

รู้จักกับ Kafka distribution system สำหรับ Realtime กัน
/ 9 min read
 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
Kafka คืออะไร ?
Kafka คือตัวกระจาย Event distribution platform ที่ช่วยกระจาย data ที่ stream แบบ realtime ได้
เทคโนโลยีนี้เกิดจากทีมของ LinkedIn จากปัญหาเรื่องของการพยายามทำ “Realtime data processing” ในทีมของ LinkedIn ที่สามารถกระจายการทำงาน, ใช้งานได้กับทุกระบบ และรวดเร็ว (สามารถ scale ได้) = ก็เลยเกิดเป็นตัว Kafka นี้ขึ้นมา
เพื่อแก้ปัญหาจากภาพนี้ ที่ Frontend แต่ละตัวต้องยิง Service กระจายตัวออกไป (Point to Point data)
เป็นภาพแบบนี้แทน (Data pipeline)
Ref: https://datascience.cafe/cafe/2016/02/17/kafka-data-integration/
โจทย์ของ Kafka คือเป็นตัวที่คอยเชื่อมเป็นตัวกลางระหว่าง Producer (ผู้ผลิต) และ Consumer (ผู้บริโภค) โดยองค์ประกอบหลักคือ
- Producer จะเป็นคนคอยส่งข้อมูล (Message) เข้า Message Queue เข้าไป
- Consumer หยิบแต่ละข้อมูล (Message) ที่ได้รับจาก Message Queue ไปจัดการงานต่อ
- โดย Broker คือ Kafka server (ใน Kafka Cluster) เปรียบได้กับ node (หรือเครื่อง server เครื่องหนึ่ง) ที่มีหน้าที่ในการเก็บข้อมูล (จาก Producer) และส่งข้อมูล (ไปให้ Consumer) ตามที่ Request ออกไป (ซึ่ง Broker ก็จะผูกกับ Partition ที่เก็บข้อมูลไว้)
- และมี Zookeeper ที่เป็นผู้จัดการ Broker คอยดูว่ามี Broker มีตัวไหนตายไหม จัดการกับ Kafka Cluster (เหล่า Broker นี้) ให้สามารถดำเนินการต่อได้ ก็จะดูแลเรื่องของการเลือก Leader, replica ของ Partition
 Ref: https://www.techterrotor.com/2022/04/kafka-message-queue.html
Ref: https://www.techterrotor.com/2022/04/kafka-message-queue.html
โดยองค์ประกอบการจัดการข้อมูลคือ
- Topic ที่ใช้สำหรับแบ่งประเภทของข้อความที่จะส่งออกจากกันได้ (เหมือนเราสร้าง chat กลุ่ม) โดย
- Producer สามารถส่งข้อความเฉพาะกลุ่มได้
- Consumer สามารถรับข้อความเฉพาะกลุ่มที่ตัวเองกำลังดูอยู่ได้ (โดยหยิบตาม topic ที่สนใจ)
- Partition คือการแบ่งส่วนการเก็บ Queue ออกจากกัน โดยแต่ละ topic นั้นมันจะกระจายไปตามแต่ละ partition ซึ่งอนุญาตให้ทำ hotizontal scale ที่สามารถแบ่ง topic เป็นเก็บและแชร์ได้
- Offset = position ที่เก็บข้อมูลตำแหน่งปัจจุบันของแต่ละ Partition เพื่อให้รู้ว่าตำแหน่งปัจจุบันของข้อมูล Queue อยู่ที่ใด
