

Agent ส่งข้อมูลไปยัง Frontend ยังไง ?
/ 12 min read
 สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
สามารถดู video ของหัวข้อนี้ก่อนได้ ดู video
Agent ส่งข้อมูลไปยัง Frontend ยังไง ?
ต่อเนื่องจากหัวข้อก่อนหน้านี้ เมื่อเราสร้าง Agent ด้วย LangChain หรือ LangGraph เสร็จเรียบร้อยแล้ว คำถามสำคัญต่อมาคือ “เราจะเอา Agent ตัวนี้ไปเชื่อมต่อกับ client เช่น หน้าเว็บ (Frontend) ให้ User ใช้งานได้ยังไง?”
ในเชิง Architecture โดยทั่วไปเราจะมอง Agent เป็นเหมือน Backend Logic ตัวหนึ่ง ซึ่งการที่ Frontend จะคุยกับ Agent ได้นั้น จะต้องทำผ่าน API โดยรูปแบบการเชื่อมต่อที่นิยมใช้กันในปัจจุบันจะมีอยู่ 2 วิธีหลักๆ คือ:
- ใช้งานผ่าน Agent Server โดยตรง: คือการนำ Agent ไป Deploy บน Engine ที่รองรับ (เช่น Agent Server บน GCP หรือ LangSmith) ซึ่งระบบเหล่านี้จะมี API มาตรฐานเตรียมไว้ให้ ฝั่ง Client สามารถเรียกใช้งานผ่าน SDK ได้ทันที
- สร้าง Backend API มาครอบ (Wrapper / API Gateway): คือการเขียน Backend Server (เช่น FastAPI หรือ Node.js) ขึ้นมาคั่นกลาง ทำหน้าที่รับ Request จาก Frontend ตรวจสอบสิทธิ์ (Authentication) หรือจัดการ Business Logic อื่นๆ ก่อน แล้วจึงค่อยส่งคำสั่งไปเรียก Agent ให้ทำงานอีกที (ซึ่งบทความนี้จะเน้นไปที่การใช้ FastAPI ในการครอบ Agent ครับ)
และเมื่อพูดถึง รูปแบบการส่งข้อมูล ระหว่าง Client และ Agent จะแบ่งออกเป็น 2 ท่าหลักๆ ที่เราต้องรู้ ได้แก่:
- REST API: เป็นการทำงานแบบ Request-Response พื้นฐาน คือ Frontend ส่งคำถาม (Prompt) เข้าไป แล้วต้อง “รอ” จนกว่า Agent (หรือ LLM) จะประมวลผลเสร็จสมบูรณ์ทั้งก้อน จึงจะส่งคำตอบกลับมาทีเดียว ข้อดีคือทำง่าย คุ้นเคยกันดี แต่ข้อเสียคือหาก Agent ต้องคิดซับซ้อน หรือ LLM ใช้เวลา Gen นานๆ อาจทำให้หน้าเว็บดูเหมือนค้าง หรือเกิด Timeout ได้
- Streaming (Server-Sent Events - SSE): เป็นเทคนิคที่เกิดมาเพื่อแก้ปัญหาการรอคอยของ LLM โดยเฉพาะ (ให้ความรู้สึกเหมือนกำลังพิมพ์คุยกับ ChatGPT) วิธีนี้ Server จะเปิดช่องทางการเชื่อมต่อ (ท่อ) เอาไว้ และเมื่อ LLM ค่อยๆ Gen คำตอบออกมาทีละคำ (Token) ตัว Backend ก็จะ “ทยอยพ่นข้อความ (Stream)” กลับไปให้ Frontend แสดงผลแบบ Real-time ทันที วิธีนี้จะช่วยเพิ่ม User Experience (UX) ให้ดีขึ้นมาก
ในตัวอย่างด้านล่างนี้ เราจะพาทุกคนไปลองทำ API ทั้งแบบ REST API ทั่วไป และแบบ Streaming (SSE) โดยใช้ FastAPI ทำหน้าที่เป็น Backend Gateway กัน
Example 1 - Rest API
ตัวอย่าง code Agent ที่เราจะใช้
ตัวอย่างแรกสุดนี้เราจะ สร้าง agent ง่ายๆลอง LangGraph ขึ้นมา (แบบเดียวกับตัวอย่างแรกสุดของหัวข้อ LangGraph ที่เป็น Agent มุกตลกง่ายๆ) เสร็จแล้วการต่อเข้า langgraph dev เพื่อเปิด API ออกมาผ่าน port 2024 ให้ฝั่ง Client สามารถต่อเข้าไป
ตัวอย่าง code Agent ของ LangGraph
from typing import TypedDictfrom langgraph.graph import StateGraph, START, END
# 1. กำหนด State (หน่วยความจำส่วนกลาง)class State(TypedDict): topic: str joke: str
# 2. สร้าง Node (ฟังก์ชันการทำงานของเอเจนต์)def generate_joke(state: State): topic = state["topic"] # ในการใช้งานจริงตรงนี้จะเป็นการเรียกใช้ LLM new_joke = f"ทำไม {topic} ถึงไปโรงเรียน? เพราะอยากมีความรู้ไงล่ะ!" return {"joke": new_joke}
# 3. สร้าง StateGraph และประกอบร่าง (Wire it together)builder = StateGraph(State)
# เพิ่ม Node ลงไปในกราฟbuilder.add_node("generate_joke", generate_joke)
# กำหนดเส้นทางเดินของกราฟbuilder.add_edge(START, "generate_joke")builder.add_edge("generate_joke", END)
# 4. Compile เพื่อให้กราฟพร้อมใช้งานgraph = builder.compile()ท่าที่ 1 - FastAPI ด้วยวิธี get_client
ท่าแรกเราจะใช้เครื่องมือมาตรฐานที่ทาง LangGraph เตรียมมาให้ นั่นคือการเรียกผ่าน langgraph_sdk
