจะเป็นการคุยใน Thread ใหม่ที่กราฟไม่เคยรู้จักมาก่อนก็ตามครับ
ทดสอบ run code แบบ python กันก่อน
if __name__ == "__main__":
# --- รันครั้งที่ 1 (Thread ที่ 1) --- # ตั้งค่าให้เป็น session ของ "thread-1" และเป็นของ "user-123" config_thread_1 = {"configurable": {"thread_id": "thread-1", "user_id": "user-123"}}
print("--- แชทห้องที่ 1 ---") res1 = graph.invoke({"input_name": "สมชาย"}, config=config_thread_1) print("Bot:", res1["reply"])
# --- รันครั้งที่ 2 (Thread ที่ 2) --- # จำลองการผู้ใช้ปิดแชทแล้วเปิดห้องใหม่ (เปลี่ยน thread_id เป็น "thread-2") # แต่ยังคงเป็นผู้ใช้คนเดิม (user_id เป็น "user-123" เหมือนเดิม) config_thread_2 = {"configurable": {"thread_id": "thread-2", "user_id": "user-123"}}
print("\n--- แชทห้องที่ 2 (ผู้ใช้คนเดิม) ---") # ไม่ได้ส่ง input_name เข้าไปแล้ว res2 = graph.invoke({"input_name": None}, config=config_thread_2) print("Bot:", res2["reply"])
# --- รันครั้งที่ 3 (ผู้ใช้คนใหม่) --- config_thread_3 = {"configurable": {"thread_id": "thread-3", "user_id": "user-999"}}
print("\n--- แชทห้องที่ 3 (ผู้ใช้คนใหม่) ---") res3 = graph.invoke({"input_name": None}, config=config_thread_3) print("Bot:", res3["reply"])โดยสำหรับ LangSmith นั้นก็เหมือนกับเคสก่อนหน้าของ Persistent คือ ไม่ต้องกำหนด Store, Memory มา เนื่องจาก LangSmith มี feature นี้อยู่แล้ว สามารถให้ code build เหลือแค่ graph = builder.compile() ได้เลย
แต่จะต้องมากำหนดผ่าน Configuration ตรง New Assistant (จะเหมือนกับเวลาเราใส่ข้อมูลผ่าน config แบบตอนเรียก graph.invoke) ให้มีข้อมูล user_id
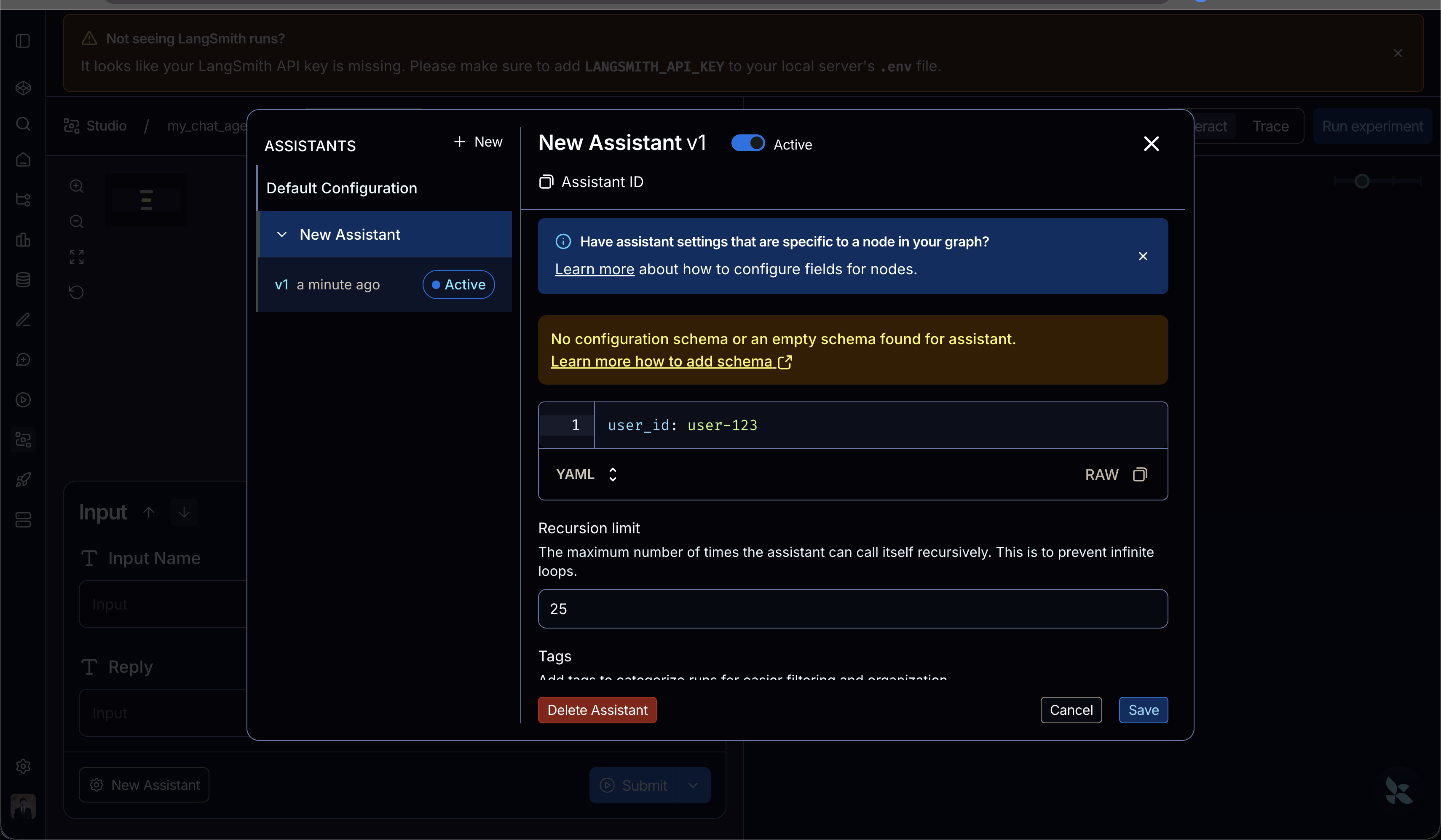
เพื่อให้เวลาที่เกิดการพูดคุยใน Thread ข้อมูลจะสามารถจัดเก็บลง namespace และ key ตามที่กำหนดได้อย่างถูกต้องใน Memory ของ LangSmith Studio
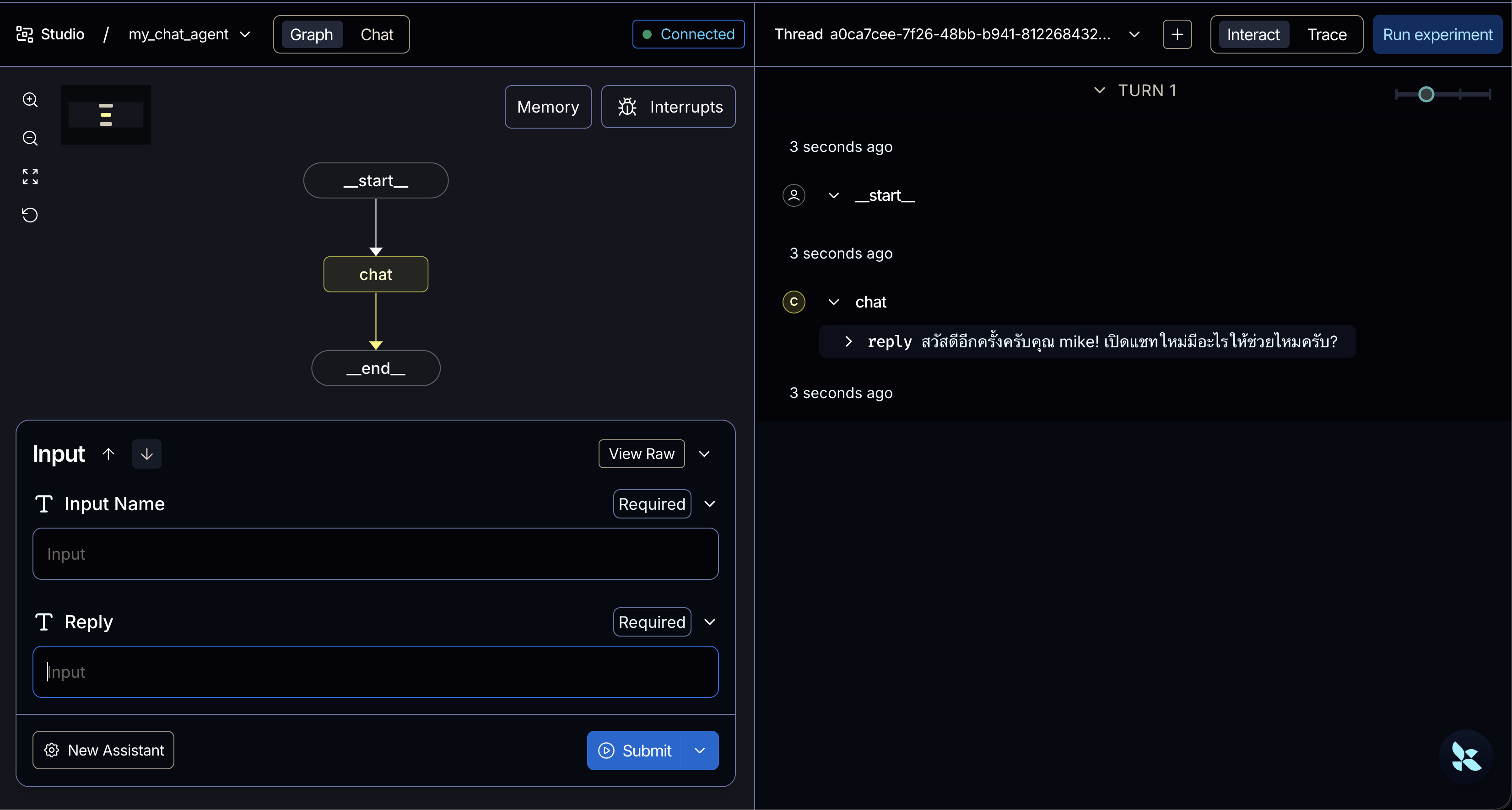
เช่นอย่างอันนี้คือ input ชื่อ mike ครั้งแรกเข้าไป
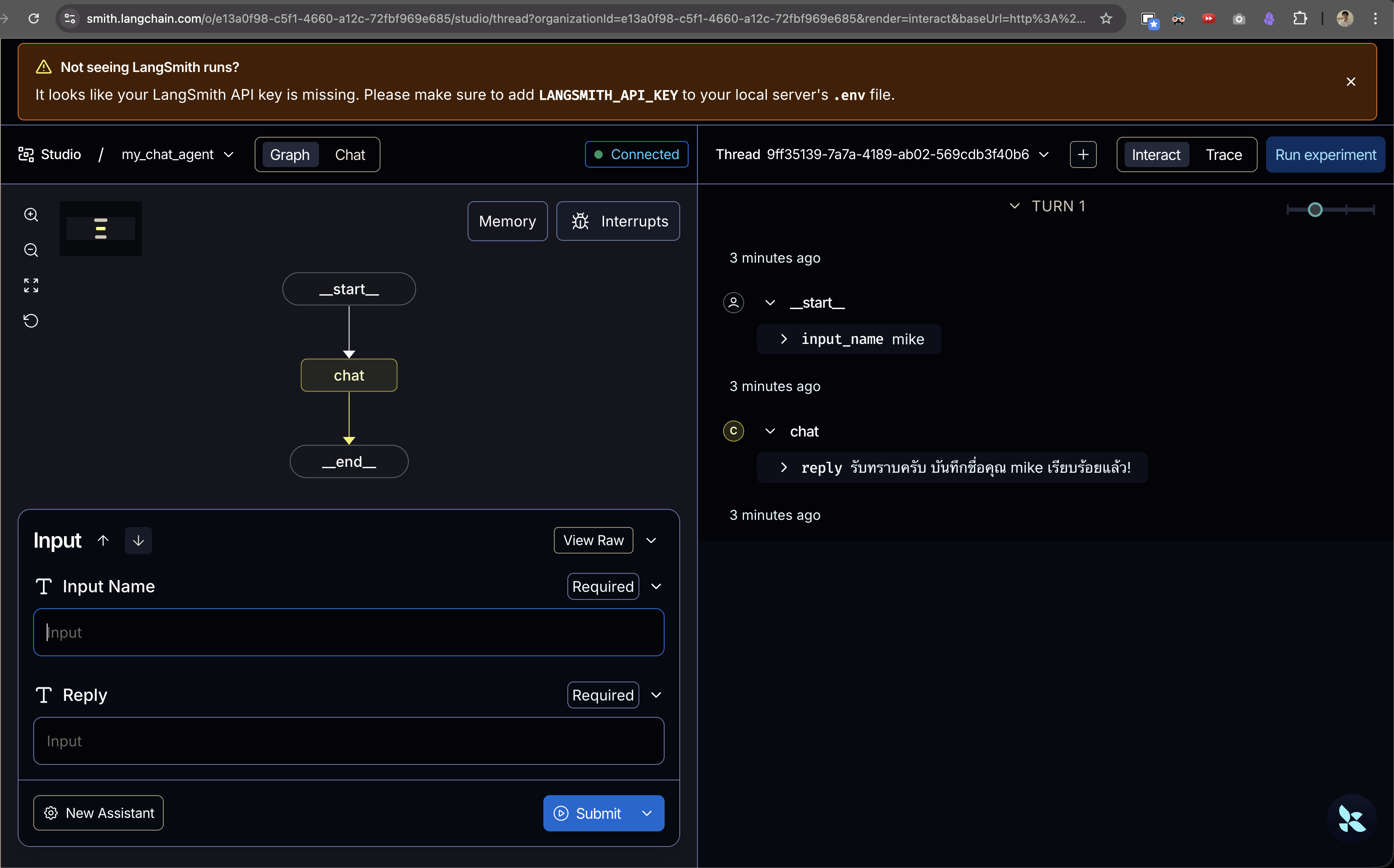 มันก็จะเก็บชื่อ Mike ลงใน namespace
มันก็จะเก็บชื่อ Mike ลงใน namespace user-123 ตามที่ defined เอาไว้ พร้อมกับ value name ที่ระบุตาม code ไว้
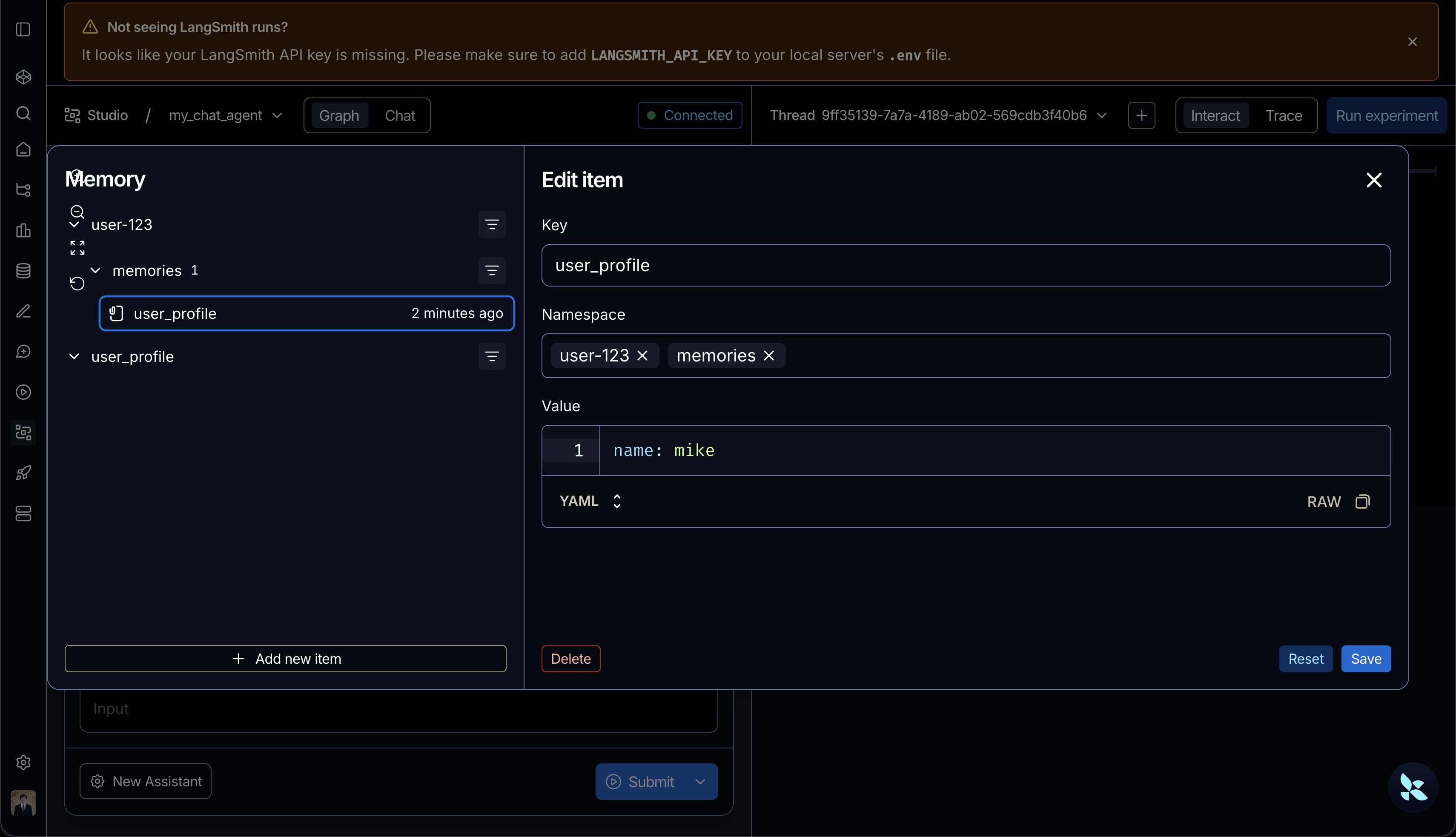 และเมื่อมันจดจำ input ครั้งแรกลง Memory ไปแล้ว พอเราลองทักครั้งต่อไปดู (ใน Thread ใหม่ที่ new มา) มันก็จะสามารถพิมพ์ชื่อเรากลับมาเลย แม้ว่าเราจะส่ง input เป็นค่าว่างไปก็ตาม
และเมื่อมันจดจำ input ครั้งแรกลง Memory ไปแล้ว พอเราลองทักครั้งต่อไปดู (ใน Thread ใหม่ที่ new มา) มันก็จะสามารถพิมพ์ชื่อเรากลับมาเลย แม้ว่าเราจะส่ง input เป็นค่าว่างไปก็ตาม