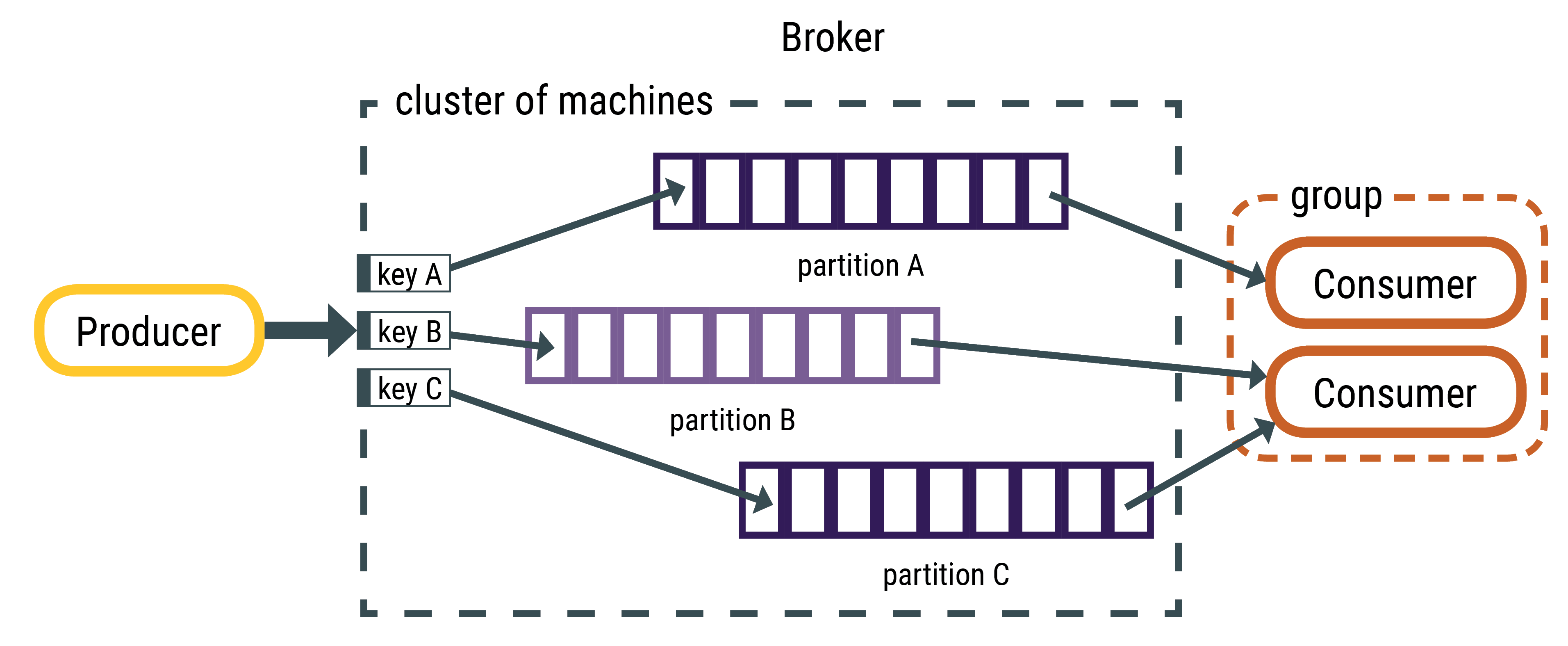
Ref: https://docs.datastax.com/en/kafka/doc/kafka/kafkaHowMessages.html
ไอเดียหลักของ Kafka คือ
- ข้อมูลทั้งหมดจะส่งผ่าน Producer มา
- หลังจากนั้น Broker ก็จะจัดการจัดเก็บข้อมูลเข้า Partition ไป โดย Broker จะสร้าง key กำหนดปลายทาง Partition ที่ต้องไป (ถ้าไม่มีการระบุ Key เราจะเรียก concept ว่า Round robin เหมือนตามหา Partition ที่มีปริมาณไม่มาก เพื่อให้ balance ของทุก partition เท่ากันแล้วก็ใส่เข้าไป)
- ฝั่ง Consumer จะสร้างตัวเองมาเป็น Consumer Group (กลุ่มของ Consumer) แล้วจะทำการ subscribe topic กับ ทุก Partition เอาไว้ แล้วเมื่อมีข้อมูลเข้ามา Consumer ก็จะได้รับข้อมูลออกไป
- Consumer 1 ตัว สามารถ subscribe หลาย Partition ได้ แต่ถ้าใน Consumer Group มีหลาย Consumer = สามารถช่วยกัน subscribe Partition ได้ (เหมือนภาพนี้ ที่ Consumer 1 ตัว subscribe Partiion 2 อัน, อีกตัว subscribe อันเดียว)
- แปลว่าใน 1 Consumer Group = ไม่ควรมี Consumer เกิน Partition (เพราะมีเกิน Consumer ก็จะไม่ action อะไรอยู่ดี)
มุมมองของการใช้งาน
- Kafka จะไม่เหมือน Message queue ทั่วไปอย่างหนึ่งคือ มันทำการ scale ตาม Producer - Consumer ได้ = มันสามารถกระจายการทำงานเท่าไหร่ก็ได้ และไม่ได้ “ทำงานต่อเนื่องกัน ”
- ไม่ได้โดย design มาให้ทำงานตามลำดับนะ (มันคือ Concept ของ Partition)
ตัวอย่างในเรื่องนี้- Partition 1: Message A (timestamp: 1), Message C (timestamp: 3)- Partition 2: Message B (timestamp: 2), Message D (timestamp: 4)- Consumer อาจจะได้รับข้อมูลเป็น A, B, C, D (ที่มาตาม timestamp เลย) / A, C, B, D / B, A, C, D ขึ้นอยู่กับว่า Consumer อ่านข้อมูลได้ตอนไหน = ไม่ได้การันตีลำดับการได้รับข้อมูลเพราะฉะนั้น การพิจารณาใน Kafka นั้นให้คำนึงว่า use case ที่ใช้ควรจะต้อง “independent กัน” เช่น
สมมุติเรามี Service Frontend ที่ต้องส่งข้อมูลเพื่อไปทำ
- Hadoop เพื่อทำ Machine learning กับ Data
- Monitoring data เพื่อวัด Performance
- Notification เพื่อไปบอก user
- Logging เพื่อทำการบันทึกข้อมูล
- Report สำหรับนำข้อมูลไปออกรายงาน
ซึ่ง 5 เคสนี้ทำออกจากกัน เพียงแต่ไม่จำเป็นต้องทำทันทีที่เกิด Event ที่ Frontend ขึ้น = เคสนี้จะพิจารณาใช้ Kafka ได้
แต่ถ้าเป็นลักษณะเป็น Transaction กัน เช่น