- วิธีนี้เหมาะมากเวลาที่เรามีการ Deploy ตัว Agent แยกเอาไว้บน LangGraph Server ต่างหาก (หรือในกรณีนี้คือตอนที่เราใช้คำสั่ง
langgraph devเพื่อรันเซิร์ฟเวอร์จำลองบนเครื่องตัวเอง) - Concept ของวิธีนี้คือ เราจะใช้คำสั่ง
get_clientเพื่อสร้าง “สะพานเชื่อม” ระหว่าง FastAPI ของเราไปยัง Agent Server จากนั้นเมื่อมี Request เข้ามา - ตัว application ของเราจะสั่งให้ Agent Server ทำการสร้าง Thread, สั่งรัน Graph ตาม Input ที่ส่งไป, รอจนกว่าจะทำงานเสร็จ และดึงผลลัพธ์จาก State ล่าสุดกลับมาส่งให้ผู้ใช้
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom langgraph_sdk import get_client
# กำหนด URL ของ LangGraph Server ที่ได้จากคำสั่ง `langgraph dev`LANGGRAPH_URL = "http://localhost:2024"
# สร้าง FastAPI Appapp = FastAPI(title="Joke Agent API", description="API สำหรับเรียกใช้งาน LangGraph Agent")
# สร้าง LangGraph Client เพื่อติดต่อกับ Serverclient = get_client(url=LANGGRAPH_URL)
# สร้าง Request Modelclass JokeRequest(BaseModel): topic: str
# สร้าง Response Modelclass JokeResponse(BaseModel): topic: str joke: str
@app.post("/generate_joke", response_model=JokeResponse)async def generate_joke(request: JokeRequest): try: # ชื่อของ graph ที่ตั้งไว้ใน langgraph.json assistant_name = "my_joke_agent"
# 1. สร้าง Thread ใหม่สำหรับการรัน Agent ครั้งนี้ thread = await client.threads.create() thread_id = thread["thread_id"]
# 2. เตรียมข้อมูลเริ่มต้น (Input State) input_data = {"topic": request.topic}
# 3. รัน Agent (ใช้ wait เพื่อรอจนจบการทำงาน) await client.runs.wait( thread_id=thread_id, assistant_id=assistant_name, input=input_data )
# 4. ดึงข้อมูล State ล่าสุดออกจาก Thread เมื่อการทำงานเสร็จสิ้น state = await client.threads.get_state(thread_id)
# ผลลัพธ์สุดท้ายจะอยู่ใน state["values"] result_joke = state["values"].get("joke", "ไม่สามารถสร้างมุกตลกได้")
return JokeResponse(topic=request.topic, joke=result_joke)
except Exception as e: raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__": import uvicorn # รัน FastAPI Server ด้วย uvicorn บน port 8000 uvicorn.run(app, host="0.0.0.0", port=8000)อธิบาย code
- get_client(): สร้างการเชื่อมต่อไปยัง LangGraph Server ตาม URL ที่ระบุไว้
- สร้าง Endpoint
/generate_joke: เป็น POST request สำหรับรับค่าtopic - client.threads.create(): สร้าง Thread ใหม่สำหรับการคุยรอบนี้ (เพื่อให้ Agent สามารถจำ History ได้ตามรอบการสนทนานั้นๆ)
- client.runs.wait(): เป็นคำสั่งให้เรียกใช้งาน Graph
my_joke_agent(ชื่อเดียวกับในlanggraph.json) และส่งค่า Input state เข้าระบบ จากนั้นจะรอ จนกว่า Agent จะรันหมดตามขั้นตอนใน Flow ที่กำหนด - client.threads.get_state(): ดึง state ล่าสุดจาก Thread และนำค่า
jokeที่ได้จากการประมวลผลมาตอบกลับ
ตัวอย่าง curl
curl -X POST "http://localhost:8000/generate_joke" \ -H "Content-Type: application/json" \ -d '{ "topic": "แมวกับคอมพิวเตอร์" }'ท่าที่ 2 - ท่า RemoteGraph
ref: https://docs.langchain.com/langsmith/use-remote-graph
RemoteGraph คือ interface ฝั่ง Client-side ที่ช่วยให้สามารถโต้ตอบกับ Agent ที่ Deploy ไว้บน Agent Server ได้เสมือนว่ากราฟหรือ Agent นั้นๆ ทำงานอยู่บนเครื่องของคุณเอง
เหตุผลที่ RemoteGraph ถูกนำมาใช้งานร่วมกับ application ได้
- มี API รูปแบบเดียวกับ Local Graph (API Parity):
RemoteGraphถูกออกแบบมาให้รองรับ method มาตรฐานของCompiledGraphได้ทั้งหมด เช่น.invoke(),.stream(),.get_state()และ.update_state()ทำให้คุณใช้คำสั่งเดียวกันนี้เชื่อมต่อกับระบบในระดับ Production ได้ทันที - รองรับการทำงานแบบ Asynchronous เต็มรูปแบบ:
RemoteGraphมี Client ที่รองรับการทำงานแบบ Async เช่นการเรียก.ainvoke()และ.astream() - การแยกส่วน application และ server คุณสามารถแยกระบบเว็บ application ของคุณออกจากการประมวลผลกราฟ โดยการส่งคำสั่งผ่าน URL ไปยัง Agent Server ได้เลย เพียงแค่ตั้งค่าการเชื่อมต่อด้วยชื่อกราฟ (หรือ Assistant ID) และระบุ URL ปลายทางของเซิร์ฟเวอร์
- ลดภาระการจัดการสถานะ (Thread-level persistence): ระบบ Agent Server จะทำหน้าที่รับผิดชอบการจำสถานะและหน่วยความจำของบทสนทนา (Threads) ให้ทั้งหมด ฝั่ง FastAPI ของคุณจึงเป็นเพียงทางผ่าน (API Gateway) ที่รับคำสั่งจากผู้ใช้แล้วส่งต่อไปยัง
RemoteGraphเท่านั้น - ความยืดหยุ่นและการทำงานแบบแยกส่วน (Subgraph embedding): หากคุณพัฒนา application ที่ต้องใช้เวิร์กโฟลว์ซับซ้อน
RemoteGraphสามารถถูกนำไปฝังตัวเป็นโหนดย่อย (Subgraph) ในกราฟอื่นๆ หรือถูกใช้เป็นเครื่องมือ (Tools) ที่เรียกใช้ข้ามการ Deploy ระหว่างกันได้
ตัวอย่าง code การเรียกใช้
import asynciofrom langgraph.pregel.remote import RemoteGraph
async def main(): # 1. ชี้ URL ไปที่ LangGraph Dev Server url = "http://localhost:2024"
# 2. อ้างอิงชื่อกราฟให้ตรงกับที่ตั้งไว้ใน langgraph.json remote_graph = RemoteGraph("my_joke_agent", url=url)
# 3. กำหนด Input โดย Key ต้องตรงกับที่นิยามไว้ใน `State` ของคุณ inputs = {"topic": "ไดโนเสาร์"}
print("=== ทดสอบแบบเรียกครั้งเดียว (Invoke) ===") result = await remote_graph.ainvoke(inputs) print("ผลลัพธ์:", result)
print("\n=== ทดสอบแบบสตรีม (Stream) ===") # สตรีมผลลัพธ์ทีละสเต็ปการทำงานของกราฟ async for chunk in remote_graph.astream(inputs): print("Chunk:", chunk)
if __name__ == "__main__": asyncio.run(main())เมื่อลองมาเรียกใช้ FastAPI
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom langgraph.pregel.remote import RemoteGraphimport uvicorn
app = FastAPI(title="RemoteGraph API", description="API สำหรับเรียกใช้งาน LangGraph ผ่าน RemoteGraph")
# 1. ชี้ URL ไปที่ LangGraph Dev Serverurl = "http://localhost:2024"
# 2. อ้างอิงชื่อกราฟให้ตรงกับที่ตั้งไว้ใน langgraph.jsonremote_graph = RemoteGraph("my_joke_agent", url=url)
# สร้าง Request Modelclass JokeRequest(BaseModel): topic: str
# สร้าง Response Modelclass JokeResponse(BaseModel): topic: str joke: str
@app.post("/invoke", response_model=JokeResponse)async def invoke_joke_api(request: JokeRequest): try: # 3. กำหนด Input โดย Key ต้องตรงกับที่นิยามไว้ใน `State` ของคุณ inputs = {"topic": request.topic}
# เรียกกราฟให้ทำงานจนจบทีเดียวและคืนค่าออกมา result = await remote_graph.ainvoke(inputs)
# ค่าจะอยู่ใน object `result` joke = result.get("joke", "ไม่สามารถสร้างมุกตลกได้")
return JokeResponse(topic=request.topic, joke=joke)
except Exception as e: raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__": # รัน FastAPI Server ด้วย uvicorn บน port 8001 เผื่อหลีกเลี่ยงพอร์ตชนกับตัวอื่น uvicorn.run(app, host="0.0.0.0", port=8000)ท่าที่ 3 - ลองกับ LangChain บ้าง
ทีนี้เราจะลองมาเปลี่ยนเป็น Agent ที่มีเรื่องของระยะเวลารอบ้าง = เคสที่สามารถลองได้ง่ายที่สุดนั่นคือนำ Agent ต่อเข้ากับ LLM
- อย่างที่เราเคยบอกในหัวข้อ LangChain ว่า LangChain ใช้ LangGraph เป็น runtime ในการ run เบื้องหลัง
- ดังนั้นเราสามารถใช้ท่า
create_agentเพื่อสร้าง Agent แบบเดียวกับ LangGraph ขึ้นมา และสามารถ import เข้าlanggraph.jsonเพื่อเรียกใช้งานผ่านlanggraph devเพื่อสร้าง API ได้เช่นกัน
เช่น จาก code LangChain ตามด้านล่างนี้