Example 4 - Time Travel
มาถึง feature สุดท้ายที่เป็นอีกเรื่องราวน่ารู้ของ LangGraph สำหรับองค์ประกอบหลักนั่นคือเรื่องของการเดินทางผ่าน Graph ใน LangGraph กัน
Time travel (การย้อนเวลา) ใน LangGraph อาศัยการทำงานของ Checkpointer ในการบันทึกสถานะของกราฟ (Checkpoint) ในทุกๆ ขั้นตอน ทำให้เราสามารถทำได้ 2 อย่างหลักๆ คือ:
- Replay: การย้อนกลับไปรันการทำงานเดิมใหม่จากจุดอดีต
- Fork: การย้อนเวลาไปแก้ไขสถานะหรือข้อมูลในอดีต แล้วสั่งรันต่อเพื่อสำรวจผลลัพธ์ในเส้นทางเลือกใหม่ (Alternative path)
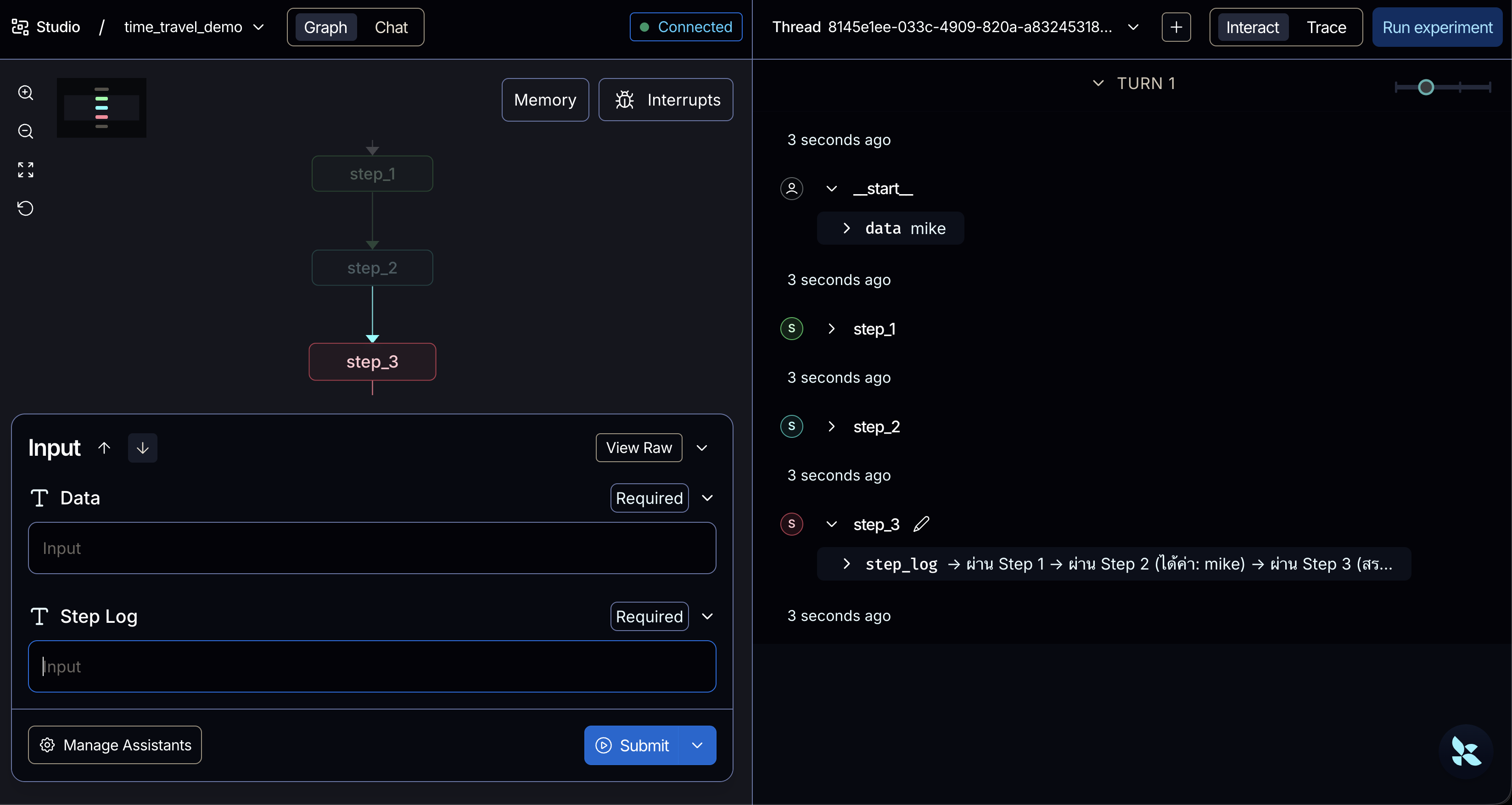
ในการใช้งาน เราจะต้องใช้คำสั่ง graph.get_state_history(config) เพื่อดึงประวัติ Checkpoint ออกมา (โดยข้อมูลจะเรียงจากใหม่สุดไปเก่าสุดเสมอ) จากนั้นจึงเลือก config ในจุดอดีตที่เราต้องการนำมาใช้งาน
ตัวอย่างเช่นเคสนี้
- เราสร้าง Agent ที่มีทั้งหมด 3 Step ต่อเนื่องกันมา
- จากนั้น เราจะทำ 2 case คือ จะทำการ rerun ใหม่ตั้งแต่ Step ที่ 2 (
Replay) และทำการแทรกข้อมูลเข้าไปใน Step ที่ 2 (Fork) เพื่อให้ data ถูกแทรกระหว่างทาง
from typing import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.checkpoint.memory import MemorySaver