- เราทำระบบ upload image มาจาก Frontend
- เพื่อส่งไป process เราอาจจะแยกกัน Process ภาพ 3 ส่วนออกจากกันเป็น Service 3 ตัว
- แต่ท้ายสุดเราต้องเอาข้อมูลทั้ง 3 ตัวเนี้ยมาประกอบกัน เพื่อเอาผลลัพธ์ออกมา
เคสนี้ จะไม่เหมาะกับการใช้ Kafka เนื่องจาก design เป็นแบบ queue จะจัดการตรงไปตรงมากว่า (ไม่ใช่ ใช้ไม่ได้นะ แต่มันจะทำให้ code เกิดความซับซ้อนขึ้น เนื่องจาก Kafka design มาเป็นลักษณะการกระจายตัวแล้วจบมากกว่า)
เหตุผลที่ Kafka แข็งแกร่ง
ข้อดี
-
Fault-tolerance: การจัดการภายใน Kafka แข็งแกร่งมาก ทนทานต่อการที่ระบบจะล่มได้ (มี Zookeeper คอยจัดการให้ รวมถึงมีการกระจายการเก็บข้อมูล Partition ในแต่ละ Broker - Replication เพื่อให้ข้อมูลทนทานต่อการหายด้วย เมื่อระบบล่ม)
-
Low Latency: เหมาะสำหรับทำงาน realtime data ทั้ง messages/event (ด้วย idea การกระจายตัวของมันนี่แหละ)
-
Connector Framework: มี library พร้อมให้ใช้งานแล้ว
ข้อพิจารณา
- Learning Curve: มันเป็น Concept ที่ต้องอาศัยการ design ที่ถูกต้อง อาจจะต้องใช้เวลาในการเรียนรู้พอสมควร (รวมถึงการ setup ใน production ด้วย)
- Resource Intensive: เพื่อให้ระบบแข็งแกร่งและข้อมูลไม่หาย จึงต้องทั้งสำรองข้อมูลและ Resource server เอาไว้พอสมควร อาจจะกิน Resource เกินโจทย์ที่เราต้องการได้ (หากประเมินมาไม่ดี)
- vs Queue: อาจจะมีบางเคสที่ใช้แค่ Queue ก็เพียงพอสำหรับจัดการ Process แล้ว
Use case ที่มีของ Kafka
- Real-time Analytics: ส่งข้อมูลเพื่อไปทำ Motitor, Analytic ระบบ (เป็น use case ที่ linkedin เองก็ใช้เช่นกั)
- Log Aggregation: ทำ Log analytic ได้
- Recommendation: ใช้สำหรับทำ realtime recommedation ได้ (รับข้อมูลจาก Kafka ไป Process ตลอดเวลาได้) อาจจะใช้ร่วมกับ Elasticsearch ในการทำเรื่องนี้ได้
- Data Lakes: สามารถใช้งานร่วมกับ Data Lake (อย่าง Hadoop) เพื่อเก็บข้อมูลเข้า data lake ไว้ได้ (เก็บเป็น large dataset ไว้ได้)
- Financial Transactions: ใช้กับการ Process งานการเงินได้ เพราะมีความ durability, low-latency อยู่แล้ว รวมถึงสามารถใช้สำหรับการจัดการ balance ให้ realtime.
และอื่นๆ อะไรก็ตามที่ต้องการคุณสมบัติ “Realtime” = คู่ควรแก่การใช้ Kafka
เราจะลองเอา Kafka มาทำอะไรกัน
สิ่งที่เราจะทำ
- เราจะสร้าง API สำหรับการ placeorder ขึ้นมาโดยเช็คตามสินค้าว่ามีสินค้าหรือไม่ ?