from langchain.agents import create_agentfrom langchain_google_genai import ChatGoogleGenerativeAI
# 1. กำหนด System Prompt สำหรับ Agent มุกตลกSYSTEM_PROMPT = """คุณคือ AI นักเดี่ยวไมโครโฟนมืออาชีพและผู้เชี่ยวชาญด้านการคิดมุกตลกหน้าที่ของคุณคือการตอบคำถามและสนทนากับผู้ใช้ด้วยอารมณ์ขัน มุกแป้ก มุกคำผวน หรือการเล่นมุกตลกที่สร้างสรรค์เสมอ"""
# 2. เริ่มต้นใช้งานโมเดลmodel = ChatGoogleGenerativeAI(model="gemini-2.5-flash-lite")
# 3. สร้าง Agent โดยส่ง system_prompt เข้าไปagent = create_agent( model=model, system_prompt=SYSTEM_PROMPT)เพิ่มลงใน langgraph.json
{ "dependencies": ["."], "graphs": { "my_joke_agent_langchain": "./agent-langchain.py:agent" }, "env": ".env"}หากลอง run ด้วย langgraph dev ก็จะสามารถคุยกับ Agent ได้เหมือนกับ LangGraph
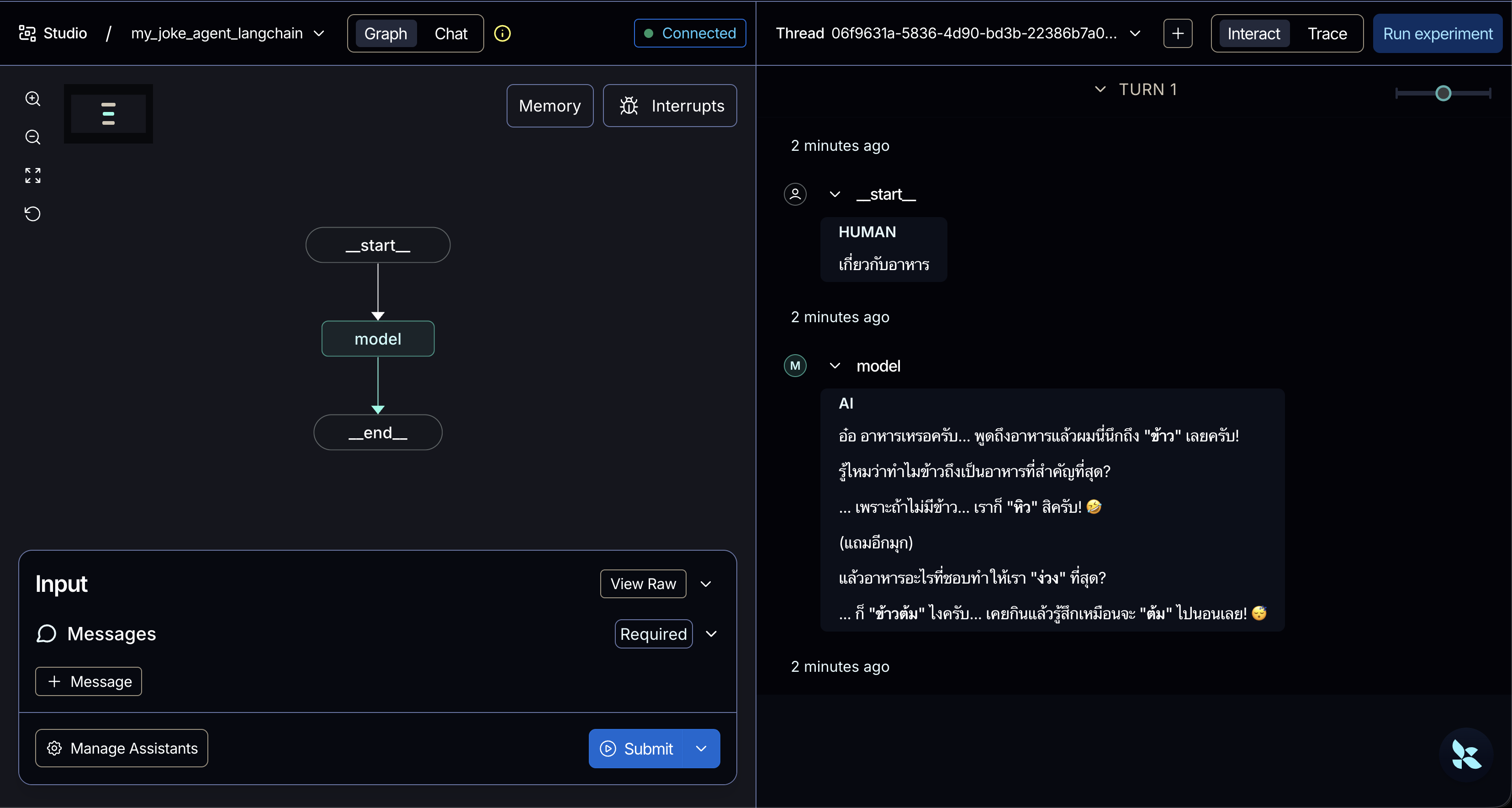
ก็เท่ากับว่า มันสามารถใช้ท่าเดียวกันในการ import เรียกจาก FastAPI เข้าไปได้เช่นกัน
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom langgraph.pregel.remote import RemoteGraphimport uvicorn
LANGGRAPH_URL = "http://localhost:2024"
app = FastAPI(title="Joke Agent API", description="API สำหรับเรียกใช้งาน LangGraph Agent")
remote_graph = RemoteGraph("my_joke_gemini", url=LANGGRAPH_URL)
# สร้าง Request Modelclass JokeRequest(BaseModel): topic: str
# สร้าง Response Modelclass JokeResponse(BaseModel): topic: str joke: str
@app.post("/invoke", response_model=JokeResponse)async def invoke_joke_api(request: JokeRequest): try: inputs = { "messages": [("user", f"ช่วยคิดมุกตลกเกี่ยวกับ: {request.topic}")] }
result = await remote_graph.ainvoke(inputs)
final_answer = result["messages"][-1]["content"]
return JokeResponse(topic=request.topic, joke=final_answer)
except Exception as e: raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__": # รัน FastAPI Server ด้วย uvicorn บน port 8000 uvicorn.run(app, host="0.0.0.0", port=8000)ตัวอย่าง curl
curl -X 'POST' \ 'http://localhost:8002/invoke' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "topic": "ไก่ทอด"}'result
{"topic":"ไก่ทอด","response":"โอ้โห! ไก่ทอดนี่มันเป็นอะไรที่... ทอดแล้วทอดอีก! (แป้ก!)\n\nเอาล่ะ มาเข้าเรื่องกันดีกว่า\n\n* **ไก่ทอดอะไรที่ชอบไปทะเล?**\n ... ไก่ทอด \"เกลือ\" ไง! (ฮ่า... ฮ่า... ฮ่า... เงียบ)\n\n* **ทำไมไก่ถึงข้ามถนน?**\n ... ก็เพราะว่ามันเห็นร้านไก่ทอดอยู่อีกฝั่งไง! (อันนี้พอได้!)\n\n* **ถ้าไก่ทอดไปเรียนหนังสือ จะเรียนวิชาอะไรเก่งที่สุด?**\n ... วิชา \"ทอด\" สะพาน! (อุ๊ย! เกินคาด!)\n\n* **ไก่ทอดอะไรที่พูดไม่เก่ง?**\n ... ไก่ทอด \"เงียบ\" (แป้กอีกแล้ว!)\n\n* **เคยได้ยินเรื่องไก่ทอดที่โดนจับมั้ย?**\n ... โดนข้อหา \"ทอด\" ทิ้งความอร่อย! (อันนี้ก็พอได้นะ!)\n\n* **ไก่ทอดอะไรที่ชอบกินน้ำ?**\n ... ไก่ทอด \"น้ำจิ้ม\" ไง! (เอ่อ... มันก็ใช่นะ)\n\n* **ถ้าไก่ทอดมีโซเชียลมีเดีย จะโพสต์อะไร?**\n ... \"วันนี้อร่อยนะ... กรอบนอกนุ่มใน... พร้อมเสิร์ฟ!\" (อันนี้เห็นภาพเลย!)\n\n* **สุดท้าย... ทำไมไก่ถึงไม่ชอบไปโรงหนัง?**\n ... เพราะกลัวโดน \"ทอด\" ในโรง! (โอ้โห... เล่นใหญ่ไปหน่อย!)\n\nเป็นไงบ้างครับ? พอจะทำให้ท้องร้องได้บ้างมั้ย? ถ้ายังไม่หนำใจ บอกมาเลยนะ ผมยังมีไก่ทอดอีกเป็นเข่ง! (หมายถึงมุกนะ ไม่ใช่ไก่จริงๆ เดี๋ยวจะหาว่าไม่เตือน!)"}Example 2 - Stream (SSE)
ทีนี้ข้อจำกัดของ REST API แบบปกติคือฝั่ง Client “ต้องรอ” จนกว่า LLM จะคิดคำตอบเสร็จทั้งก้อน ยิ่งถ้า LLM ต้องตอบยาวๆ ผู้ใช้งานอาจจะรู้สึกว่าเว็บค้างหรือตอบสนองช้าไปเลย