# 1. กำหนด Stateclass State(TypedDict): data: str step_log: str
# 2. สร้าง Node การทำงานdef step_1(state: State): return {"step_log": state.get("step_log", "") + " -> ผ่าน Step 1"}
def step_2(state: State): current_data = state.get("data", "") return {"step_log": state.get("step_log", "") + f" -> ผ่าน Step 2 (ได้ค่า: {current_data})"}
def step_3(state: State): return {"step_log": state.get("step_log", "") + " -> ผ่าน Step 3 (สรุปผล)"}
# 3. ประกอบร่าง StateGraphbuilder = StateGraph(State)builder.add_node("step_1", step_1)builder.add_node("step_2", step_2)builder.add_node("step_3", step_3)builder.add_edge(START, "step_1")builder.add_edge("step_1", "step_2")builder.add_edge("step_2", "step_3")builder.add_edge("step_3", END)
# จำเป็นต้องใช้ Checkpointer เสมอเพื่อให้สามารถ Time travel ได้memory = MemorySaver()graph = builder.compile(checkpointer=memory)
if __name__ == "__main__": config = {"configurable": {"thread_id": "time-travel-demo"}}
print("--- 1. รันกราฟตามปกติ (เส้นทางหลัก) ---") result = graph.invoke({"data": "ข้อมูลต้นฉบับ", "step_log": "Start"}, config=config) print("ผลลัพธ์:", result["step_log"])