- ถ้ามี = สร้าง Order และส่ง messaging ไปบอก
producerว่าจะส่ง message ผ่าน LINE ไป (Order status: pending) - ที่
consumerทำการรับ message จากproducerเพื่อนำข้อมูล product ไปส่งบอก user ผ่าน LINE และปรับ Order status เป็น success
** ดัง Sequence diagram นี้ (Diagram นี้จะขอตัด Database ออกไป เนื่องจาก sequence diagram จะยาวเกิน แต่ขอให้เข้าใจว่าการดึง Product และการสร้าง Order เกิดขึ้นที่ Database)
Setting project
เพื่อให้ง่ายต่อการทดลอง เราจะขอใช้เพียง
- 1 Partition
- 1 Broker
- 1 Consumer
- 1 Producer
เพื่อให้ทุกคนเห็นภาพผ่าน code ก่อนว่า เราสามารถ code kafka ยังไงออกมาได้บ้าง
Structure project จะประมาณนี้
├── consumer.js --> สำหรับเก็บ consumer ของ kafka├── docker-compose.yml --> สำหรับ run kafka และ database (mysql)├── package.json├── producer.js --> สำหรับเก็บ producer ของ kafka├── schema.js --> สำหรับเก็บ schema ของ database เอาไว้└── src --> สำหรับเก็บ Frontend └── index.htmlNote
- ที่รอบนี้มีฝั่ง Frontend ด้วย เพราะเราจะดึง userId ออกมาผ่าน LIFF ของ LINE Messaing ที่จะใช้สำหรับส่ง placeorder (จะไม่ได้มีการ implement UI อะไร แต่สามารถนำ API มาลองยิงผ่าน axios ได้)
ที่ docker-compose.yml
เราจะ run ทั้งหมด 4 ตัวคือ
- kafka = messaing queue service
- zookeeper = kafka management
- db = mysql database
- phpmyadmin = phpmyadmin สำหรับจัดการ mysql
version: "3.8"
services: zookeeper: image: wurstmeister/zookeeper:latest ports: - "2181:2181" environment: - ALLOW_ANONYMOUS_LOGIN=yes kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: - KAFKA_BROKER_ID=1 - KAFKA_LISTENERS=PLAINTEXT://:9092 - KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 - KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 - ALLOW_PLAINTEXT_LISTENER=yes depends_on: - zookeeper db: image: mysql:latest container_name: mysql_db command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: tutorial ports: - "3306:3306" volumes: - mysql_data:/var/lib/mysql phpmyadmin: image: phpmyadmin/phpmyadmin:latest container_name: phpmyadmin environment: PMA_HOST: db PMA_PORT: 3306 PMA_USER: root PMA_PASSWORD: root ports: - "8080:80" depends_on: - db