ดังนั้น ใน Example 2 นี้ เราจะมาแก้ปัญหานั้นด้วยเทคนิค Server-Sent Events (SSE) เพื่อทำ Streaming API จุดสำคัญที่เปลี่ยนไปคือ เราจะเปลี่ยนจากการใช้คำสั่ง .ainvoke() (เรียกทีเดียวจบ) มาเป็นคำสั่ง .astream() (ค่อยๆ ทยอยรับข้อมูล) แทน
ในมุมของ FastAPI การทำแบบนี้ก็ไม่ยากครับ เราจะใช้สิ่งที่เรียกว่า StreamingResponse ร่วมกับการสร้าง function แบบ Generator (ใช้คำสั่ง yield) เพื่อคอยดักจับว่ามีคำ (Token) ไหนถูกพ่นออกมาจาก Agent บ้าง แล้วให้ FastAPI รีบ “พ่นต่อ” ไปยัง Frontend แบบ Real-time ทันที
มาดูวิธีประยุกต์ใช้ทั้งกับ LangChain และ LangGraph กัน
ท่าที่ 1 - ใช้กับ LangChain ที่มี LLM
เราจะยังคงให้ FastAPI เป็น API Gateway และใช้ RemoteGraph เชื่อมต่อไปยัง Agent Server (langgraph dev) เหมือนเดิมครับ แต่สิ่งที่เพิ่มเข้ามาคือการใช้พารามิเตอร์ stream_mode="messages" เพื่อบอกให้เซิร์ฟเวอร์ส่งข้อมูลกลับมาทีละคำ (Token) ทันทีที่ LLM คิดออก จากนั้นเราค่อยใช้ function Generator ของ Python คอยดักจับและ yield ข้อมูลนั้นออกไปในรูปแบบของ Server-Sent Events (SSE) แบบ Real-time
เช่นตาม code ด้านล่างนี้
from fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom pydantic import BaseModelfrom langgraph.pregel.remote import RemoteGraphimport uvicornimport json
app = FastAPI( title="RemoteGraph API (Langchain Agent)", description="API สำหรับเรียกใช้งาน Langchain Agent ผ่าน RemoteGraph",)
url = "http://localhost:2024"remote_graph = RemoteGraph("my_joke_agent_langchain", url=url)
class JokeRequest(BaseModel): topic: str
class JokeResponse(BaseModel): topic: str response: str
@app.post("/stream")async def stream_joke_api(request: JokeRequest): async def event_generator(): inputs = {"messages": [("user", f"ช่วยคิดมุกตลกเกี่ยวกับ: {request.topic}")]}
try: # 1. เปลี่ยนเป็น stream_mode="messages" และระบุ version="v2" [3, 4] async for chunk in remote_graph.astream( inputs, stream_mode="messages", version="v2" ): # 2. ตรวจสอบว่าประเภทของ chunk คือ messages if chunk.get("type") == "messages": # 3. ข้อมูล Message จะถูกเก็บอยู่ในคีย์ "data" ตำแหน่งที่ 0 message_chunk = chunk["data"][0] content = message_chunk.get("content", "")
if content: data_to_send = {"token": content} yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
except Exception as e: yield f"data: {json.dumps({'error': str(e)}, ensure_ascii=False)}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8002)ตัวอย่าง curl
curl -N -X POST http://localhost:8002/stream \ -H "Accept: text/event-stream" \ -H "Content-Type: application/json" \ -d '{"topic": "โปรแกรมเมอร์"}'ตัวอย่างผลลัพธ์
data: {"token": "ได้"}
data: {"token": "เลย! โปรแกรมเมอร์เนี่ยนะ... เป็นอาชีพที่น่าสนใจสุด"}
data: {"token": "ๆ ไปเลย\n\nว่าแต่... คุณเคยได้ยินเรื่องโปรแกรมเมอร์คนนั้นไหม?\n\nเขาไปหาหมอ แล้วบอกว่า \"หมอครับ ผมรู้สึกเหมือนตัวเองเป็นเครื่องคิดเลขเลยครับ\"\n\nหมอก็เลย"}
data: {"token": "ถามว่า \"ทำไมคุณถึงคิดแบบนั้นล่ะ?\"\n\nโปรแกรมเมอร์ก็ตอบว่า \"ก็... ผมรู้สึกว่าผมกำลัง **คำนวณ** อะไรบางอย่างตลอดเวลาเลยครับ!\"\n\n(เสียงหัวเราะแห"}
data: {"token": "้งๆ)\n\nหรืออีกมุกนะ...\n\nทำไมโปรแกรมเมอร์ถึงชอบไปทะเล?\n\nเพราะที่นั่นมี **คลื่น** ที่เขาคุ้นเคย! (Waves! เหมือนกับคลื่นในโค้ดน"}
data: {"token": "่ะ ฮิ้วววว)\n\nเอ้า... เอาไปอีกอัน!\n\nโปรแกรมเมอร์กับนักคณิตศาสตร์เดินเข้าไปในบาร์...\n\nนักคณิตศาสตร์สั่งเครื่องดื่ม 1 แก้ว\nโปรแกรมเม"}
data: {"token": "อร์สั่งเครื่องดื่ม 0 แก้ว\nนักคณิตศาสตร์สงสัย เลยถามว่า \"ทำไมคุณไม่สั่งล่ะ?\"\nโปรแกรมเมอร์ตอบว่า \"ผมสั่ง **null** ไปแล้วครับ!\"\n\n(เงียบก"}