# ดึงประวัติ Checkpoint (เรียงจากใหม่สุดไปเก่าสุด) history = list(graph.get_state_history(config))
# แสดง checkpoint ทั้งหมดเพื่อดูโครงสร้าง print(f"\nจำนวน checkpoints ทั้งหมด: {len(history)}") for i, state in enumerate(history): print(f" [{i}] next={state.next}, step_log={state.values.get('step_log', 'N/A')}")
# history[0] = จุดสิ้นสุด (หลังรัน Step 3 จบ) -> next=() # history[1] = จุดพักหลังทำ Step 2 เสร็จ -> next=('step_3',) # history[2] = จุดพักหลังทำ Step 1 เสร็จ -> next=('step_2',) # history[3] = จุด Start -> next=('step_1',) # history[4] = จุด __start__ -> next=('__start__',)
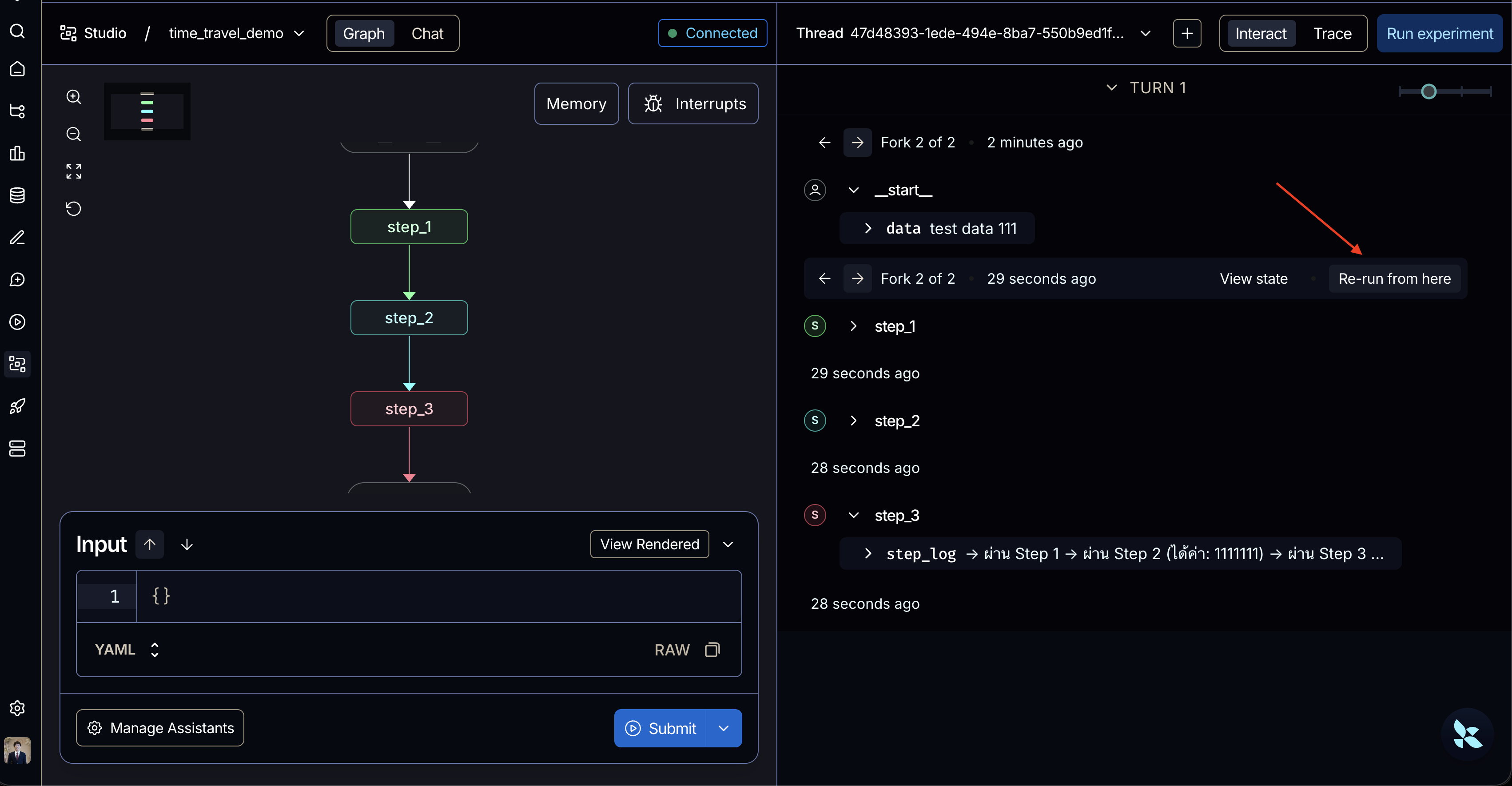
# เราเลือกจุดที่ "เพิ่งทำ Step 2 เสร็จ" เป็นจุดเพื่อย้อนเวลา (Replay จะรันต่อแค่ Step 3) past_checkpoint = history[2].config
print("\n--- 2. Replay (ย้อนไปรัน Step 2-3 ใหม่ จากจุดหลัง Step 1) ---") # สั่ง invoke โดยส่ง Input เป็น None และระบุ config เป็นอดีต # กราฟจะไม่รัน Step 1 ซ้ำ แต่จะรันต่อจาก Step 2 → Step 3 เลย replay_result = graph.invoke(None, config=past_checkpoint) print("ผลลัพธ์ Replay:", replay_result["step_log"])