volumes: mysql_data: driver: localที่ package.json
library ที่ใช้ในรอบนี้
express= library node สำหรับทำ Rest APIaxios= สำหรับยิงไปยัง API ของ LINE APIbody-parser= สำหรับแกะข้้อมูลจาก bodydotenv= สำหรับอ่านค่าจาก.envkafkajs= library สำหรับจัดการใน kafka ของ nodemysql2= library สำหรับต่อกับ mysql (ใช้โดย sequelize)sequelize= library สำหรับคุยกับ mysql ด้วยวิธี ORM
{ "name": "kafka-basic", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "start": "python3 -m http.server --directory src 8888", "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], "author": "", "license": "ISC", "dependencies": { "axios": "^1.5.0", "body-parser": "^1.20.2", "dotenv": "^16.3.1", "express": "^4.18.2", "kafkajs": "^2.2.4", "mysql2": "^3.6.1", "sequelize": "^6.33.0" }, "devDependencies": { "nodemon": "^3.0.1" }}โจทย์ของหัวข้อนี้เราจะทำอะไรกันบ้าง
สร้าง 3 file คือ
producer.jsสำหรับทำ Rest API และตัวส่ง producer ของ kafkaconsumer.jsสำหรับ run เป็น consumer คอยรับค่าจาก producerschema.jsสำหรับต่อเข้ากับฐานข้อมูล mysql และ ประกาศ schema Product, Order แยกเอาไว้
ที่ schema.js
สิ่งที่จะทำ
- เราจะสร้าง Schema 2 ตัวคือ
OrderและProductออกมา โดย- Order ใช้สำหรับเก็บข้อมูลการซื้อเอาไว้ (ก่อนยิง message และ update หลังยิง message เข้า LINe)
- Product ใช้สำหรับเก็บสินค้าเอาไว้ เพื่อเช็คก่อนว่าสินค้ามีหรือไม่ ก็ส่งไป สร้าง order
const { Sequelize, DataTypes } = require("sequelize");
// use sequenlizeconst sequelize = new Sequelize("tutorial", "root", "root", { host: "localhost", dialect: "mysql",});
const Order = sequelize.define("orders", { userLineUid: { type: DataTypes.STRING, allowNull: false, }, status: { type: DataTypes.STRING, allowNull: false, },});