data: {"token": "ริบ)\n\nหวังว่าจะถูกใจนะครับ! ถ้าอยากได้มุกเกี่ยวกับโปรแกรมเมอร์อีก บอกมาได้เลยนะ! ผมมีคลังมุกแป้กพร้อมเสิร์ฟเสมอ! 😉"}ท่าที่ 2 - ใช้กับ LangGraph
เพื่อให้การใช้ Agent SSE บน LangGraph เห็นภาพจะขอเปลี่ยน Agent เป็นตามด้านล่างนี้แทน (นั่นก็คือใส่ LLM เข้าไปในแต่ละ process ของ node นั่นแหละ)
import asyncioimport dotenvfrom typing import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langchain_google_genai import ChatGoogleGenerativeAI
dotenv.load_dotenv()
# 1. กำหนด State (เพิ่มช่องเก็บมุกที่ขยี้แล้ว)class State(TypedDict): topic: str joke: str final_joke: str
# 2. เริ่มต้นโมเดล LLMmodel = ChatGoogleGenerativeAI(model="gemini-2.5-flash-lite")
# 3. สร้าง Nodes การทำงาน (แนะนำให้ใช้ async def คู่กับ .ainvoke เพื่อให้สตรีมทำงานได้ลื่นไหล)async def write_joke(state: State): topic = state["topic"] # ให้ LLM คิดมุกตลกร่างแรก response = await model.ainvoke([ {"role": "user", "content": f"ช่วยคิดมุกตลกสั้นๆ เกี่ยวกับ '{topic}' หน่อย"} ]) return {"joke": response.content}
async def polish_joke(state: State): joke = state["joke"] # นำมุกตลกร่างแรกไปขยี้ต่อ response = await model.ainvoke([ {"role": "user", "content": f"จากมุกตลกนี้ ช่วยขยี้ให้มันตลกขึ้นหรือหักมุมแบบกวนๆ หน่อย:\n{joke}"} ]) return {"final_joke": response.content}
# 4. ประกอบร่าง StateGraph แบบมีหลายขั้นตอนbuilder = StateGraph(State)
builder.add_node("write_joke", write_joke)builder.add_node("polish_joke", polish_joke)
builder.add_edge(START, "write_joke")builder.add_edge("write_joke", "polish_joke")builder.add_edge("polish_joke", END)
# Compile กราฟให้พร้อมใช้งานgraph = builder.compile()เมื่อนำมาใช้ร่วมกับ FastAPI ท่าก็จะคล้ายๆเดิม แต่ก็จะต้องมีการดักจับ node ให้ถูกต้อง
from fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom pydantic import BaseModelfrom langgraph.pregel.remote import RemoteGraphimport uvicornimport json
app = FastAPI( title="RemoteGraph API (Custom Prompt Chaining Agent)", description="API สำหรับเรียกใช้งาน LangGraph Agent ผ่าน RemoteGraph",)
# 1. ชี้ URL ไปที่ LangGraph Dev Serverurl = "http://localhost:2024"
# 2. ระบุชื่อกราฟให้ตรงกับที่ตั้งไว้ใน langgraph.jsonremote_graph = RemoteGraph("my_joke_agent_langgraph", url=url)
class JokeRequest(BaseModel): topic: str
@app.post("/stream")async def stream_joke_api(request: JokeRequest): async def event_generator(): # 3. เปลี่ยน Input ให้ตรงกับ State Schema ของ Agent ตัวใหม่ (ส่งแค่ topic) inputs = {"topic": request.topic}
try: # 4. เรียกใช้ .astream() โดยขอข้อมูลทั้ง "messages" (ทีละคำ) และ "updates" (ตอนจบโหนด) [1] async for chunk in remote_graph.astream( inputs, stream_mode=["messages", "updates"], version="v2" ): # กรณีที่ 1: ดักจับข้อมูล Stream แบบทีละคำ (Token) [2] if chunk.get("type") == "messages": # ผ่าน RemoteGraph ข้อมูล tuple จะถูกแปลงเป็น JSON list [message_chunk, metadata] message_chunk = chunk["data"][0] content = message_chunk.get("content", "")
if content: data_to_send = {"type": "token", "content": content} yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
# กรณีที่ 2: ดักจับข้อมูลตอนจบแต่ละ Node (Updates) elif chunk.get("type") == "updates": # ข้อมูลใน updates จะอยู่ในรูปแบบ { "ชื่อโหนด": { ข้อมูล State ที่อัปเดต } } for node_name, state in chunk["data"].items(): # ดึงข้อมูลตามโหนด เช่น โหนด write_joke จะได้คีย์ "joke", polish_joke จะได้ "final_joke" update_content = state.get("final_joke") or state.get("joke", "")
if update_content: data_to_send = { "type": "node_complete", "node": node_name, "content": update_content } yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