print("\n--- 3. Fork (ย้อนอดีตไปแก้ค่าตัวแปร แล้วแตกเส้นทางใหม่) ---") # ใช้คำสั่ง update_state เพื่อดัดแปลงข้อมูลในอดีตก่อน # update_state จะ return config ใหม่ที่ชี้ไปยัง checkpoint ที่ถูกอัปเดต forked_config = graph.update_state(past_checkpoint, {"data": "!! ข้อมูลถูกแฮ็กในอดีต !!"})
# สั่งรันต่อจากอดีตที่ถูกปรับเปลี่ยนข้อมูลไปแล้ว (ใช้ forked_config) fork_result = graph.invoke(None, config=forked_config) print("ผลลัพธ์ Fork:", fork_result["step_log"])อธิบายจาก code
1. Replay (การรันซ้ำจากอดีต)
- Concept: คือการย้อนกราฟกลับไปยังจุด Checkpoint ในอดีต และสั่งให้ระบบประมวลผลเดินหน้าต่อจากจุดนั้น
- การทำงานในโค้ด:
- ระบบใช้
graph.get_state_history(config)เพื่อดึงประวัติการรันทั้งหมดออกมา โดยเรียงลำดับจากใหม่สุด (รายการแรก) ไปหาเก่าสุด - โค้ดจำลองการย้อนเวลาโดยดึงเอา
past_checkpoint = history``.configซึ่งเป็นสถานะ “หลังจากที่รันstep_1เสร็จแล้ว แต่ยังไม่ได้รันstep_2” มาใช้งาน - จากนั้นสั่งรันด้วย
graph.invoke(None, config=past_checkpoint)(สังเกตว่าส่ง Input เป็นNoneเพื่อบอกว่าไม่มีข้อมูลใหม่เข้า แต่ให้ทำต่อจาก config เดิม) - จุดสำคัญ: เมื่อเกิดการ Replay โหนดที่เคยรันผ่านไปแล้วก่อนหน้า Checkpoint นี้ (คือ