const Product = sequelize.define("products", { name: { type: DataTypes.STRING, allowNull: false, }, amount: { type: DataTypes.INTEGER, allowNull: false, },});
Product.hasMany(Order);Order.belongsTo(Product);
module.exports = { Order, Product, sequelize,};ที่ producer.js
สิ่งที่จะทำ
- ทำ Rest API 2 ตัวออกมาคือ
POST /api/create-productสำหรับสร้าง product ที่จะใช้สร้าง order (ทำไว้เพื่อให้เป็นตาม pattern ของ ORM)POST /api/placeorderสำหรับสร้าง Order โดยเช็คกอนว่า product มีหรือไม่ และมี userId สำหรับส่ง message เข้า LINE หรือไม่
- โดยใน
POST /api/placeorderproducer เข้าไปว่า ถ้าสามารถสร้าง Order ได้ ให้สร้าง Order พร้อม status ‘pending’ เพื่อขอ message confirm (ก่อนจะ update เป็น success)
** ทดสอบโดยการปิด consumer ก่อนได้
const express = require("express");const { Kafka } = require("kafkajs");const { Order, Product, sequelize } = require("./schema");
const app = express();const port = 8000;
const kafka = new Kafka({ clientId: "express-app", brokers: ["localhost:9092", "localhost:9092"],});
const producer = kafka.producer();
app.use(express.json());
app.post("/api/create-product", async (req, res) => { const productData = req.body; try { const product = await Product.create(productData); res.json(product); } catch (error) { res.json({ message: "something wront", error, }); }});
app.post("/api/placeorder", async (req, res) => { try { const { productId, userId } = req.body;
const product = await Product.findOne({ where: { id: productId, }, });
if (product.amount <= 0) { res.json({ message: "product out of stock", }); return false; }
// reduce amount product.amount -= 1; await product.save();
// create order with status pending const order = await Order.create({ productId: product.id, userLineUid: userId, status: "pending", });
const orderData = { productName: product.name, userId, orderId: order.id, };
await producer.connect(); await producer.send({ topic: "message-topic", messages: [ { value: JSON.stringify(orderData), }, ], }); await producer.disconnect();