except Exception as e: yield f"data: {json.dumps({'error': str(e)}, ensure_ascii=False)}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8002)ตัวอย่างเรียก curl
curl -N -X POST http://localhost:8002/stream \ -H "Accept: text/event-stream" \ -H "Content-Type: application/json" \ -d '{"topic": "ความรัก"}'ตัวอย่างผลลัพธ์
data: {"type": "token", "content": "แน่นอนครับ"}
data: {"type": "token", "content": " นี่คือมุกตลกสั้นๆ เกี่ยวกับ \"ความรัก\" ครับ"}
data: {"type": "token", "content": ":\n\n---\n\n**มุก 1:**\n\n> ถาม: ทำไมความรักถึงเหมือนกับ Wi-Fi?\n> ตอบ: เพราะบางทีก็หาไม่เจอ... แล้วบางทีก็เจอแต่สัญญาณอ่อน!\n\n---\n\n**มุก"}
data: {"type": "token", "content": " 2:**\n\n> ผู้ชาย: ฉันรักเธอเหมือนหมูรักไข่เจียวเลยนะ!\n> ผู้หญิง: แปลว่าอะไร?\n> ผู้ชาย: ก็... จะกินทุกเมื่อที่หิว!\n\n---\n\n**ม"}
data: {"type": "token", "content": "ุก 3:**\n\n> คุณครู: นักเรียนรู้ไหมว่าความรักคืออะไร?\n> เด็กชาย: ความรักก็คือ... เวลาที่เรายอมให้คนอื่นกินชิ้นเค้กชิ้นสุดท้ายก่อนเราครับ"}
data: {"type": "token", "content": "!\n\n---\n\n**มุก 4:**\n\n> แฟน: ที่รัก... เธอคิดว่าฉันฉลาดไหม?\n> อีกฝ่าย: ก็... ฉลาดพอที่จะทำให้ฉันรักเธอได้นะ!\n\n---\n\n**"}Example 3 - นำ Agent มาใช้ร่วมกับ FastAPI
สำหรับคนที่อาจจะมองว่าท่าที่ผ่านมามันให้ feel เหมือนต้องมา deploy agent แยกกันกับ application ซึ่งบางทีเราอาจจะแค่ deploy backend ไปพร้อมกับ Agent เลย
ใน Example 3 นี้ เราจะมาดูอีกหนึ่งทางเลือกที่ Basic และตรงไปตรงมาที่สุดครับ นั่นคือการ “ฝัง (Embed) Agent เข้าไปใน application ของเราโดยตรง” เลย
แทนที่เราจะต้องไปรัน Agent Server แยกต่างหาก (แบบที่ต้องใช้คำสั่ง langgraph dev แล้วใช้ RemoteGraph ยิงไปหา) เราสามารถเขียน code สร้าง Agent ไว้ในไฟล์ Python ไฟล์หนึ่ง แล้วใช้คำสั่ง import ดึงตัว Agent หรือ Graph ที่ Compile เสร็จแล้ว เข้ามาใช้งานในไฟล์ FastAPI ของเราได้ทันทีครับ
ท่าที่ 1 - กับ LangChain
from fastapi import FastAPI, HTTPExceptionfrom fastapi.responses import StreamingResponsefrom pydantic import BaseModelfrom agentLangchain import agentimport uvicornimport json
app = FastAPI(title="Joke Agent API", description="API สำหรับเรียกใช้งาน LangGraph Agent")
# สร้าง Request Modelclass JokeRequest(BaseModel): topic: str
# สร้าง Response Modelclass JokeResponse(BaseModel): topic: str joke: str
@app.post("/invoke", response_model=JokeResponse)async def invoke_joke_api(request: JokeRequest): try: inputs = { "messages": [("user", f"ช่วยคิดมุกตลกเกี่ยวกับ: {request.topic}")] }
result = await agent.ainvoke(inputs)
final_answer = result["messages"][-1].content
return JokeResponse(topic=request.topic, joke=final_answer)
except Exception as e: raise HTTPException(status_code=500, detail=str(e))
@app.post("/stream")async def stream_joke_api(request: JokeRequest): async def event_generator(): inputs = {"messages": [("user", f"ช่วยคิดมุกตลกเกี่ยวกับ: {request.topic}")]}
try: # 1. เปลี่ยนเป็น stream_mode="messages" และระบุ version="v2" [3, 4] async for chunk in agent.astream( inputs, stream_mode="messages", version="v2" ): # 2. ตรวจสอบว่าประเภทของ chunk คือ messages if chunk.get("type") == "messages": # 3. ข้อมูล Message จะถูกเก็บอยู่ในคีย์ "data" ตำแหน่งที่ 0 message_chunk = chunk["data"][0] content = message_chunk.content