step_1) จะ ไม่ถูกรันซ้ำ (Skipped) เพราะผลลัพธ์ถูกดึงมาจากที่เซฟไว้แล้ว แต่กราฟจะเริ่มรันใหม่เฉพาะโหนดที่อยู่หลังจากนั้น (คือรันstep_2ไปยังstep_3) ต่อไปจนจบ
- ระบบใช้
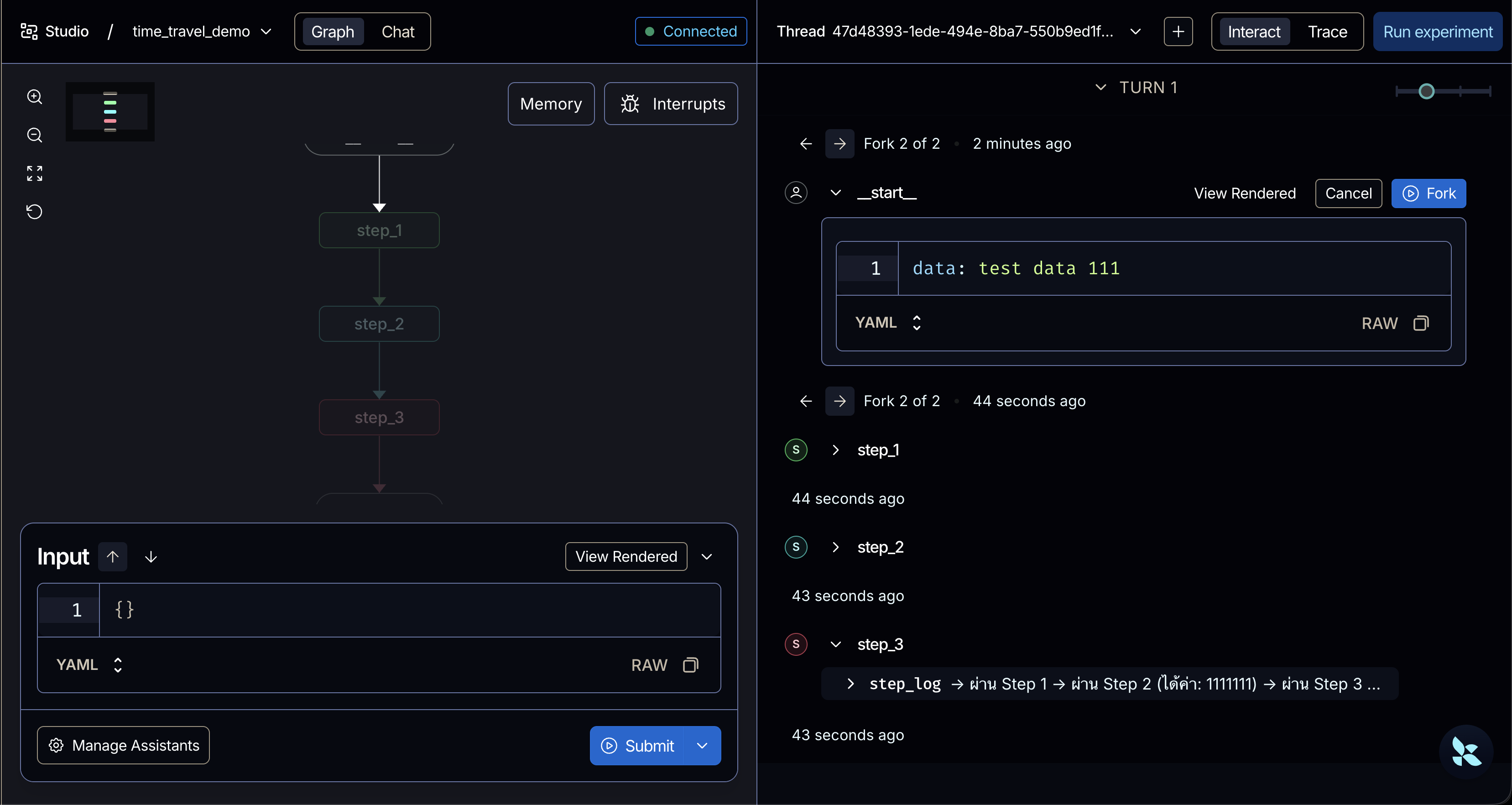
2. Fork (การสร้างเส้นทางใหม่ด้วยการแก้ไขอดีต)
- Concept: คล้ายกับการ Replay แต่ต่างกันตรงที่ก่อนจะให้กราฟเดินต่อ เราจะทำการ แก้ไขข้อมูลใน State ณ ตอนนั้น (Modified state) เสียก่อน เพื่อแตกเส้นทาง (Branch) ออกไปดูทางเลือกอื่น (Alternative path)
- การทำงานในโค้ด:
- โค้ดใช้คำสั่ง
graph.update_state(past_checkpoint, {"data": "!! ข้อมูลถูกแฮ็กในอดีต !!"})เพื่อแอบเปลี่ยนค่าตัวแปรdataในอดีต - คำสั่ง
update_stateนี้ ไม่ได้ลบประวัติอดีตของเดิมทิ้ง แต่จะเป็นการสร้าง Checkpoint ตัวใหม่ที่แตกกิ่ง (Fork) ออกมาจากจุดเดิม และระบบจะส่งคืนค่ารหัสคอนฟิกใหม่ (forked_config) กลับมาให้ - เมื่อเราสั่งรันต่อด้วย
graph.invoke(None, config=forked_config)กราฟก็จะรันstep_2และstep_3ใหม่เช่นเดียวกับ Replay แต่คราวนี้โหนดจะได้รับข้อมูลใหม่ (ข้อมูลที่ถูกแฮ็ก) ไปใช้แทนข้อมูลต้นฉบับ ทำให้เกิดเป็นประวัติการสนทนาหรือผลลัพธ์ในอีกเส้นทางหนึ่งที่แยกขาดจากของเดิมครับ
- โค้ดใช้คำสั่ง
เพื่อให้เห็นภาพการ Fork ผมจะลองเทียบผลลัพธ์การ run จาก code ปัจจุบันดู นั่นคือ จะได้ผลลัพธ์ตามนี้ออกมา
...