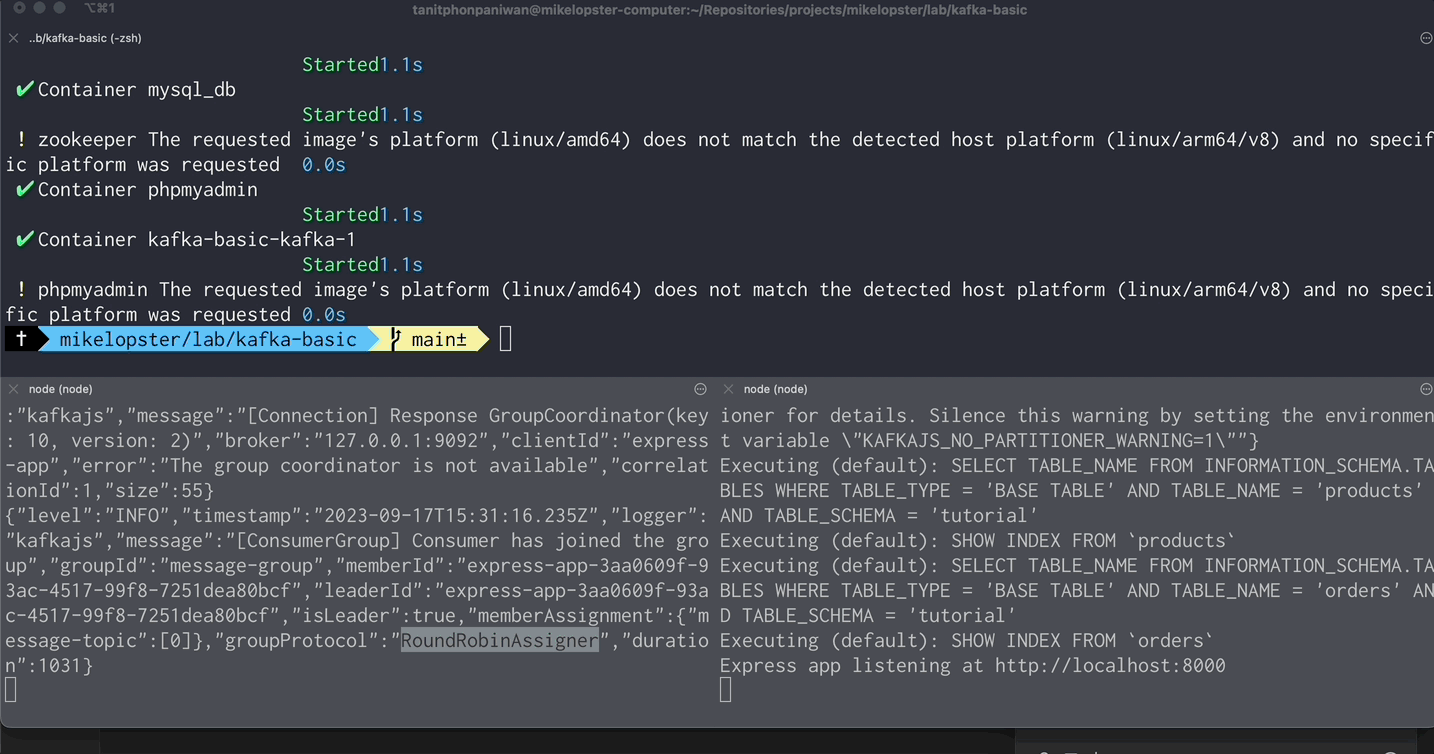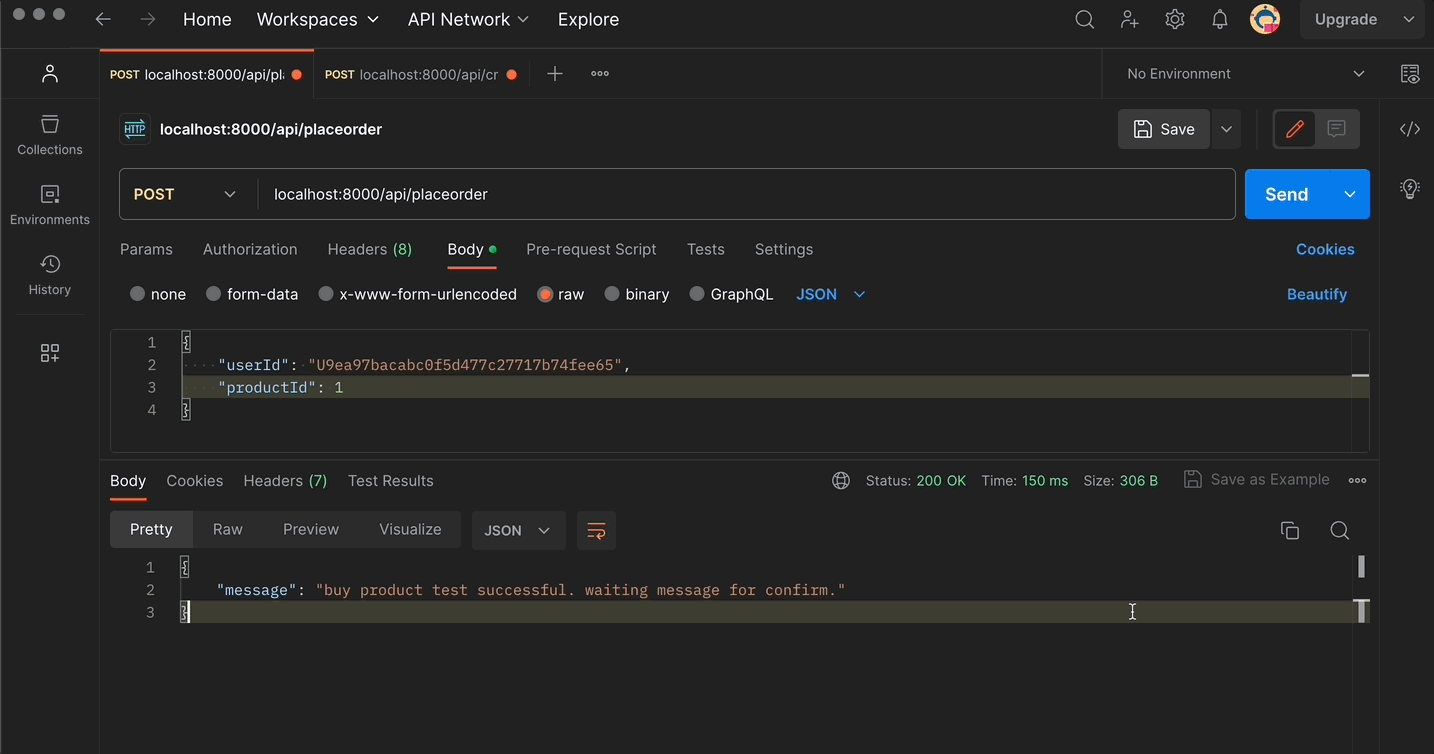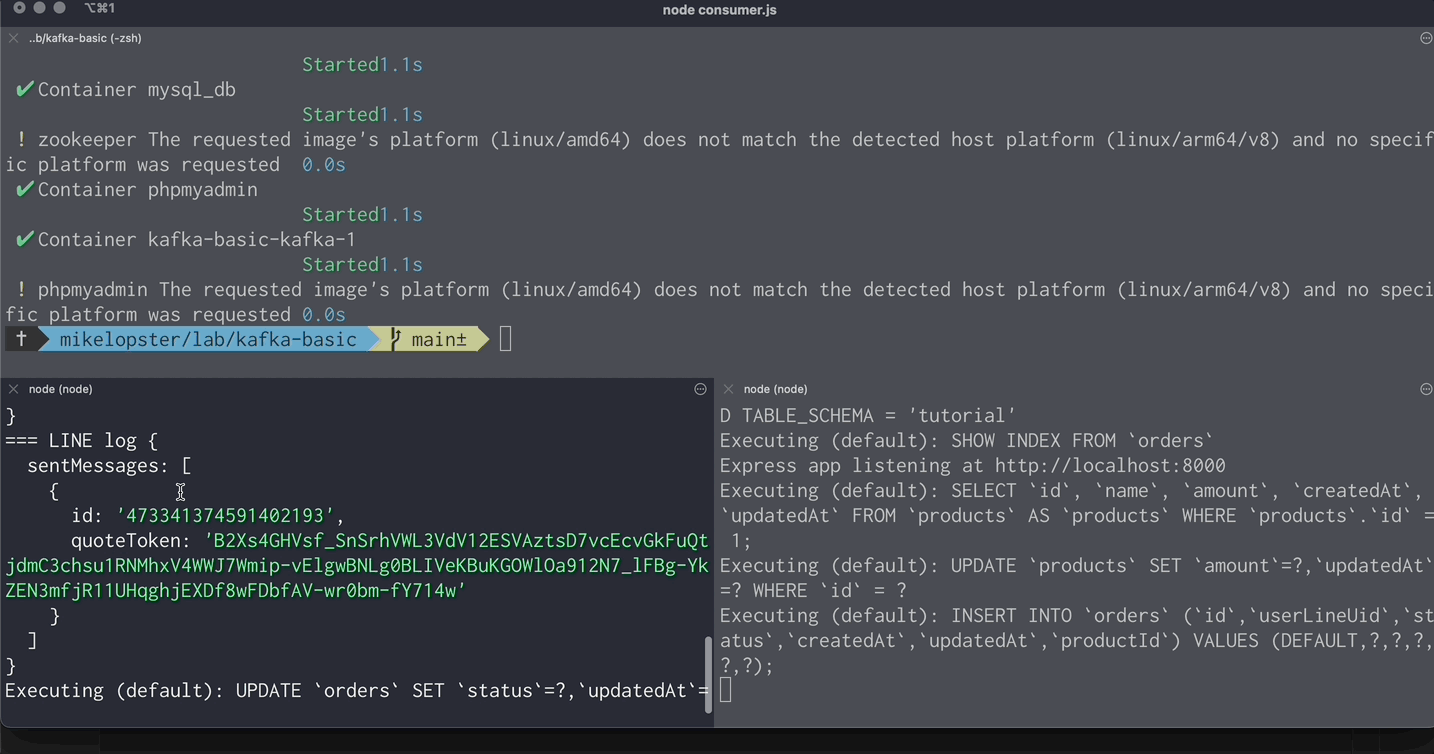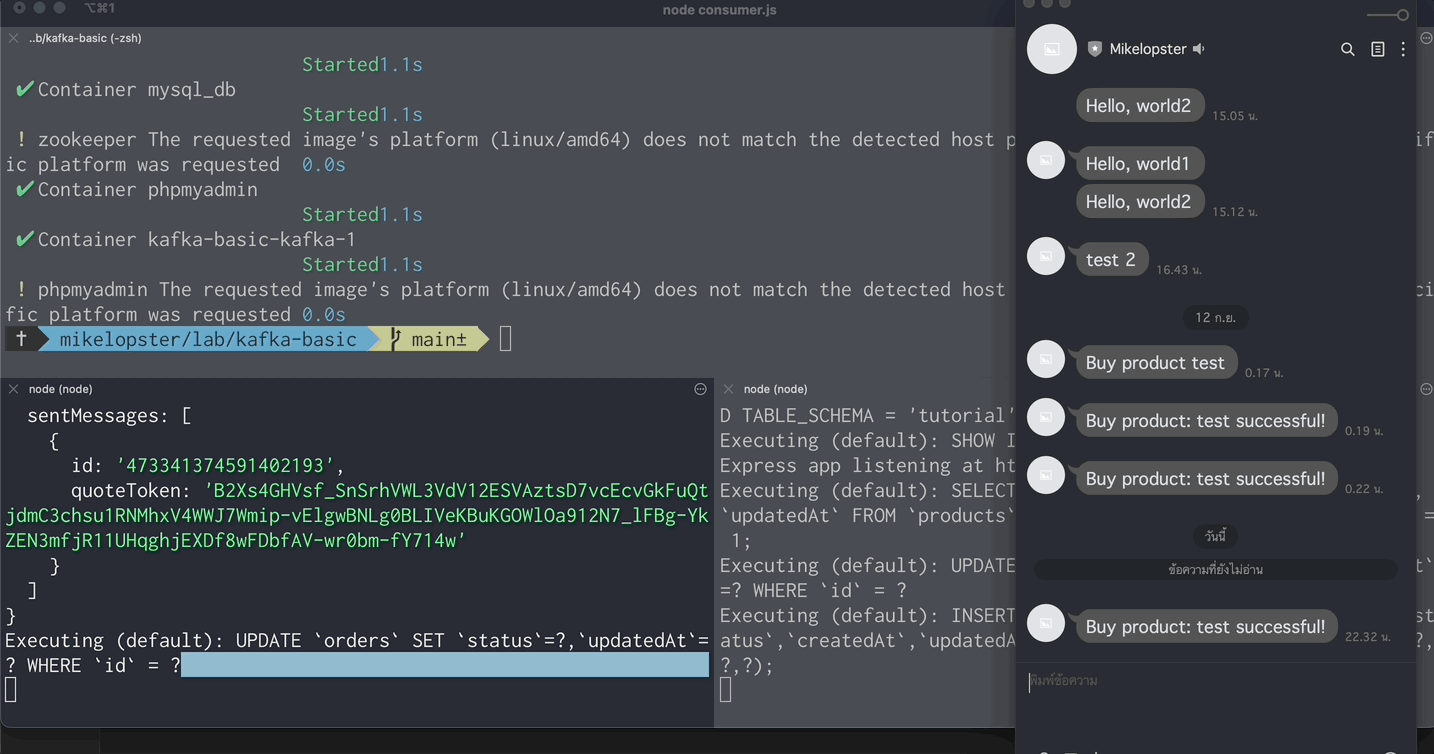
res.json({ message: `buy product ${product.name} successful. waiting message for confirm.`, }); } catch (error) { res.json({ message: "something wront", error, }); }});
app.listen(port, async () => { await sequelize.sync(); console.log(`Express app listening at http://localhost:${port}`);});ผลลัพธ์ตอน run producer (ใส่ภาพ)
ที่ consumer.js
สิ่งที่จะทำ
-
ยืนยันก่อนว่าได้ข้อมูลมาจาก producer ถูกต้องหรือไม่
-
เสร็จแล้วส่ง message Order success เข้า LINE ผ่าน messaging API ส่งได้ผ่าน API ใน document นี้ https://developers.line.biz/en/reference/messaging-api/#send-push-message
- ใช้ userid ของ liff ส่งไปได้เลย
- channel secret ดูใน developer ได้
-
หลังจากส่ง message success ให้ update status order ว่าเป็น status = success (ถือว่า Order สมบูรณ์)
const { Kafka } = require("kafkajs");const { Order } = require("./schema");const axios = require("axios");
require("dotenv").config();
const LINE_API_URL = "https://api.line.me/v2/bot/message/push";const LINE_ACCESS_TOKEN = process.env.LINE_ACCESS_TOKEN;
const kafka = new Kafka({ clientId: "express-app", brokers: ["localhost:9092", "localhost:9092"], // Adjust this if you are running inside a Docker container.});
const consumer = kafka.consumer({ groupId: "message-group" });
const run = async () => { // Consuming await consumer.connect(); await consumer.subscribe({ topic: "message-topic", fromBeginning: true });
await consumer.run({ eachMessage: async ({ topic, partition, message }) => { console.log("=== consumer message", JSON.parse(message.value.toString())); const messageData = JSON.parse(message.value.toString()); const headers = { "Content-Type": "application/json", Authorization: `Bearer ${LINE_ACCESS_TOKEN}`, };