if content: data_to_send = {"token": content} yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
except Exception as e: yield f"data: {json.dumps({'error': str(e)}, ensure_ascii=False)}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
if __name__ == "__main__": # รัน FastAPI Server ด้วย uvicorn บน port 8000 uvicorn.run(app, host="0.0.0.0", port=8000)ผลลัพธ์ก็จะได้ออกมาเหมือนกับเวลาใช้งานผ่าน RemoteGraph ทั้งเคสของ invoke และ stream
ท่าที่ 2 - กับ LangGraph
import uvicornimport dotenvimport jsonfrom fastapi import FastAPIfrom pydantic import BaseModelfrom agentLangGraph import agentfrom fastapi.responses import StreamingResponse
dotenv.load_dotenv()
# 2. เริ่มต้นแอป FastAPIapp = FastAPI(title="Joke Agent REST API")
# กำหนด Schema สำหรับรับข้อมูลจากผู้ใช้ให้สอดคล้องกับ Agentclass JokeRequest(BaseModel): topic: str
# 3. สร้าง Endpoint สำหรับรับ Request และส่งคำตอบกลับแบบ REST API@app.post("/chat")async def chat_endpoint(request: JokeRequest): inputs = {"topic": request.topic}
response = await agent.ainvoke(inputs)
answer = response.get("final_joke") or response.get("joke", "")
return { "response": answer }
@app.post("/stream")async def stream_joke_api(request: JokeRequest): async def event_generator(): # 3. เปลี่ยน Input ให้ตรงกับ State Schema ของ Agent ตัวใหม่ (ส่งแค่ topic) inputs = {"topic": request.topic}
try: # 4. เรียกใช้ .astream() โดยขอข้อมูลทั้ง "messages" (ทีละคำ) และ "updates" (ตอนจบโหนด) [1] async for chunk in agent.astream( inputs, stream_mode=["messages", "updates"], version="v2" ): # กรณีที่ 1: ดักจับข้อมูล Stream แบบทีละคำ (Token) [2] if chunk.get("type") == "messages": # ผ่าน RemoteGraph ข้อมูล tuple จะถูกแปลงเป็น JSON list [message_chunk, metadata] message_chunk = chunk["data"][0] content = message_chunk.get("content", "")
if content: data_to_send = {"type": "token", "content": content} yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
# กรณีที่ 2: ดักจับข้อมูลตอนจบแต่ละ Node (Updates) elif chunk.get("type") == "updates": # ข้อมูลใน updates จะอยู่ในรูปแบบ { "ชื่อโหนด": { ข้อมูล State ที่อัปเดต } } for node_name, state in chunk["data"].items(): # ดึงข้อมูลตามโหนด เช่น โหนด write_joke จะได้คีย์ "joke", polish_joke จะได้ "final_joke" update_content = state.get("final_joke") or state.get("joke", "")
if update_content: data_to_send = { "type": "node_complete", "node": node_name, "content": update_content } yield f"data: {json.dumps(data_to_send, ensure_ascii=False)}\n\n"
except Exception as e: yield f"data: {json.dumps({'error': str(e)}, ensure_ascii=False)}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
if __name__ == "__main__": # สั่งรันเซิร์ฟเวอร์ด้วย Uvicorn ที่พอร์ต 8000 uvicorn.run(app, host="0.0.0.0", port=8000)ผลลัพธ์ก็จะได้ออกมาเหมือนกับเวลาใช้งานผ่าน RemoteGraph ทั้งเคสของ invoke และ stream
- รู้จักกับ Web Vitals guideline การสร้าง UX ที่ดีออกมากันมี Video
รู้จักกับคำศัพท์พื้นฐานของ Web Vitals และ use case ต่างๆของ Web Vitals กัน

- ทำไมถึงต้องใช้ Nuxt ทั้งๆที่มี Vue อยู่แล้ว ?มี Video
มาทำความรู้จัก Nuxt กันว่ามันคืออะไร มีความแตกต่างกับ Vue ยังไงบ้าง และเคสแบบไหนควรใช้ Nuxt บ้าง

-

- Rabbit MQ และการใช้ Message Queueมี Video
มาทำความรู้จักกับ Message Queue ว่ามันคืออะไร มีหลักการยังไงบ้าง และมาลองเล่นกันผ่าน software อย่าง RabbitMQ กัน