--- 3. Fork (ย้อนอดีตไปแก้ค่าตัวแปร แล้วแตกเส้นทางใหม่) ---ผลลัพธ์ Fork: Start -> ผ่าน Step 1 -> ผ่าน Step 2 (ได้ค่า: !! ข้อมูลถูกแฮ็กในอดีต !!) -> ผ่าน Step 3 (สรุปผล)ที้นี้หากเราเปลี่ยน code history จากเดิมถัดไปอีก 1 step (จากเริ่มตอน Step 1 เสร็จ เป็นเริ่มตอน Step 2 เสร็จแทน) เป็น
'''จำนวน checkpoints ทั้งหมด: 5 [0] next=(), step_log=Start -> ผ่าน Step 1 -> ผ่าน Step 2 (ได้ค่า: ข้อมูลต้นฉบับ) -> ผ่าน Step 3 (สรุปผล) [1] next=('step_3',), step_log=Start -> ผ่าน Step 1 -> ผ่าน Step 2 (ได้ค่า: ข้อมูลต้นฉบับ) [2] next=('step_2',), step_log=Start -> ผ่าน Step 1 [3] next=('step_1',), step_log=Start [4] next=('__start__',), step_log=N/A'''
# past_checkpoint = history[2].configpast_checkpoint = history[1].configแล้วลอง run ผลลัพธ์อีกที
...
--- 3. Fork (ย้อนอดีตไปแก้ค่าตัวแปร แล้วแตกเส้นทางใหม่) ---ผลลัพธ์ Fork: Start -> ผ่าน Step 1 -> ผ่าน Step 2 (ได้ค่า: ข้อมูลต้นฉบับ) -> ผ่าน Step 3 (สรุปผล)จะสังเกตว่า Step 2 ข้อมูลจะไม่เปลี่ยนตาม Data ที่ส่งเข้าไป เพราะข้อมูลมันเข้าไปหลัง Step 2 จบแล้วนั่นเอง
ซึ่งใน Langsmith Studio สามารถทำได้อยู่แล้วจากตัว feature ของ UI เอง สามารถทำได้ทั้ง Replay (Rerun)
 และ Fork ได้อยู่แล้วผ่านตัวของ LangSmith Studio เลย
และ Fork ได้อยู่แล้วผ่านตัวของ LangSmith Studio เลย
 เรื่องนี้ผมหยิบมาแชร์ไว้ เพราะจะเป็นเรื่องที่เราจะมีโอกาสได้ประยุกต์ใช้กันในอนาคตแน่นอน
เรื่องนี้ผมหยิบมาแชร์ไว้ เพราะจะเป็นเรื่องที่เราจะมีโอกาสได้ประยุกต์ใช้กันในอนาคตแน่นอน
Summary and Next
สำหรับหัวข้อนี้ สิ่งที่เราเรียนรู้กันมามีตั้งแต่
- ทำความรู้จักกับ LangGraph: เข้าใจถึงจุดประสงค์การใช้งานที่เน้นการทำ Low-level orchestration และความแตกต่างเมื่อเทียบกับ LangChain ว่าควรเลือกใช้เครื่องมือตัวไหนในสถานการณ์ใด
- องค์ประกอบหัวใจหลัก 4 อย่าง: ไม่ว่าจะเป็น State (ข้อมูลส่วนกลาง), Nodes (ฟังก์ชันคนทำงาน), Edges (ตัวกำหนดเส้นทาง) และ Persistence (ระบบเซฟสถานะ) ที่เมื่อนำมาประกอบกันจะกลายเป็น Workflow ของ Agent ที่สมบูรณ์
- การใช้เครื่องมือคู่ใจอย่าง LangSmith Studio: ที่เข้ามาช่วยให้การรัน ทดสอบ และ Debug กราฟของเรากลายเป็นเรื่องง่าย เห็นภาพรวมทุก State และ Step การทำงานได้ชัดเจนขึ้นมากๆ เหมือนกับการพัฒนาแอปพลิเคชันทั่วไป
- เทคนิคการจัดการความจำ (Memory): ตั้งแต่การทำ Short-term memory (จดจำประวัติตาม Thread), การทำ Long-term memory (จดจำข้อมูลข้าม Thread โดยผูกกับ User ID ผ่าน Store), ไปจนถึงการประยุกต์ใช้ Persistence เพื่อหยุดกราฟชั่วคราวและทำระบบ Approval (Human-in-the-loop)
- การเดินทางข้ามเวลา (Time Travel): อีกหนึ่ง feature ของ LangGraph ที่ทำให้เราสามารถย้อนอดีตกลับไปรันการทำงานซ้ำ (Replay) หรือแม้แต่แก้ไขข้อมูลตรงจุด Checkpoint ในอดีตเพื่อแตกเส้นทางดูผลลัพธ์แบบใหม่ (Fork) ได้
หัวข้อถัดไป เราจะมาสู่ Path ของ Application กันบ้าง เพื่อให้เห็นภาพว่า Agent ที่เราสร้างๆกันมา หากเราต้องนำ interface ไปต่อใช้งานภายนอกนั้น สามารถนำไปใช้งานกันได้อย่างไรบ้าง และ มีจุดอะไรที่ต้องพิจารณาก่อนนำไป implement จริงบ้าง ติดตามกันในหัวข้อถัดไปนะครับ
Reference
- https://youtu.be/jGg_1h0qzaM?si=n10693g9LC7aruqx
- https://youtu.be/V8KSi55QR4g?si=hBRmROEFXklblnbv
- https://youtu.be/ZKNI1w7t0vs?si=cb3GiymdSnhcmjAP
-

- แนะนำ Dynamic programming แบบนิ่มนวลที่สุดมี Video
บทความนี้จะแนะนำเบื้องต้นเกี่ยวกับ Dynamic programming เทคนิคหนึ่งที่ใช้สำหรับแก้ปัญหาที่ ปัญหาย่อยที่ทับซ้อนกัน (overlapping subproblem)

- มารู้จักกับ SQL Transaction กันว่ามันคืออะไร ?มี Video
มารู้จักเรื่องราวของการทำ Transaction และ Deadlock ผ่าน SQL กันว่ามันคืออะไร

- LangChain 101มี Video
พาทุกคนมาปูพื้นฐานการสร้าง AI Agent ด้วย "LangChain" Framework ที่เปรียบเสมือนตัวกลางในการเชื่อมต่อ LLM เข้ากับ application