const body = { to: messageData.userId, messages: [ { type: "text", text: `Buy product: ${messageData.productName} successful!`, }, ], };
try { const response = await axios.post(LINE_API_URL, body, { headers }); console.log("=== LINE log", response.data);
// send message complete = update order await Order.update( { status: "success", }, { where: { id: messageData.orderId, }, }, ); } catch (error) { console.log("error", error.response.data); } }, });};
run().catch(console.error);และต้องเพิ่ม .env เข้าไป
LINE_ACCESS_TOKEN=<your channel secret>ผลลัพธ์สุดท้ายที่ได้ออกมา
- ฝั่ง API (ที่มี Producer อยู่) ทำการรับข้อมูลจาก
POST /api/placeorder - หลังจากนั้นก็ส่งข้อมูลเข้า Producer เข้าไป
- และหลังจาก Consumer ได้รับข้อมูลจาก topic ที่ subscribe เอาไว้ = นำข้อมูลนั้นมาใช้เพื่อส่ง Message เข้า LINE
- และ update status order เป็น success
Github
https://github.com/mikelopster/kafkajs-example
Reference
- https://dev.to/chafroudtarek/how-to-integrate-kafka-with-nodejs—4bil
- https://medium.com/linedevth/apache-kafka-%E0%B8%89%E0%B8%9A%E0%B8%B1%E0%B8%9A%E0%B8%9C%E0%B8%B9%E0%B9%89%E0%B9%80%E0%B8%A3%E0%B8%B4%E0%B9%88%E0%B8%A1%E0%B8%95%E0%B9%89%E0%B8%99-2-core-concepts-7dfd4358ec04
- https://www.somkiat.cc/kafka-101/
- https://saixiii.com/apache-kafka/
- รู้จักกับ Design Pattern - Structural (Part 2/3)มี Video
มาเรียนรู้รูปแบบการพัฒนา Software Design Pattern ประเภทที่สอง Structural กัน

- รู้จักกับ Drizzle ORM ผ่าน Next.jsมี Video
มาทำความรู้จัก Drizzle ORM กัน ว่ามันคืออะไร และทำไมถึงเป็นที่นิยมในวงการนักพัฒนา และลองเล่นกับ Next.js ด้วยกัน

- มารู้จัก Svelte และ SvelteKit กันมี Video มี Github
สำรวจโลกแห่งการพัฒนาเว็บไซต์สมัยใหม่ด้วยการแนะนำ Svelte และ SvelteKit ที่ครอบคลุมของเรา

- ลองเล่น Stripe payment gateway กันมี Video มี Github
แนะนำ Stripe payment gateway ที่สามารถทำให้เราทำเว็บชำระเงินออกมาได้
